Data Access¶
import warnings
warnings.filterwarnings("ignore")
import intake
import numpy as np
import pandas as pd
import xarray as xr
import seaborn as sns
import matplotlib.pyplot as plt
import os
import uxarrayLoading...
import dask
from dask_jobqueue import PBSCluster
from dask.distributed import Client
from dask.distributed import performance_report# cat_url = '/gdex/data/d616000/catalogs/d616000_catalog.json' #POSIX access on NCAR
# print(cat_url)/glade/campaign/collections/rda/data/d616000/catalogs/d616000_catalog.json
# Get your scratch folder
scratch = os.environ.get("SCRATCH") or getuser()
print(scratch)/glade/derecho/scratch/harshah
Create a PBS cluster¶
# Create a PBS cluster object
cluster = PBSCluster(
job_name = 'wcrp-hackathon25',
account= 'UCIS0005',
cores = 1,
memory = '10GiB',
processes = 1,
local_directory = scratch,
log_directory = scratch,
resource_spec = 'select=1:ncpus=1:mem=10GB',
queue = 'casper',
walltime = '5:00:00',
interface = 'ext'
)
client = Client(cluster)# Scale the cluster and display cluster dashboard URL
n_workers = 5
cluster.scale(n_workers)
client.wait_for_workers(n_workers = n_workers)
clusterLoading...
Load ... data and open with uxarray¶
cat_url = "https://digital-earths-global-hackathon.github.io/catalog/catalog.yaml"
cat_master = intake.open_catalog(cat_url)
cat_masterLoading...
# Hackathon data catalogs
cat_url = "https://digital-earths-global-hackathon.github.io/catalog/catalog.yaml"
cat = intake.open_catalog(cat_url).NCAR
# model_run = cat.icon_ngc4008
catLoading...
catLoading...
list(cat)['CERES_EBAF',
'ERA5',
'IR_IMERG',
'JRA3Q',
'MERRA2',
'arp-gem-1p3km',
'arp-gem-2p6km',
'casesm2_10km_nocumulus',
'ew_dyamond3_2D',
'icon_d3hp003',
'icon_d3hp003aug',
'icon_d3hp003feb',
'icon_ngc4008',
'ifs_tco3999-ng5_deepoff',
'ifs_tco3999-ng5_rcbmf',
'ifs_tco3999-ng5_rcbmf_cf',
'ifs_tco3999_rcbmf',
'mpas_dyamond1',
'mpas_dyamond2',
'mpas_dyamond3',
'nicam_220m_test',
'nicam_gl11',
'scream-dkrz',
'scream2D_hrly',
'scream_lnd',
'scream_ne120',
'tracking-d3hp003',
'um_Africa_km4p4_RAL3P3_n1280_GAL9_nest',
'um_CTC_km4p4_RAL3P3_n1280_GAL9_nest',
'um_SAmer_km4p4_RAL3P3_n1280_GAL9_nest',
'um_SEA_km4p4_RAL3P3_n1280_GAL9_nest',
'um_glm_n1280_CoMA9_TBv1p2',
'um_glm_n1280_GAL9',
'um_glm_n2560_RAL3p3',
'wrf_conus',
'wrf_samerica']- col.df turns the catalog object into a pandas dataframe!
- (Actually, it accesses the dataframe attribute of the catalog)
Select data and plot¶
What if you don’t know the variable names ?¶
- Use pandas logic to print out the short_name and long_name
- We notice that long_name is not available for some variables like ‘V’
- In such cases, please look at the dataset documentation for additional information: https://
gdex .ucar .edu /datasets /d616000 /documentation /#
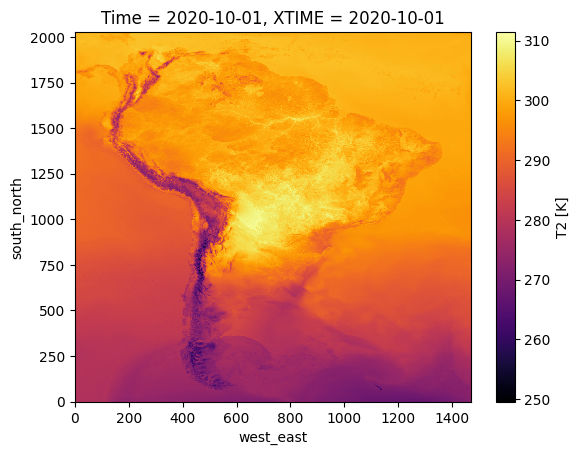
Temperature¶
- Plot temperature for a random date
- The data is organized in (virtual) zarr stores with one year’s worth of data in one file
- Select a year. This is done by selcting the start time to be Jan 1st of that year or the end time to be Dec 31st of the same year
- This also means that if you want to request data for other days, say Oct 1 for the year YYYY, you first have to load the data for one year YYYY and then select the data for that particular day. This example is discussed below.
Load data into xarray¶
# Load catalog entries for subset into a dictionary of xarray datasets, and open the first one.
dsets = cat_temp_subset.to_dataset_dict(zarr_kwargs={"consolidated": True})
print(f"\nDataset dictionary keys:\n {dsets.keys()}")Loading...
# Load the first dataset and display a summary.
dataset_key = list(dsets.keys())[0]
# store_name = dataset_key + ".zarr"
print(dsets.keys())
ds = dsets[dataset_key]
ds = ds.T2
dsLoading...
%%time
desired_date = "2020-10-01"
ds_subset = ds.sel(Time=desired_date,method='nearest')
ds_subsetLoading...
%%time
ds_subset.plot(cmap='inferno')CPU times: user 23.8 s, sys: 17.5 s, total: 41.3 s
Wall time: 3min 14s
cluster.close()