![]()
Introduction to Xarray#
ESDS 2024 Annual Event Xarray-Dask Tutorial | January 19th, 2024
Negin Sobhani and Brian Vanderwende
Computational & Information Systems Lab (CISL)
negins@ucar.edu, vanderwb@ucar.edu
In this tutorial, you learn:#
What is Xarray?
The basic data structures in Xarray.
Read and write netCDF files using Xarray.
Basic computations with Xarray.
High-level computations with Xarray.
Xarray wrapping other array types.
Prerequisites#
Concepts |
Importance |
Notes |
|---|---|---|
Basic familiarity with NumPy |
Necessary |
|
Basic familiarity with Pandas |
Necessary |
|
Understanding of NetCDF |
Helpful |
Time to learn: 75 minutes
![]()
Introduction#
What is Xarray?#
Xarray is an open-source Python library designed for working with labelled multi-dimensional data.
By multi-dimensional data (also often called N-dimensional), we mean data that has many independent dimensions or axes (e.g. latitude, longitude, time).
By labelled we mean that these axes or dimensions are associated with coordinate names (like “latitude”) and coordinate labels like “30 degrees North”.
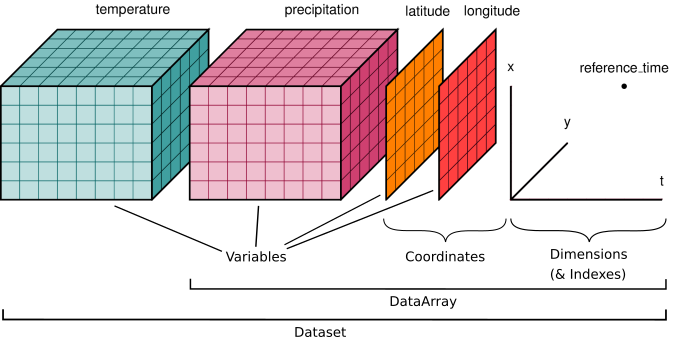
Image credit: Xarray Contributors
The diagram above shows an example of a labelled multi-dimensional data with two variables (temperature and precipitation) and three coordinate vectors (e.g., latitude, longitude, time) that describe the data.
Xarray Fundamental Data Structures#
Xarray has two fundamental data structures:
DataArray: holds a single multi-dimensional variable and its coordinates/metadataDataset: holds multiple DataArrays that potentially share the same coordinates
Xarray DataArray#
Xarray DataArray = data + (a lot of) metadata
A DataArray has four attributes:
Underlying Data or
data: a Numpy or Numpy-like array holding the values.Named Dimensions or
dims: dimension names for each axis (e.g.,latitude,longitude,time).Coordinate Variables or
coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings).Arbitrary attributes or
attrs: a dictionary to hold arbitrary metadata (attributes).
Xarray DataSet#
Xarray DataSet = multiple DataArrays
A DataSet is simply an object containing multiple Xarray DataArrays indexed by variable name that potentially share the same coordinates.
First let’s open a tutorial dataset and see what these data structures look like. Here we’ll use air temperature from the National Center for Environmental Prediction.
import xarray as xr
xr.set_options(display_expand_attrs=False, display_expand_data=False);
ds = xr.tutorial.load_dataset("air_temperature")
ds
<xarray.Dataset>
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 241.2 242.5 243.5 ... 296.5 296.2 295.7
Attributes: (5)Checkout the variables and coordinates of the dataset. You can also create a Data Array from the DataSet.
da = ds['air']
da
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> 241.2 242.5 243.5 244.0 244.1 243.9 ... 297.9 297.4 297.2 296.5 296.2 295.7 Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: (11)
What are the named dimensions of this Data Array?
da.dims
('time', 'lat', 'lon')
What are the coordinates of this Data Array?
da.coords
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
dims vs coords : A dimension is just a name of an axis (e.g., latitude, longitude, time). Coordinates are tick labels along each axis.
What are the attributes of this Data Array?
da.attrs
{'long_name': '4xDaily Air temperature at sigma level 995',
'units': 'degK',
'precision': 2,
'GRIB_id': 11,
'GRIB_name': 'TMP',
'var_desc': 'Air temperature',
'dataset': 'NMC Reanalysis',
'level_desc': 'Surface',
'statistic': 'Individual Obs',
'parent_stat': 'Other',
'actual_range': array([185.16, 322.1 ], dtype=float32)}
da.attrs["long_name"]
'4xDaily Air temperature at sigma level 995'
Xarray makes handling metadata and coordinates much easier for multi-dimensional arrays (for example climate dataset).
Reading and Writing Data with Xarray#
One of Xarray’s most widely used features is its ability to read from and write
to a variety of data formats.
For example, Xarray can read the following formats using open_dataset/open_mfdataset:
Support for additional formats is possible using external packages
GeoTIFF / GDAL rasters using the rioxarray package

NetCDF#
Xarray dataset is built upon the netCDF data model, which means that netCDF files stored on disk directly represent Dataset objects.
Xarray reads and writes to NetCDF files using the open_dataset /
open_mfdataset functions and the to_netcdf method, respectively.
Reading NetCDF file(s) with Xarray#
Xarray provides a function called open_dataset that allows us to load a netCDF dataset into a Xarray DataSet. To read more about this function, please see xarray open_dataset API documentation.
Xarray also provides open_mfdataset, which open multiple files as a single xarray DataSet. Passing the argument parallel=True will speed up reading multiple datasets by executing these tasks in parallel using Dask Delayed under the hood. We will learn more about this later in the tutorial.
In this example, we are going to look at near-surface air temperature (TREFHT) from CESM2 Large Ensemble Data Sets (LENS2).
To learn more about LENS2 dataset, please visit:
For this tutorial, we only look at a small subset of data. If you don’t have the data, running the following code enables you to download, prepare, and stage the required datasets (../data/ folder) for this notebook.
!./get_data.sh
mkdir: cannot create directory ‘../data’: File exists
import os
import glob
var = 'TREFHT'
# find all LENS files for 1 ensemble
data_dir = '../data/data_for_cesm'
files = sorted(glob.glob(os.path.join(data_dir, 'b.e21.BSSP370smbb.f09_g17.LE2-1301.013*.nc')))
print("All files: [", len(files), "files]")
All files: [ 9 files]
We can easily open all the above files in a DataSet using xr.open_mfdataset() which will use Dask and we will cover that later in the tutorial.
For now, let’s read one file to see what’s in it using open_dataset:
this_file = files[0]
print (this_file)
ds = xr.open_dataset(this_file)
ds
../data/data_for_cesm/b.e21.BSSP370smbb.f09_g17.LE2-1301.013.cam.h0.TREFHT.201501-202412.nc
<xarray.Dataset>
Dimensions: (lat: 192, zlon: 1, nbnd: 2, lon: 288, lev: 32, ilev: 33,
time: 120)
Coordinates:
* lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* zlon (zlon) float64 0.0
* lon (lon) float64 0.0 1.25 2.5 3.75 ... 355.0 356.2 357.5 358.8
* lev (lev) float64 3.643 7.595 14.36 24.61 ... 957.5 976.3 992.6
* ilev (ilev) float64 2.255 5.032 10.16 18.56 ... 967.5 985.1 1e+03
* time (time) object 2015-02-01 00:00:00 ... 2025-01-01 00:00:00
Dimensions without coordinates: nbnd
Data variables: (12/27)
zlon_bnds (zlon, nbnd) float64 ...
gw (lat) float64 ...
hyam (lev) float64 ...
hybm (lev) float64 ...
P0 float64 ...
hyai (ilev) float64 ...
... ...
n2ovmr (time) float64 ...
f11vmr (time) float64 ...
f12vmr (time) float64 ...
sol_tsi (time) float64 ...
nsteph (time) int32 ...
TREFHT (time, lat, lon) float32 ...
Attributes: (9)For this tutorial, we are looking at near-surface air temperature (TREFHT). This is a 3D variable, with dimensions of time, latitude, and longitude. Let’s look at the TREFHT variable representation in the dataset:
tref = ds.TREFHT
tref
<xarray.DataArray 'TREFHT' (time: 120, lat: 192, lon: 288)> [6635520 values with dtype=float32] Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2015-02-01 00:00:00 ... 2025-01-01 00:00:00 Attributes: (3)
# dimensions
tref.dims
('time', 'lat', 'lon')
#tref.coords
The attributes make it easy to work with the netCDF file metadata. For example what is the unit of the variable?
tref.attrs['units']
'K'
Underlying data#
.data contains the numpy array storing temperature values.
Xarray structures wrap underlying simpler array-like data structures. This part of Xarray is quite extensible allowing for different array types to be used. We will cover this later in the tutorial.
#tref.data
Xarray Indexing and Selecting Data#
Xarray supports different ways to index and select data. Xarray indexing is what makes it so powerful for data analysis tasks. 💪
In total, xarray supports four different kinds of indexing, as explained below and summarized in this table:
Dimension lookup |
Index lookup |
|
|
|---|---|---|---|
Positional |
By integer |
|
not available |
Positional |
By label |
|
not available |
By name |
By integer |
|
|
By name |
By label |
|
|
Positional indexing#
Xarray supports numpy-style positional indexing. For example, if we want to select the first element of the lat dimension, we can use the following syntax (0-based indexing similar to NumPy).
tref[:, 20, 0]
<xarray.DataArray 'TREFHT' (time: 120)>
[120 values with dtype=float32]
Coordinates:
lat float64 -71.15
lon float64 0.0
* time (time) object 2015-02-01 00:00:00 ... 2025-01-01 00:00:00
Attributes: (3)but wait, which dimension is the lat dimension? Is it (lat,lon,time) or (time,lon,lat) or (time, lat,lon)? Also what lat/lon value does the this correspond to?
Xarray offers extremely flexible indexing routines that makes it easy to select data based on dimension names and coordinates instead of axis indices.
Positional Indexing Using Dimension Names (.isel)#
Xarray eliminates much of the mental overhead of remembering dimension orders by allowing indexing using dimension names instead:
tref.isel(time=0).plot();
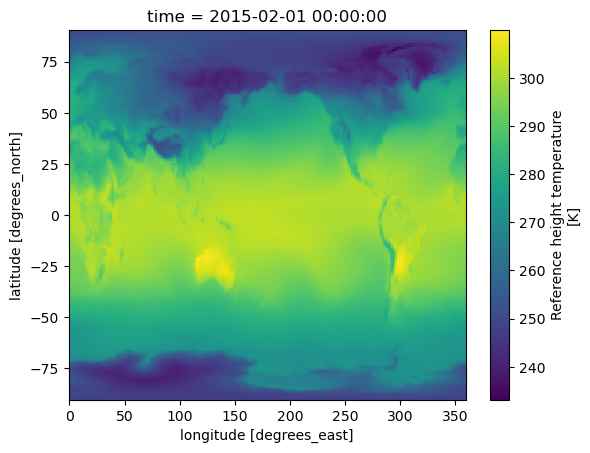
Slicing with labels is also possible. For example, we can plot the first 20 time steps of the variable:
tref.isel(time=slice(0, 20), lat=20, lon=40).plot();
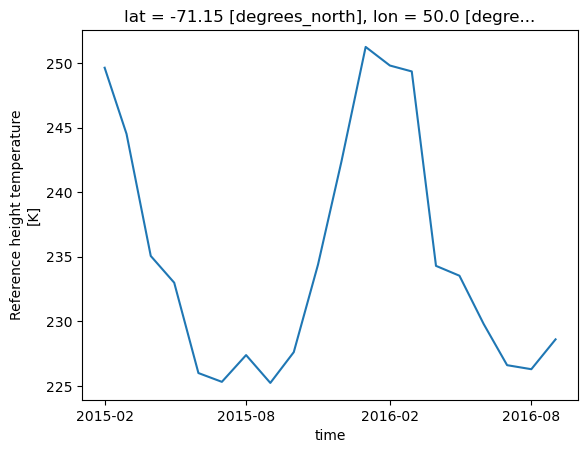
This is great! But it still requires you to know which index corresponds to your desired label. What if you don’t know the index of the label you want?
For example, what if you want to select the data for Lat 25 °N and Lon 210 °E, but you don’t know which index corresponds to this point.
Label-based Indexing Using Dimension Names (.sel)#
Xarray provides a more robust way to index data using dimension names and labels (instead of indices) using .sel method.
tref.sel(lat=90. , lon=140.).plot();
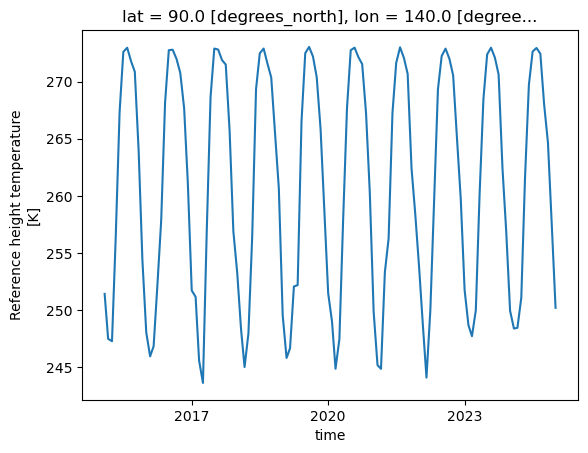
We can also do slicing using labels. For example:
da.sel(lat=slice(50, 25), lon=slice(210, 215))
<xarray.DataArray 'air' (time: 2920, lat: 11, lon: 3)> 279.5 280.1 280.6 279.4 280.3 281.3 ... 295.0 294.6 294.2 295.5 295.6 295.1 Coordinates: * lat (lat) float32 50.0 47.5 45.0 42.5 40.0 ... 35.0 32.5 30.0 27.5 25.0 * lon (lon) float32 210.0 212.5 215.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 Attributes: (11)
This is a very powerful feature of Xarray. It allows you to select data without having to remember the order of dimensions or the indices of labels. 💪 🎉
Nearest-neighbor lookups#
But what if that exact coordinate does not exist in my lat and lon coordinates?
The label based selection methods .sel() support method and tolerance keyword argument.
The method parameter allows for enabling nearest neighbor (inexact) lookups by use of the methods pad, backfill or nearest. The tolerance parameter allows for specifying a maximum distance for a valid match.
pad: propagate last valid index value forwardbackfill: propagate next valid index value backwardnearest: use nearest valid index value
For example let’s make a plot for NSF NCAR Mesa Lab. We can find it’s nearest point by using the method='nearest' argument.
#tref.sel(lat=40.0150, lon=-105.2705).plot();
tref.sel(lat=40.0150, lon=-105.2705, method='nearest').plot();
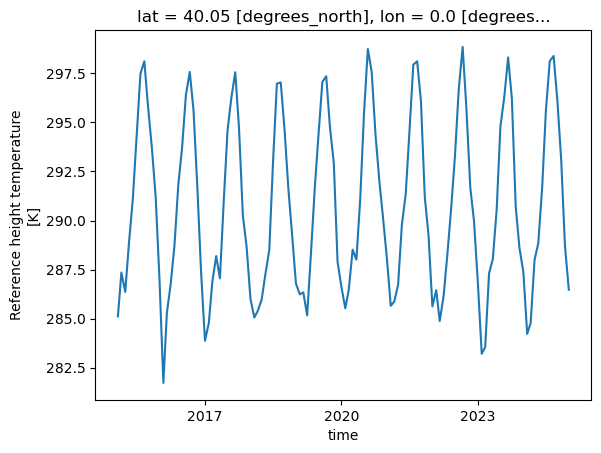
DateTime Indexing#
Datetime indexing is a critical feature when working with time series data. Essentially, datetime indexing allows you to select data points or a series of data points that correspond to certain date or time criteria.
tref.sel(time='2017-01-01').plot();
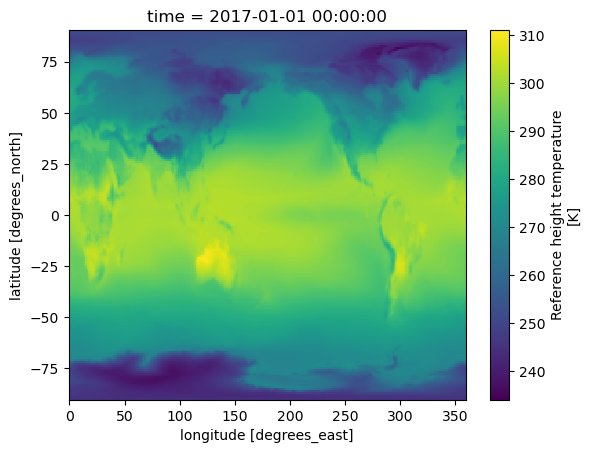
By default, datetime selection will return a range of values that match the provided string. We can use this feature to select all points in a year:
tref.sel(time="2024")
<xarray.DataArray 'TREFHT' (time: 12, lat: 192, lon: 288)> [663552 values with dtype=float32] Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2024-01-01 00:00:00 ... 2024-12-01 00:00:00 Attributes: (3)
Now, let’s say we want to select data between a certain range of dates. We can still use the .sel() method, but this time we will combine it with slice:
# This will return a subset of the dataset corresponding to specific dates
tref.sel(time=slice('2015-08-01', '2017-12-31'))
<xarray.DataArray 'TREFHT' (time: 29, lat: 192, lon: 288)> [1603584 values with dtype=float32] Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2015-08-01 00:00:00 ... 2017-12-01 00:00:00 Attributes: (3)
Fancy indexing based on year, month, day, or other datetime components#
In addition to the basic datetime indexing techniques, Xarray also supports “fancy” indexing options, which can provide more flexibility and efficiency in your data analysis tasks. You can directly access datetime components such as year, month, day, hour, etc. using the.dt accessor. Here is an example of selecting all data points from July across all years:
tref.sel(time=ds.time.dt.month == 7)
<xarray.DataArray 'TREFHT' (time: 10, lat: 192, lon: 288)> [552960 values with dtype=float32] Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2015-07-01 00:00:00 ... 2024-07-01 00:00:00 Attributes: (3)
Xarray powerful indexing features make it really powerfull for working with multi-dimensional data.
All of these indexing methods work on the dataset too!
Basic Computations with Xarray#
Xarray Data Arrays and Data Sets are compatible with arithmetic operators and numpy array functions.
For example, we can use the arithmetic operators +, -, *, /, ** to add, subtract, multiply, divide, and exponentiate two xarray objects with the same dimensions. Let’s convert the temperature values from Kelvin to Celsius by subtracting 273.15 from it:
# change the unit from Kelvin to degree Celsius
tref_c=tref-273.15
tref_c[0,:,:].plot();
# tref[0,:,:]-273.15).plot(); # this also works
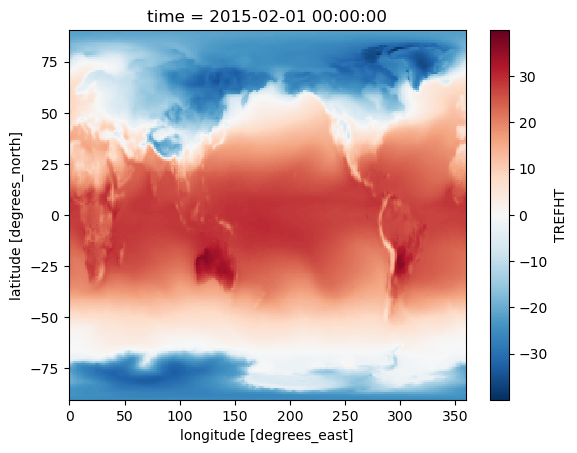
Aggregation or Reduction Operations#
Similar to NumPy, Xarray provides a set of basic statistical functions that operate on arrays. For example, we can compute the mean, standard deviation, variance, min, max, etc. of an xarray object.
For example, we can compute the mean of the temperature values over the time dimension:
mean_temp = tref.mean(dim="time")
mean_temp.plot();
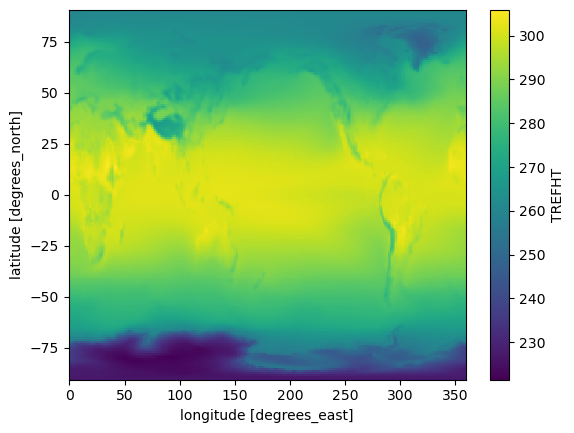
#std of all grids at every time step
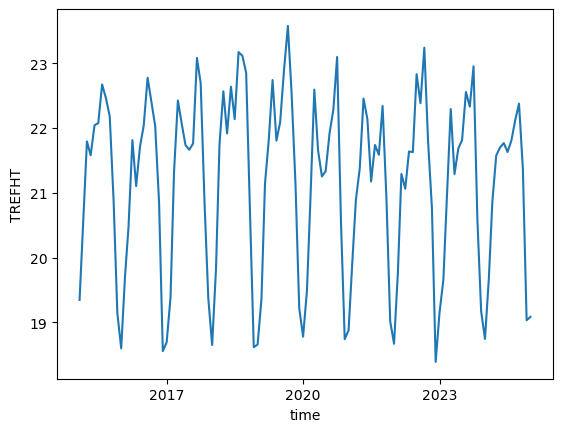
tref.std(dim=["lat", "lon"]).plot()
[<matplotlib.lines.Line2D at 0x1500fa531210>]
High level computation#
(groupby, resample, rolling, coarsen, weighted)
Xarray has some very useful high level objects that let you do common computations:
groupby: Bin data in to groups and reduceresample: Groupby specialized for time axes. Either downsample or upsample your data.rolling: Operate on rolling windows of your data e.g. running meancoarsen: Downsample your dataweighted: Weight your data before reducing
Below we quickly demonstrate these patterns. See the user guide links above and the tutorial for more.
groupby#
groupby is a powerful method that allows you to group DataArrays and DataSets by one or more dimensions. It is similar to the groupby method in Pandas.
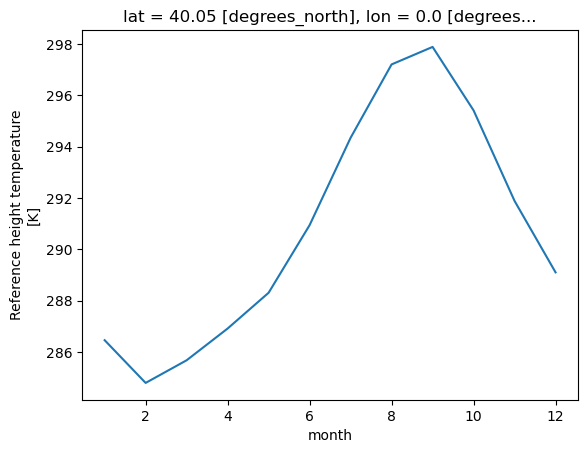
# calculate the monthly mean
monthly_mean = tref.groupby("time.month").mean()
monthly_mean.sel(lat=40.0150, lon=-105.2705, method='nearest').plot();
# make a seasonal mean
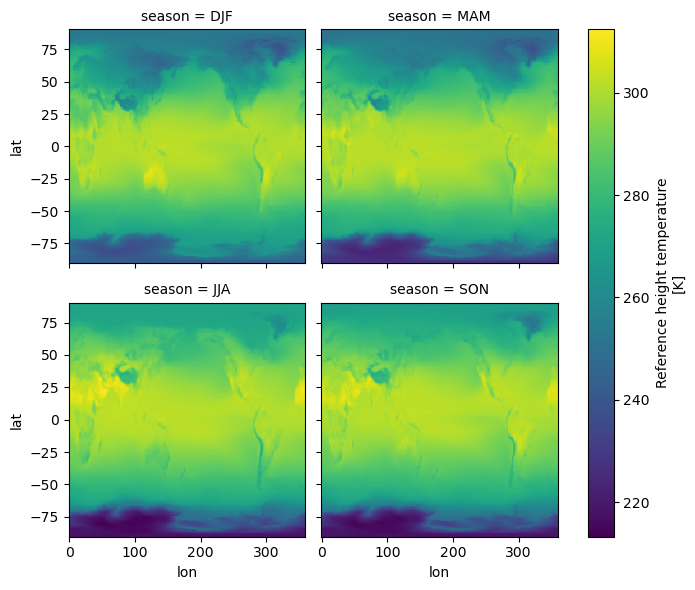
seasonal_mean = tref.groupby("time.season").mean()
seasonal_mean
<xarray.DataArray 'TREFHT' (season: 4, lat: 192, lon: 288)> 242.9 242.9 242.9 242.9 242.9 242.9 ... 269.1 269.1 269.1 269.1 269.1 269.1 Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * season (season) object 'DJF' 'JJA' 'MAM' 'SON' Attributes: (3)
seasonal_mean.plot(col="season");
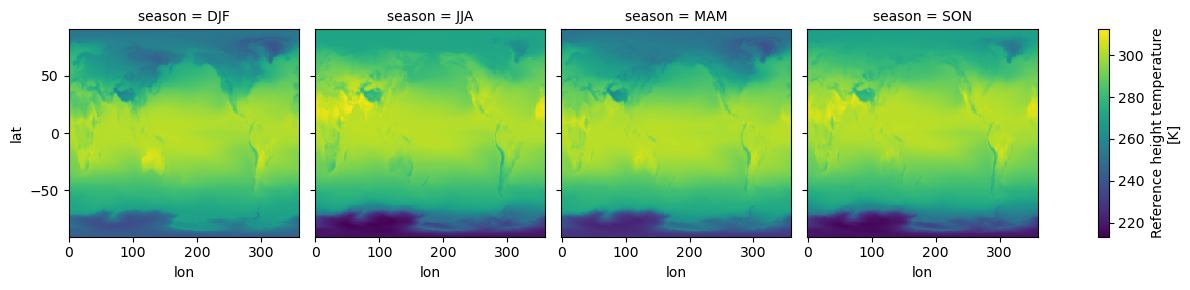
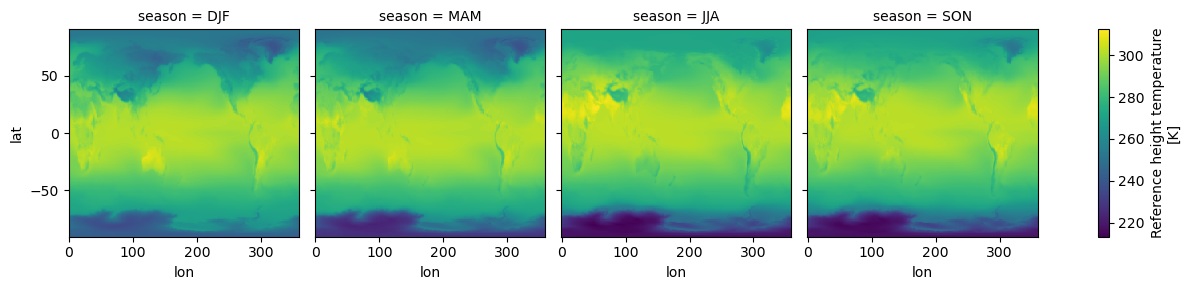
The seasons are out of order (they are alphabetically sorted). This is a common
annoyance. The solution is to use .sel to change the order of labels.
seasonal_mean = seasonal_mean.sel(season=["DJF", "MAM", "JJA", "SON"])
seasonal_mean.plot(col="season");
Resampling#
Resampling is a method for frequency conversion and downsampling of time-series data. Xarray provides a method called resample that allows you to resample time series data. resample can be applied only to time-index dimension. Please note that resampling change the length of the array.
# resample to 6-month frequency
tref_resample = tref.resample(time="6ME").mean()
tref_resample
<xarray.DataArray 'TREFHT' (time: 21, lat: 192, lon: 288)> 248.4 248.4 248.4 248.4 248.4 248.4 ... 262.6 262.6 262.6 262.6 262.6 262.6 Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2015-02-28 00:00:00 ... 2025-02-28 00:00:00 Attributes: (3)
Weighted#
Weighted array reductions in Xarray give users with the ability to perform aggregations on multidimensional arrays while assigning specific weights to each point. It currently support weighted sum, mean, std, var, and quantile.
For example, the weighted mean is another way to smooth data, taking into account the varying importance of each data point.
import numpy as np
#For a rectangular grid the cosine of the latitude is proportional to the grid cell area.
weights = np.cos(np.deg2rad(tref.lat))
weights.name = "weights"
#weights.plot()
# calculate weighted means
weighted_mean=tref_c.weighted(weights).mean(["lat", "lon"])
weighted_mean.plot(label="weighted", color='r'); # -- this one is weighted towards equator values
tref_c.mean(["lat", "lon"]).plot(label="unweighted", color = 'b');
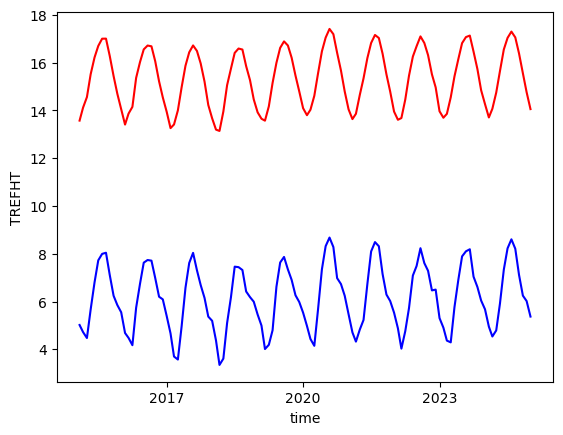
Similarly we can calculate weighted sum or weighted quantile, etc. To learn more about weighted array reduction, please see the user guide.
Rolling#
Xarray provides a method called rolling that allows you to perform rolling window operations on your data. Rolling window operations can be applied along one or more dimensions of an xarray object.
For example, you can calculate the rolling mean of a time series to smooth out short-term fluctuations and highlight long-term trends. rolling does not change the length of the arrays. Instead, it allows a moving window to be applied to the data at each point.
tref_rolling = tref.rolling(time=6, center=True).mean()
tref.shape, tref_rolling.shape
((120, 192, 288), (120, 192, 288))
tref.sel(lon=150, lat=50, method='nearest').plot(label='monthly mean')
tref_rolling.sel(lon=150, lat=50, method='nearest').plot( label='6 month rolling mean', color='r')
[<matplotlib.lines.Line2D at 0x1500ebb8bcd0>]
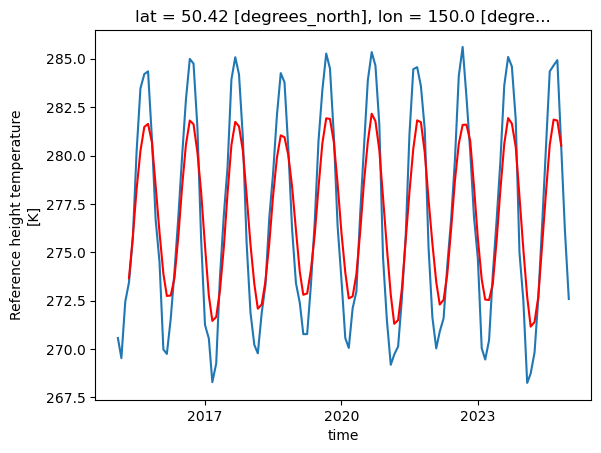
Coarsen#
In Xarray, the coarsen operation is a powerful tool for downsampling or reducing the size of large arrays. When dealing with large datasets, coarsening allows for efficient summarization of data by aggregating multiple values into a single value within a defined coarsening window. This process is particularly useful when working with high-resolution or fine-grained data, as it enables the transformation of large arrays into smaller ones while preserving the overall structure and key characteristics of the data. coarsen is similar to resample when operating on time series data, but it can be applied to any dimension.
In order to take a block mean for every 5 lat and lon points we can use the following:
coarsen_da = tref.coarsen(lat=10, lon=10, boundary='pad').mean()
coarsen_da.isel(time=0).plot();
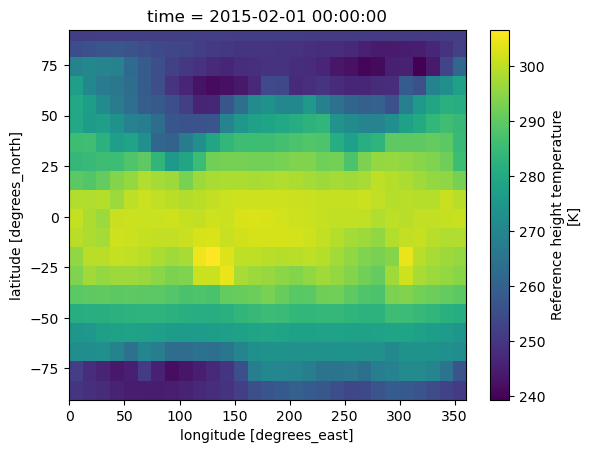
tref.isel(time=0).plot();
Visualization (.plot)#
We have seen very simple plots earlier. Xarray also lets you easily visualize 3D and 4D datasets by presenting multiple facets (or panels or subplots) showing variations across rows and/or columns.
# facet the seasonal_mean
seasonal_mean.plot(col="season", col_wrap=2);
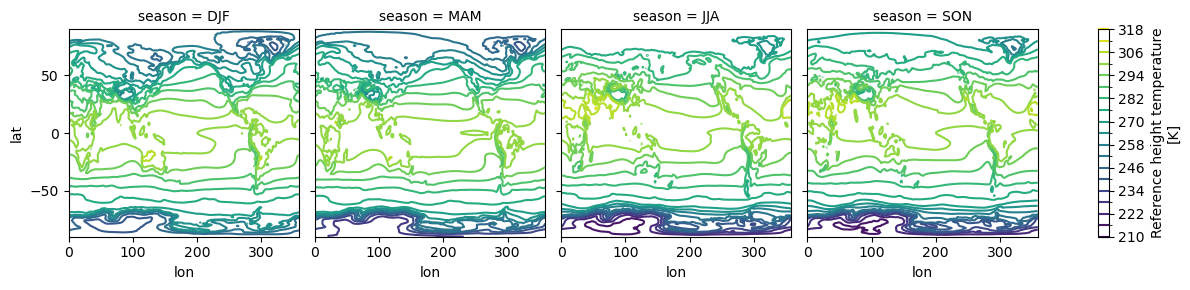
# contours
seasonal_mean.plot.contour(col="season", levels=20, add_colorbar=True);
# cool line plots too? wut !
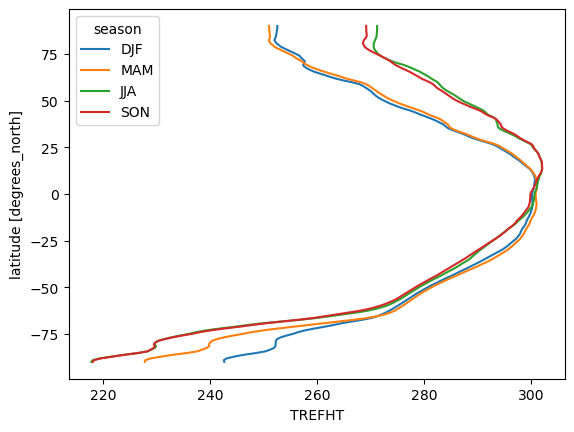
seasonal_mean.mean("lon").plot.line(hue="season", y="lat");
Computing with Multiple Objects#
Broadcasting: adjusting arrays to the same shape#
Broadcasting in Xarray refers to the automatic alignment and expansion of arrays to perform operations on arrays with different shapes and dimensions. It is a powerful feature that allows for efficient and convenient computations in Xarray. Broadcasting basically allows an operator or a function to act on two or more arrays to operate even if these arrays do not have the same shape. Xarray does broadcasting by dimension name, rather than array shape.
import numpy as np
array1 = xr.DataArray(
np.arange(3),
dims="space",
coords={"space": ["a", "b", "c"]},
name="array1",
)
array1
<xarray.DataArray 'array1' (space: 3)> 0 1 2 Coordinates: * space (space) <U1 'a' 'b' 'c'
array2 = xr.DataArray(
np.arange(4),
dims="time",
coords={"time": [0, 1, 2, 3]},
name="array2",
)
array2
<xarray.DataArray 'array2' (time: 4)> 0 1 2 3 Coordinates: * time (time) int64 0 1 2 3
Let’s add this two:
x= array1-array2
x
<xarray.DataArray (space: 3, time: 4)> 0 -1 -2 -3 1 0 -1 -2 2 1 0 -1 Coordinates: * space (space) <U1 'a' 'b' 'c' * time (time) int64 0 1 2 3
We see that the result is a 2D array.
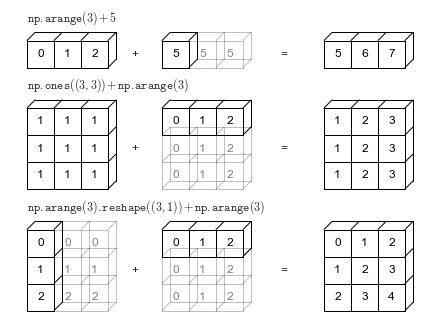
When subtracting, Xarray first realizes that array1 is missing the dimension time and array2 is missing the dimension space. Xarray then broadcasts or “expands” both arrays to 2D with dimensions space, time.
See the last row in this image from Jake VanderPlas Python Data Science Handbook
x.data
array([[ 0, -1, -2, -3],
[ 1, 0, -1, -2],
[ 2, 1, 0, -1]])
Broadcasting in xarray simplifies the process of working with arrays of different shapes, as it automatically handles the alignment and expansion required for performing computations. It reduces the need for manual reshaping or padding of arrays, making the code more concise and readable. When doing certain computations on two arrays (additions), Xarray automatically broadcast the arrays to match the dimension shapes. To learn more about xarray.broadcast , you can check the user guide.
If you encounter additional NaN values or missing data points after performing computations in xarray, it indicates that the coordinates of your xarray were not precisely aligned.
array1_broadcasted, array2_broadcasted = xr.broadcast(array1, array2)
display(array1_broadcasted.dims)
display(array2_broadcasted.dims)
('space', 'time')
('space', 'time')
array1_broadcasted.data
array([[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2]])
array2_broadcasted.data
array([[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3]])
Alignment : Putting Data on the same grid#
Alignment in xarray refers to the process of automatically aligning multiple DataArrays or Datasets based on their coordinates. For example, when combing two arrays using an arithmetic operation, both arrays must first be converted to the same coordinate system.
Alignment ensures that the data along these coordinates is properly aligned before performing operations or calculations. This alignment is crucial because it enables xarray to handle operations on arrays with different sizes, shapes, and dimensions.
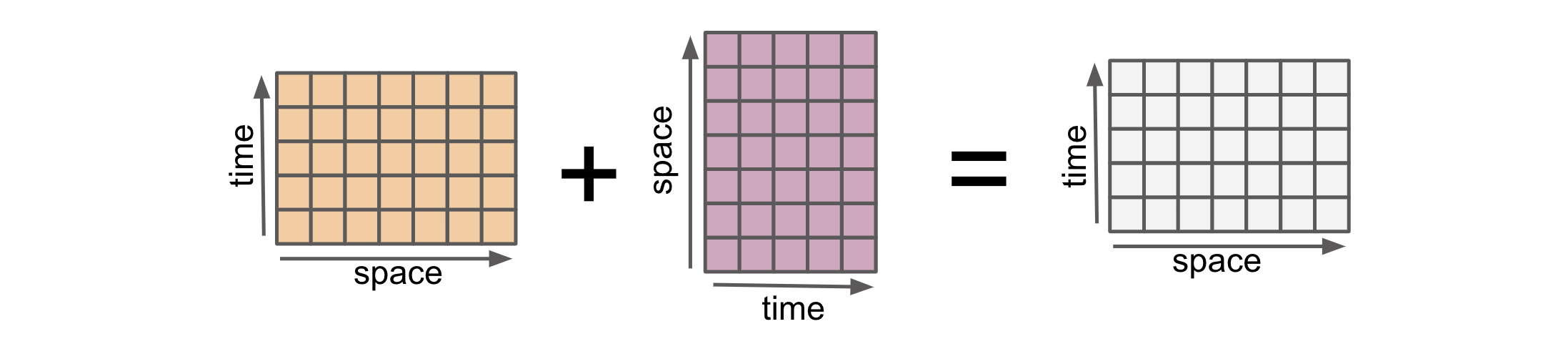
Here are two 2D DataArrays with different shapes.
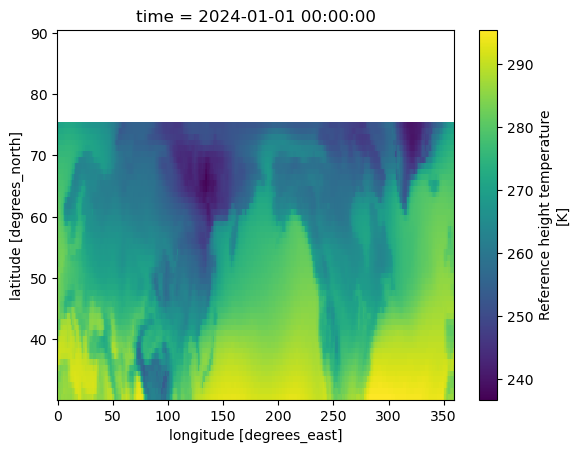
tref_mid = tref.sel(time = "2024-01", lat=slice(30,75))# 48 point
tref_high = tref.sel(time = "2024-01", lat=slice(75,90)) # 16 points
tref_mid.shape, tref_high.shape
((1, 48, 288), (1, 16, 288))
tref_mid and tref_high have the same dimensions (space, time) but have values at different locations in the (space, time) plane with some locations in common.
tref_mid_outer, tref_high_outer = xr.align(tref_mid, tref_high, join='outer')
tref_mid_outer.plot()
<matplotlib.collections.QuadMesh at 0x1500f8fd1290>
Boolean indexing & masking#
Boolean masking, known as boolean indexing, is a functionality in Python that enables the filtering of values based on a specific condition.
A boolean mask refers to a binary array or a boolean-valued (True/False) array that is used as a filter to select specific elements from another array. The boolean mask acts as a criterion or condition, where each element in the mask corresponds to an element in the target array. An element in the target array is selected when the corresponding mask value is True.
Masking with where()#
Indexing methods on Xarray objects generally return a subset of the original data. However, it is sometimes useful to select an object with the same shape as the original data, but with some elements masked.
By applying .where(), the original data’s shape is maintained, with values masked based on a Boolean condition. Values that satisfy the condition (True) are returned unchanged, while values that do not meet the condition (False) are replaced with a predefined value.
# plot mean July temperature
t_july = tref_c.sel(time=ds.time.dt.month == 7).mean(dim="time")
## mask out below 0 C temperatures
t_masked = t_july.where(t_july > 0)
t_masked.shape, t_july.shape
((192, 288), (192, 288))
By default Xarray set the masked values to nan. But as we saw in the first example, we can set it to other values too.
## mask out below 0 C temperatures with 0
t_fillmasked = t_july.where(t_july > 0, 0)
As you can see, in the example above .where() preserved the shape of the original data by masking the values with a boolean condition.
where is performing broadcasting, which is why the shape of the original data is preserved.
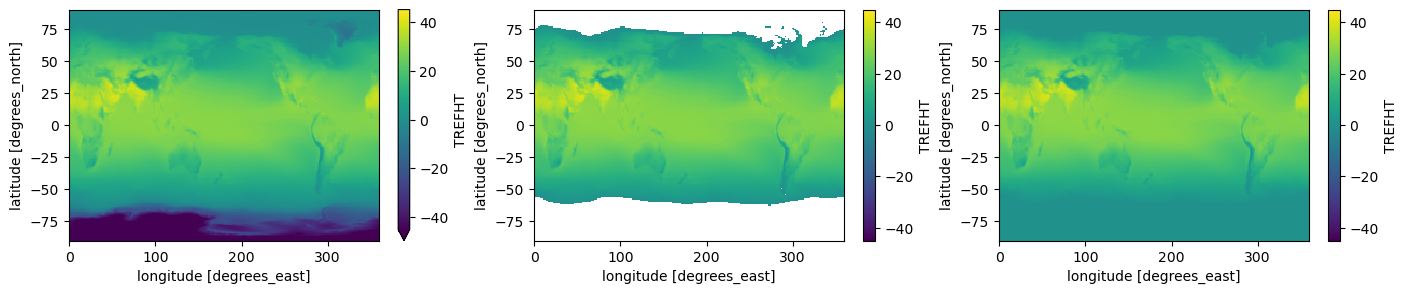
from matplotlib import pyplot as plt
# -- making both plots for comparison:
fig, axes = plt.subplots(ncols=3, figsize=(17, 3))
# -- for reference (without masking):
t_july.plot(ax=axes[0],vmin = -45, vmax=45); # cmap = viridis
# -- masked DataArray
t_masked.plot(ax=axes[1], vmin= -45, vmax=45);
# -- masked DataArray with filled values
t_fillmasked.plot(ax=axes[2], vmin= -45, vmax=45);
Xarray can wrap many NumPy-like arrays#
This notebook has focused on Numpy arrays. Xarray can wrap other array types! For example:
 distributed parallel arrays & Xarray user guide on Dask
distributed parallel arrays & Xarray user guide on Dask
![]() pydata/sparse : sparse arrays
pydata/sparse : sparse arrays
![]() pint : unit-aware arrays & pint-xarray
pint : unit-aware arrays & pint-xarray
We will learn more about Xarray wrapping Dask arrays in the next section.
Here is a quick intro:
Xarray also provides open_mfdataset, which open multiple files as a single xarray dataset using Dask Arrays (instead of NumPy arrays). Passing the argument parallel=True will speed up reading multiple datasets by executing these tasks in parallel using Dask Delayed under the hood. This is especially helpful when the data does not fit into memory.
#Let's check what is our DataArray type has been so far
type(tref.data)
numpy.ndarray
%%time
ds = xr.open_mfdataset(
sorted(files),
# concatenate along this dimension
concat_dim="time",
# concatenate files in the order provided
combine="nested",
# parallelize the reading of individual files using dask
# This means the returned arrays will be dask arrays
parallel=True,
# these are netCDF4 files, use the h5netcdf package to read them
engine="h5netcdf",
# hold off on decoding time
decode_cf=False,
# specify that data should be automatically chunked
chunks="auto",
)
ds = xr.decode_cf(ds)
tref_all = ds.TREFHT
tref_all
CPU times: user 1.8 s, sys: 31.5 ms, total: 1.83 s
Wall time: 1.95 s
<xarray.DataArray 'TREFHT' (time: 1032, lat: 192, lon: 288)> dask.array<chunksize=(120, 192, 288), meta=np.ndarray> Coordinates: * lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 87.17 88.12 89.06 90.0 * lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8 * time (time) object 2015-02-01 00:00:00 ... 2101-01-01 00:00:00 Attributes: (3)
type(tref_all.data)
dask.array.core.Array
Supplementary Material: Advanced using apply_ufunc#
Sometimes, we want calculate a function that is not built-in to Xarray. For example, we may want to calculate the saturation vapor pressure.
xr.apply_ufunc() give users capability to run custom-written functions.
Xarray, itself, use apply_ufunc() to implement many of its built-in functions. For example, this includes most of SciPy’s API implementation in Xarray.
In the example below, we calculate the saturation vapor pressure by using apply_ufunc() to apply this function to our Dask Array chunk by chunk.
import numpy as np
def sat_p(t):
"""Calculate saturation vapor pressure using Clausius-Clapeyron equation"""
return 0.611 * np.exp(17.67 * (t-273.15)*((t-29.65)**(-1)))
es = xr.apply_ufunc(sat_p, da, output_dtypes=[float])
es
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> 0.04237 0.04797 0.05273 0.05526 0.05578 0.0547 ... 3.026 2.989 2.866 2.814 2.73 Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
The data used for this tutorial is from one ensemble member. What if we want to use multiple ensemble members? So far, we only run on one machine, what if we run an HPC cluster? We will go over this in the next tutorial.
Summary#
In this notebook, we have learned about:
Xarray data structures:
DataArrayandDatasetIndexing and selecting data
Reading and writing data with Xarray
Basic computations with Xarray
Broadcasting and alignment
Customized workflows using
apply_ufunc