Brian Bonnlander (Jun 24 2021 at 19:25): Brian Bonnlander (Jun 24 2021 at 19:25):
Brian Bonnlander (Jun 24 2021 at 19:25): Brian Bonnlander (Jun 24 2021 at 19:25):Sorry if this isn't the best forum to ask this question, but is anyone aware of code examples that plot the various land model plant types, such as deciduous forests, etc from the CLM model? It appears there is a fairly complicated sparse indexing scheme used to store these types in NetCDF, and I'm trying to figure out how this scheme works.
Background description: https://www.cesm.ucar.edu/models/clm/surface.heterogeneity.html
Example NetCDF file: /glade/scratch/bonnland/DART/ds345.0/lnd/0001/f.e21.FHIST_BGC.f09_025.CAM6assim.011.clm2_0001.h1.2015.nc
Variables using this scheme include: GPP, GRAINC_TO_FOOD, GSSHALN, GSSUNLN, NPP, NPP_NUPTAKE, PLANT_NDEMAND, QVEGT, TLAI
Thanks for any advice!
Katie Dagon (Jun 24 2021 at 22:33):It appears there is a fairly complicated sparse indexing scheme used to store these types in NetCDF, and I'm trying to figure out how this scheme works.
yeah this is definitely a thing! @Danica Lombardozzi or @Will Wieder might have some code examples in python. Here is Danica's example notebook from the ctsm-py repo:
https://github.com/NCAR/ctsm_python_gallery/blob/master/notebooks/PFT-Gridding.ipynb
Max Grover (Jun 24 2021 at 22:35):I think @Zhonghua Zheng had a similar question last week?
Brian Bonnlander (Jun 29 2021 at 21:30):Hi again, I have more questions about how to interpret PFT-related variables in the CLM history files.
I'm looking at this file, for example:
/glade/scratch/bonnland/temp/lnd/0001/f.e21.FHIST_BGC.f09_025.CAM6assim.011.clm2_0001.h1.2011.nc
In it, there is the variable TLAI(time, pft). I was originally thinking that the pft dimension can be expanded from 1D to 3D by mapping to the dimensions (lat, lon, veg_type), but it appears that this mapping is not enough: there are many cases where the same (lat, lon, veg_type) index values. appear more than once. For example, in the file above:
pfts1d_lat are 83.403145pfts1d_lon are 335.0pfts1d_itype_veg are 0Is there some other dimension needed to keep these indexes from referring to the same (lat, lon, veg_type) combination more than once? Or should these be viewed as duplicate values that can be removed?
Thanks for any insights!
Katie Dagon (Jun 30 2021 at 16:41):Tagging @Daniel Kennedy as well here for any relevant code examples of PFT regridding in python
Danica Lombardozzi (Jul 02 2021 at 21:05):Hi @Brian Bonnlander : Did you look at my script that Katie pointed you to earlier (here for reference: https://github.com/NCAR/ctsm_python_gallery/blob/master/notebooks/PFT-Gridding.ipynb)?
The relevant line of code for what you're trying to do is in cell 15 (look for 'Creating gridded array' in the text). I'm happy to talk more if you'd like
Brian Bonnlander (Jul 02 2021 at 21:25):Hi Danica! This is embarrassing but I keep hitting a key by accident that erases my reply; I've written it twice now! So I'm going to write a bunch of smaller parts, which should end with a question.
Brian Bonnlander (Jul 02 2021 at 21:29):I found your notebook very helpful, I was getting nowhere until I got to look at it.
I'm looking into whether the PFT-related data can be organized in Zarr format, where we have the ability to organize the data by (lat, lon, vegtype) for example. If we do that, then someone interested in just evergreen forests in North America can load 1% of the data they otherwise need to with the data as it is organized now. It can be expensive, resource-wise, to load all available data and then throw away 99% of it to get the subset you're interested in.
Brian Bonnlander (Jul 02 2021 at 21:31):But when I tried doing this, I discovered that there are many elements along the pft dimension in the original data with the same (lat, lon, vegtype) combination. This prevents the data from being reorganized along just these three dimensions.
Brian Bonnlander (Jul 02 2021 at 21:33):To reorganize the data, each element along the pft dimension needs its own unique combination of indexed values. What I've discovered is that every element does have a unique combination of (lat, lon, vegtype, coltype, lunittype, active). These are other potential dimensions available in the NetCDF files I am using.
Brian Bonnlander (Jul 02 2021 at 21:35):I think my question(s) are "Does what I'm saying make any sense based on your understanding of the data?" and "Is it possible I've added too many dimensions?" If what I'm saying isn't clear, I'm happy to explain more.
Danica Lombardozzi (Jul 02 2021 at 22:30):To be totally honest, the PFT-level data has always confused me! We may have to iterate on this a few times. I agree that this is a resource-intensive process, and I will be super excited if you figure out a way to pull just the PFTs of interest. This will be particularly helpful for LENS2 analysis!
The data from CLM can be a little confusing, but you may be on the right track. One upfront question: are all the duplicates 0, like in the example you shared?
Historically, all PFTs were on the same column, but this changed when we added crops. With the active crop model, each crop has its own soil column. I am surprised that the indices appear more than once, however. Even though different plant types may be on different soil columns, I don't think that any should be specified twice in a grid cell.
Have you looked at whether (lat, lon, vegtype, coltype) has duplicates? I ask because I wouldn't expect lunittype (land unit type) to be important in this context, because all the plants should be on the vegetated land unit (others include glacier, lake, etc). The 'active' variable is probably related to whether the crop type is active or not (even though we have 64 crop PFTs on the file, only 16 are actually simulated), so I wouldn't expect that to matter either.
I wonder if it's worth comparing the processing of a full dataset (similar to my script) and then data processing using your method, ignoring duplicate values. It may give us a better sense for whether the duplicates matter, especially if they are 0 values.
Brian Bonnlander (Jul 02 2021 at 22:32):Excellent info, thank you! I will try to find out the answers to your questions, but it may be next week!
Brian Bonnlander (Jul 02 2021 at 22:48):Thinking more about your answer, is it possibly a good idea to remove all points that are not marked as active? Could you imagine anyone wanting to look at values where active = 0? Maybe these are also zero for non-crop vegtypes, however, in which case we want to keep them?
Brian Bonnlander (Jul 02 2021 at 22:52):I do remember that when I tried using just the (lat, lon, vegtype) dimensions, there were around 65,000 elements in the pft dimension (~800,000 total elements for that dimension) that were marked as having non-unique index values. But I don't know what the coltype values were for those points. I will see if I can figure that out soon.
Danica Lombardozzi (Jul 02 2021 at 22:56):I'm not entirely sure about active. I can't think of a reason where people would want to use an inactive PFT, but that doesn't mean they don't exist! The inactive PFTs get merged into the active crop types, so I don't think there would be any useful information for the inactive PFTs.
Deepak Cherian (Jul 06 2021 at 20:08):Brian, The notebook that @Danica Lombardozzi pointed to has 1D indexes pfts1d_ixy and pfts1d_jxy. If your dataset has that too, you can use that directly in the sparse.COO constructor and avoid all the expense in create the MultiIndex.
Brian Bonnlander (Jul 06 2021 at 20:15):Yes, I have those too, and I will give that a try, thank you! Eventually I hope the points can be indexed by lat/lon instead of array indexes, but perhaps this can be accomplished easily at a later step.
Deepak Cherian (Jul 06 2021 at 20:22):hmmm.. there's some misconception here. Let me write up an example
Brian Bonnlander (Jul 06 2021 at 20:56):I appreciate that! From looking at the sparse docs, it appears that simple indexing is supported, and xarray would have to provide the coordinate index mapping if you wanted to store the variable as TLAI(lat, lon, vegtype) for example. It seems possible in principle, since there is a 1:1 relationship between sparse array indexes and lat/lon coordinate indexes (at least for gridded data).
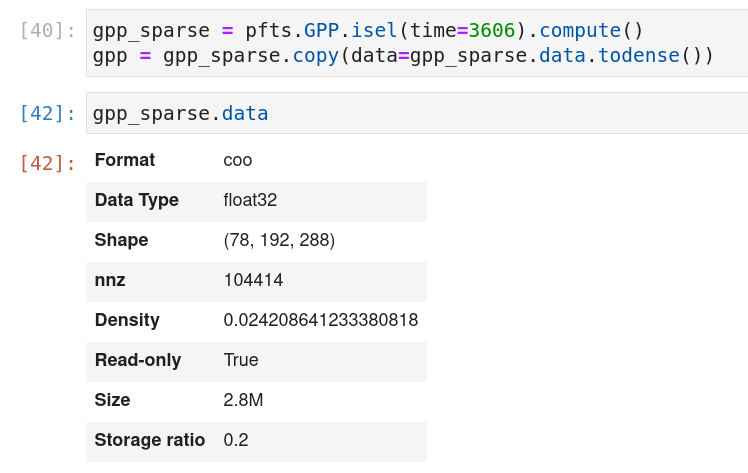
Deepak Cherian (Jul 06 2021 at 21:58):Done. https://github.com/NCAR/ctsm_python_gallery/pull/36
Deepak Cherian (Jul 06 2021 at 21:59):(the dask repr is wrong, it still think its a numpy array but if you compute you get a sparse array; I havent updated dask in a while :slight_smile:)
Brian Bonnlander (Jul 06 2021 at 22:11):Wow! Great stuff in that notebook! I have to try soon and see whether it can be saved to Zarr, unless you're fairly confident that sparse arrays like these are supported by Zarr. I really appreciate your work on this! It should help the wider community have access to these interesting variables.
Deepak Cherian (Jul 06 2021 at 22:14):fairly certain you can't write sparse directly to zarr. I bet this is more useful as a utility function that is applied after a dataset is read
Brian Bonnlander (Jul 06 2021 at 22:17):OK, but if the entire variable needs to be processed this way each time, it makes the memory requirements much higher than it otherwise would need to be.
Deepak Cherian (Jul 06 2021 at 22:24):it's parallelized using dask so it's just an extra compute step with much lower memory usage: pasted image
Brian Bonnlander (Jul 06 2021 at 22:27):Yes, I meant something different. I am imagining that analysis will rarely involve the full data, so if we could arrange the data on disk in useful slices, then there is potentially some real savings in core hours and/or memory in the long run.
Deepak Cherian (Jul 06 2021 at 23:04):Ah I see. Another way would be to chunk along pft before unstacking it which would require some interesting logic =)
Brian Bonnlander (Jul 06 2021 at 23:26):It might not be bad, not sure about this but sparse arrays can be combined by summing them together if the points in the two sparse arrays are disjoint, as they are in this case. It just might work...
Last updated: May 16 2025 at 17:14 UTC