Muntaha Pasha (Mar 29 2021 at 20:28): Muntaha Pasha (Mar 29 2021 at 20:28):
Muntaha Pasha (Mar 29 2021 at 20:28): Muntaha Pasha (Mar 29 2021 at 20:28):Data.PNG Sample.PNG
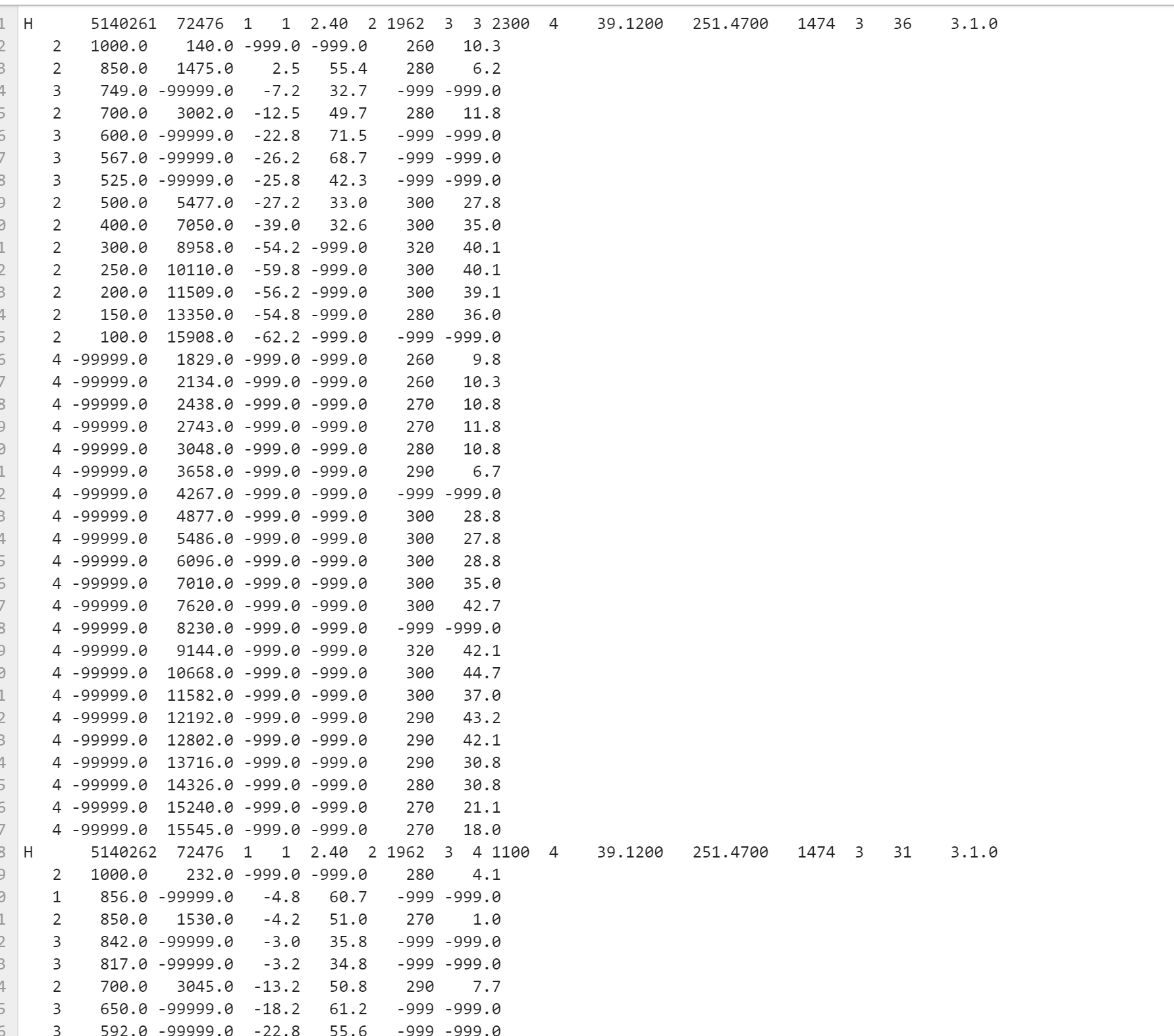
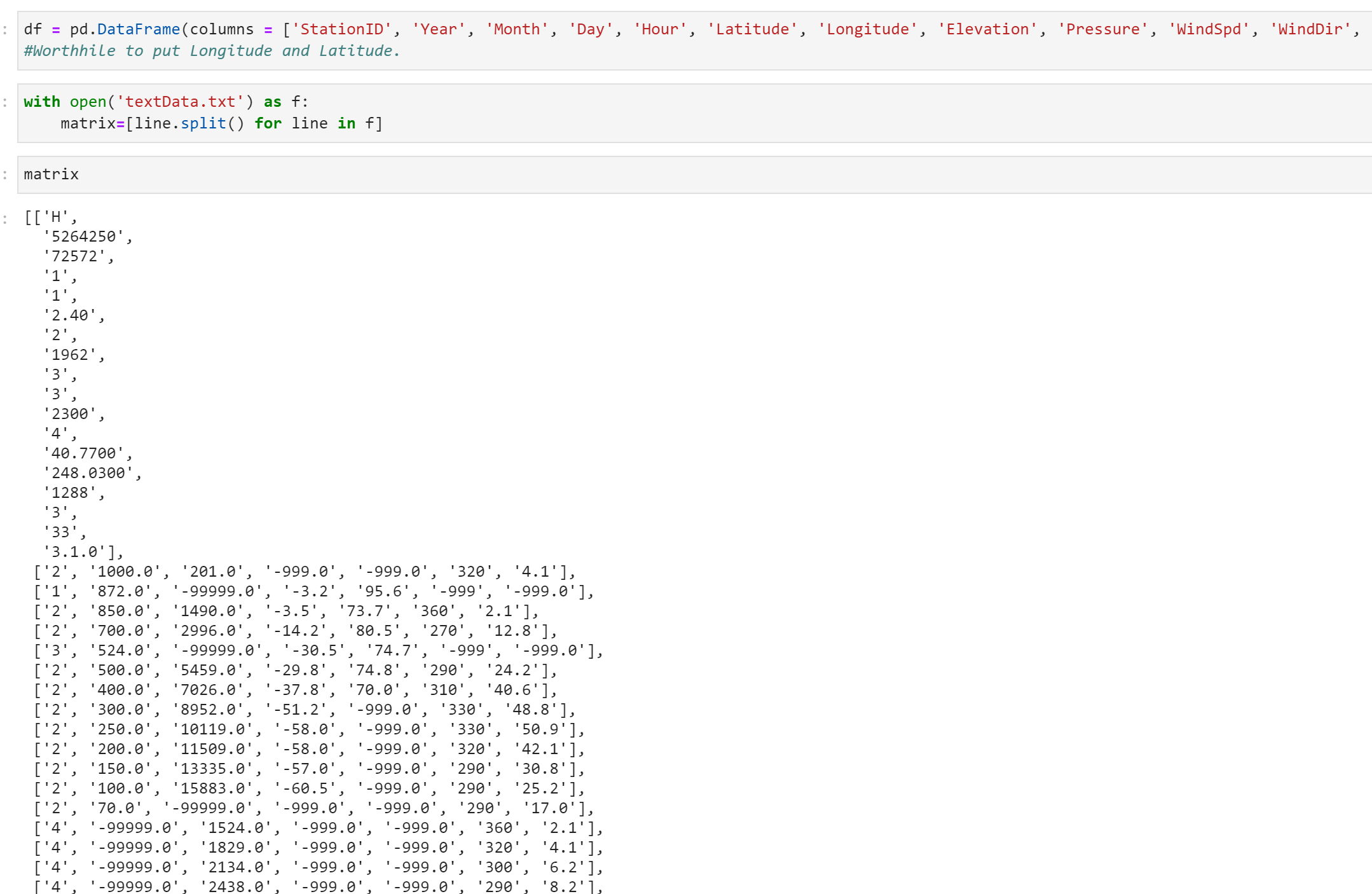
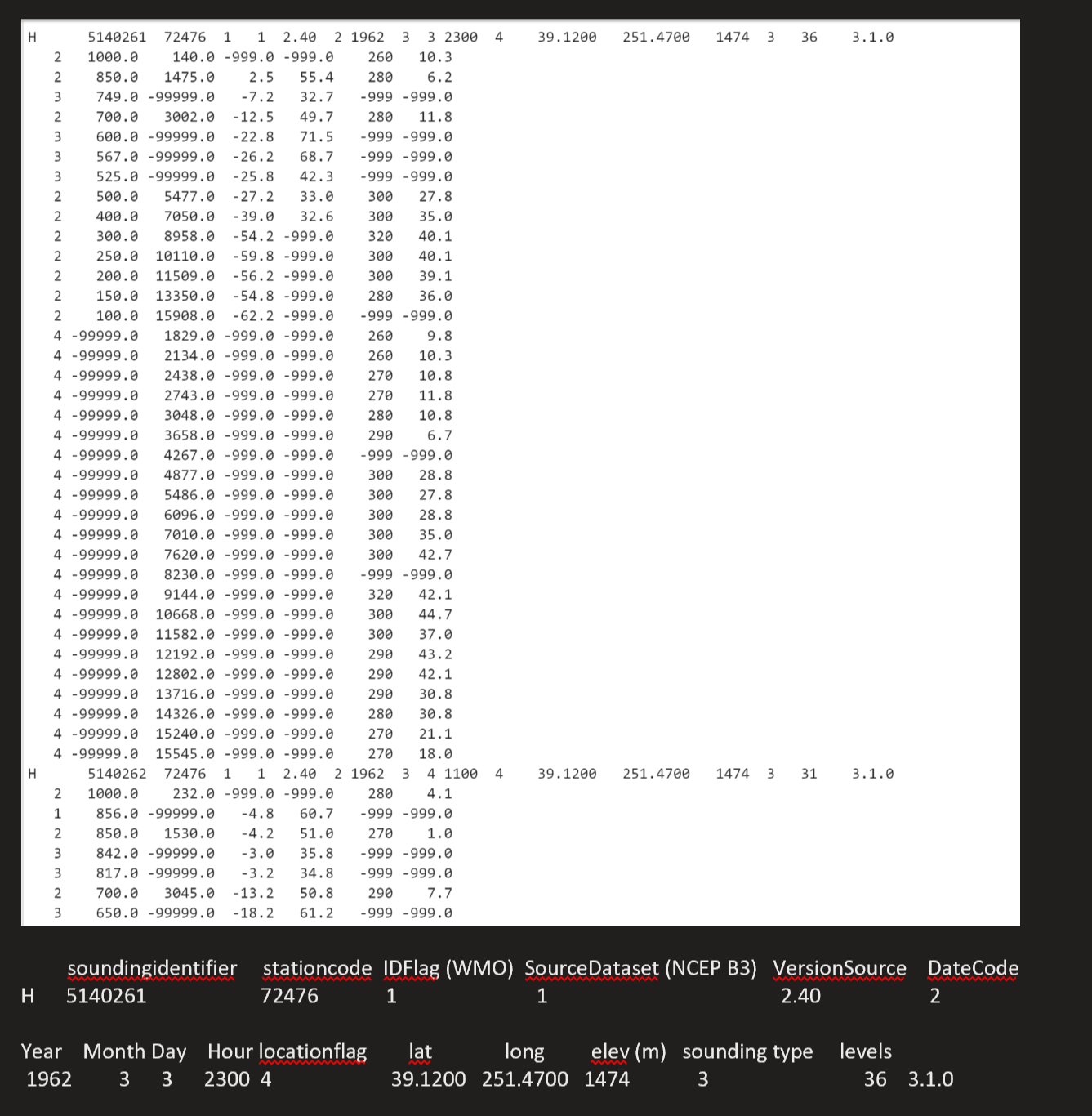
Hello everyone! I'm currently working to injest radiosonde data into a python dataframe, and while I've got my code working for a sub-sample of my radiosonde file, its time to try and apply my code to the full length file. I was wondering if anyone here knew how I could code up something which splits the data below each header into an array of arrays. I'm assuming I'll need to use some kind of regex parsing but I'm unfamiliar with the correct way to go about this. I've attached two images below. Data is an image of sample radiosonde data (Headers repeat a few times per txt file), and Sample is an image of what I want in terms of parsing. I want it to parse each header and the data below it into a List of Lists if that makes sense. How am I able to do this with multiple headers? Any guidance or help would be appreciated!
Anderson Banihirwe (Mar 29 2021 at 22:13):@Muntaha Pasha , Could you share here a few (first 20 ) rows of the contents in textData.txt?
Muntaha Pasha (Mar 29 2021 at 22:30):@Anderson Banihirwe Hey Anderson! textData.txt is just one header. I copy and pasted one header section from that data image I sent above. That's all it is. If you'd like to see the Radiosonde data though, I can resend it! Data.PNG
So text data is again, just the first 32 lines of this file ^ the first header and its contents, stopping right above the second header.
Anderson Banihirwe (Mar 30 2021 at 17:04):Could you actually paste the raw values (I can then copy and paste them locally without having to write them by hand :slight_smile: ) or point me to the actual Radiosonde data text file?
Muntaha Pasha (Mar 30 2021 at 18:14):Yes! I'll attach a link to the file here. I'll also modify my question a bit. In essence, I already know how to create a List of Lists using the file, but what I think I'm looking for is a way to create different list of lists everytime it reads a new header. So it will read Header 1, all the lines below it, and store it into a list of lists (line by line comma seperated as shown by the sample image above), but as soon as it hits the next header, it will store that information in a another list of lists (Can I create some kind of loop which automatically does this?)
Here is the link!
https://drive.google.com/file/d/1DCarav6CLCXV7MT7N4AolqeiNX1RFv9W/view?usp=sharing
Anderson Banihirwe (Mar 30 2021 at 20:04):Thank you for sending this over, @Muntaha Pasha ! What's the connection between the entries starting with H and the other entries?
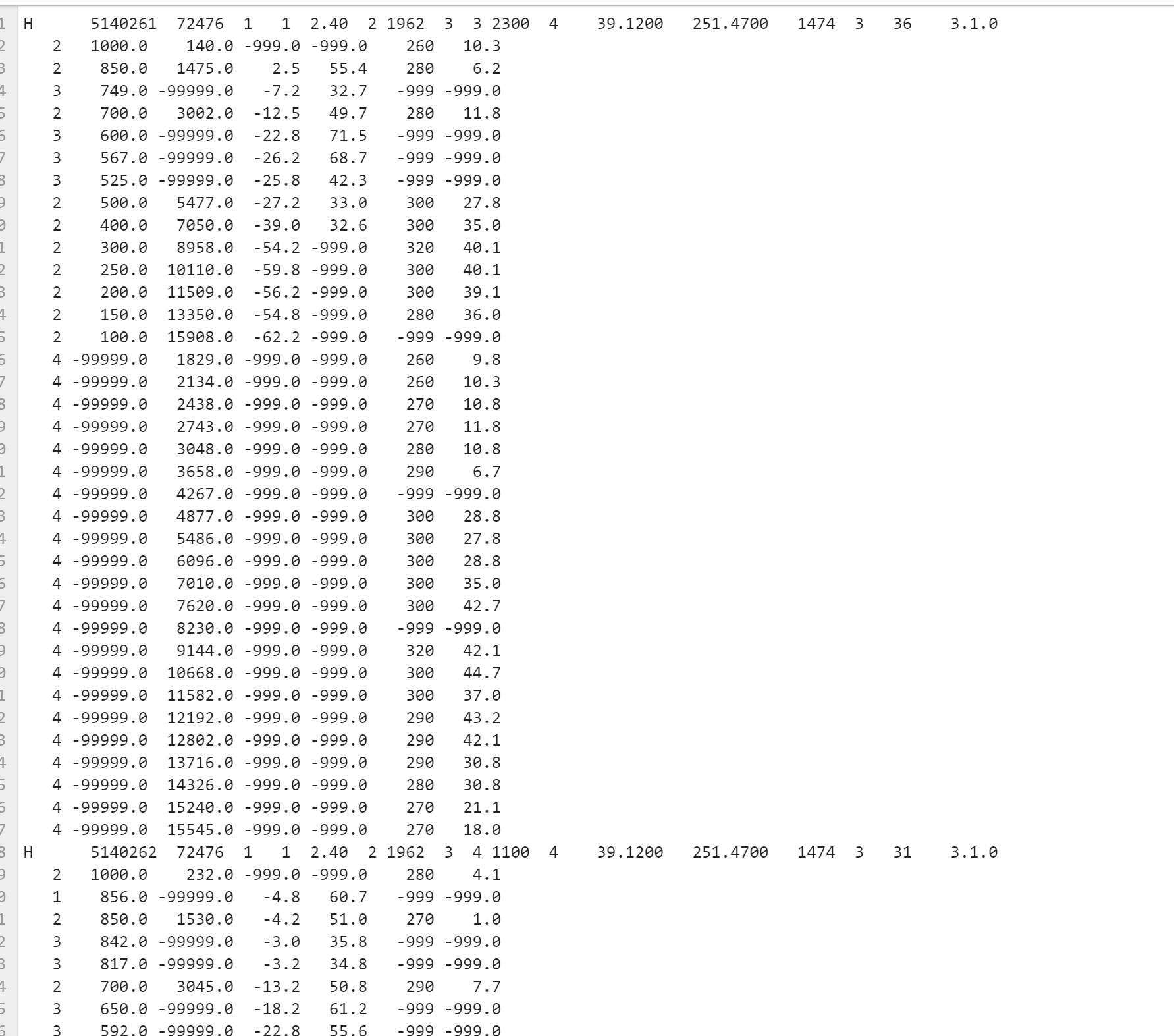
['H 5140261 72476 1 1 2.40 2 1962 3 3 2300 4 39.1200 251.4700 1474 3 36 3.1.0\n', ' 2 1000.0 140.0 -999.0 -999.0 260 10.3\n', ' 2 850.0 1475.0 2.5 55.4 280 6.2\n', ' 3 749.0 -99999.0 -7.2 32.7 -999 -999.0\n', ' 2 700.0 3002.0 -12.5 49.7 280 11.8\n',
I am noticing that they have different number of rows
Muntaha Pasha (Mar 30 2021 at 20:12):So H is a Header, it shows what date the radiosonde was sent up in the atmosphere to collect data, elevation of the station, a bunch of things like version # and status, and other useful information that researches might need. Underneath the H is rows corresponding to measurements the radiosonde actually took that day. For instance, line 2 is..
2, 1000.0, 140.0, -999.0, -999.0, 260, 10.3
Not sure what the 2 variable stands for, but 1000.0 is pressure, 140.0 is altitude in meters, then temperature in deg C (in this case i guess its missing data because of -999.0, then it's another -999.0 corresponding to Relative Humidity, 260 is wind direction, and 10.3 is wind speed in m/s.
Each column below the header is the same format.
some variable, pressure, altitude, temperature, relative humidity, wind dir, wind spd,
and then the next header starts and the same thing repeats. Hope that helps!
Anderson Banihirwe (Mar 30 2021 at 21:14):Great..
So H is a Header, it shows what date the radiosonde was sent up in the atmosphere to collect data, elevation of the station, a bunch of things like version # and status, and other useful information that researches might need.
How do you want to encode this header information in the resulting dataframe? One approach is to have 18 additional columns (which can be used to create a multi-index)
Anderson Banihirwe (Mar 30 2021 at 21:17):Could you send me the description for all 18 values in the header row?
['H 5140261 72476 1 1 2.40 2 1962 3 3 2300 4 39.1200 251.4700 1474 3 36 3.1.0\n',
Muntaha Pasha (Mar 30 2021 at 21:21):So my idea is to only take certain parts of the header and use them.
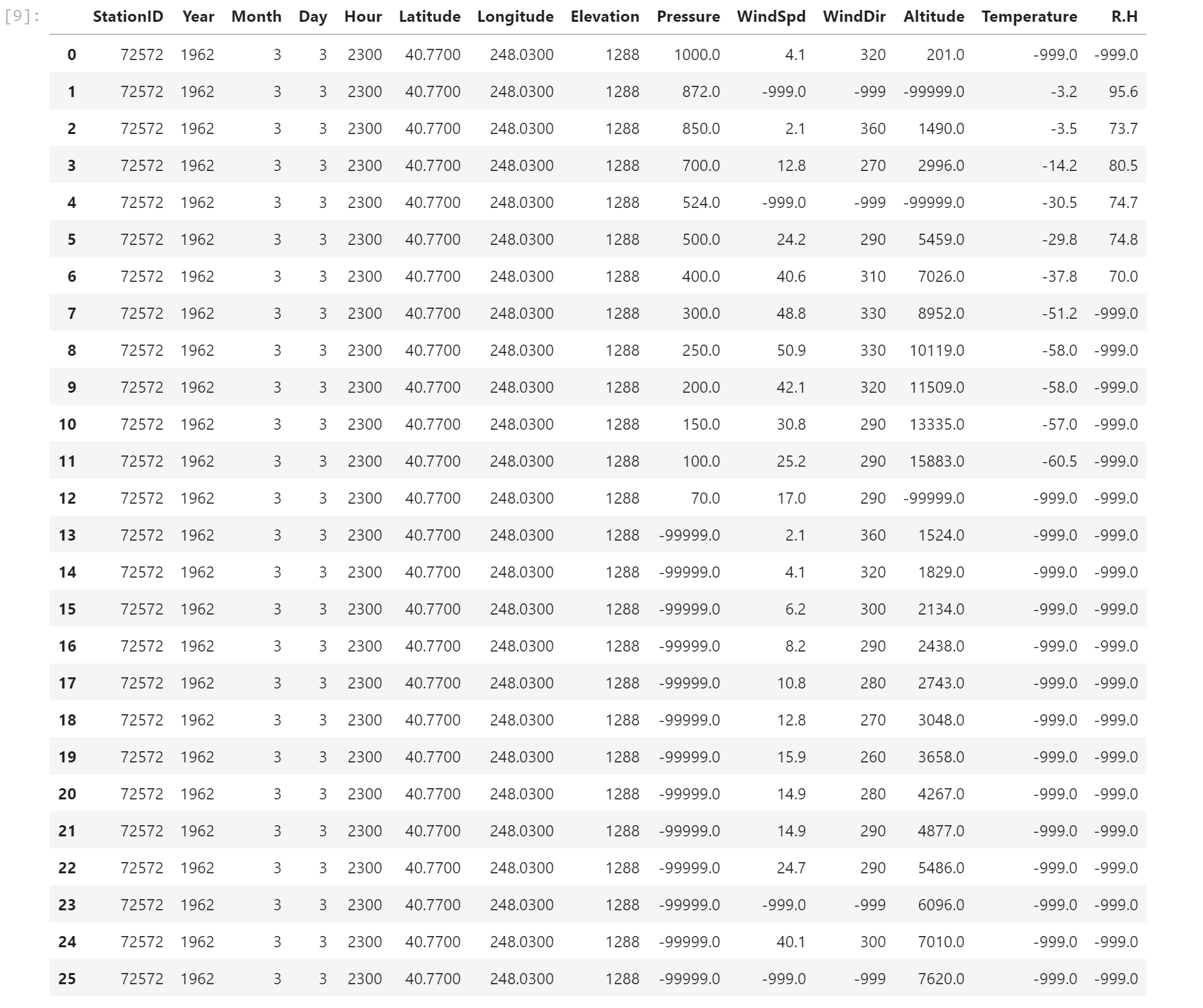
Here's an image of my dataframe. df.PNG
I want it to repeat station ID, Year, Month, Day, Latitude, Longitude, and Elevation for as long as the record spans. Then the next header starts, and the year, month, day might be different, but it would need to repeat for however long that header section is.
https://rda.ucar.edu/datasets/ds370.1/docs/uadb-format-ascii.pdf
Here's a link to reading the header information. Incase you want a quick guide though, heres an image of a header I already decoded.
Capture.PNG
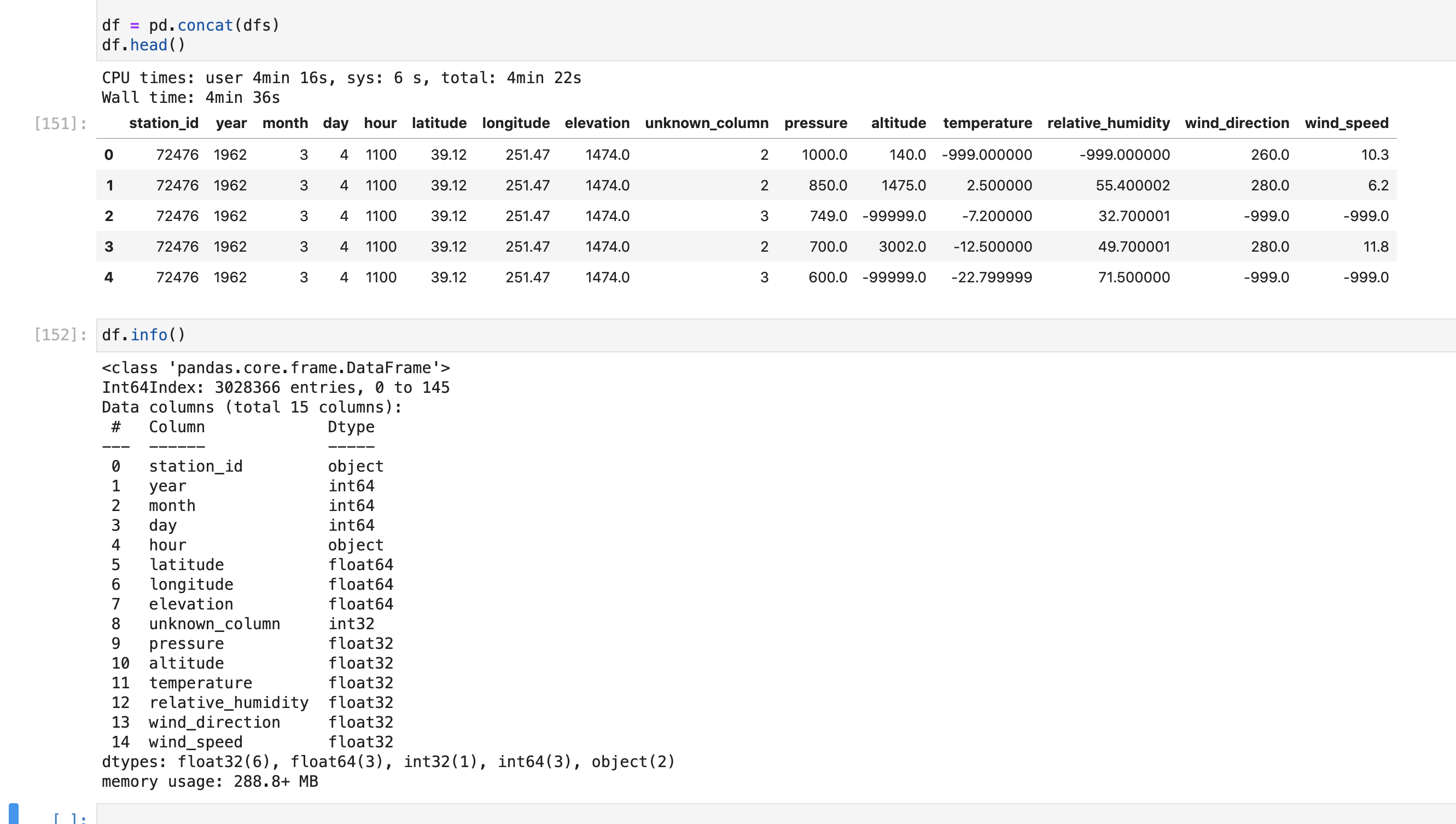
Anderson Banihirwe (Mar 30 2021 at 22:11):@Muntaha Pasha, here's what I came up with. It takes ~4min 30s to parse the entire file and construct the final dataframe:
import pathlib import pandas as pd file = pathlib.Path("/tmp/uadb_trh_72476_GJ,CO.txt") with file.open() as f: data = f.read().splitlines() dfs = [] dtypes = {'unknown_column': 'int32', 'pressure': 'float32', 'altitude': 'float32', 'temperature': 'float32', 'relative_humidity': 'float32', 'wind_direction': 'float32', 'wind_speed': 'float32'} header_row_cols = ['station_id', 'year', 'month', 'day', 'hour', 'latitude', 'longitude', 'elevation'] x = [] for entry in data: entry = entry.strip().split() if len(entry) == 7: x.append(entry) elif len(entry) == 18 and x: station_id = entry[2] year = int(entry[7]) month = int(entry[8]) day = int(entry[9]) hour = entry[10] #time = f"{year}-{month}-{day}T{hour}" latitude = float(entry[12]) longitude = float(entry[13]) elevation = float(entry[14]) temp_df = pd.DataFrame(x, columns=list(dtypes.keys())).astype(dtypes) header_df = pd.DataFrame([[station_id, year, month, day, hour, latitude, longitude, elevation]]*temp_df.shape[0], columns = header_row_cols) df = header_df.join(temp_df) dfs.append(df) x = [] df = pd.concat(dfs) df.head()
Screen-Shot-2021-03-30-at-4.10.39-PM.png
Muntaha Pasha (Mar 30 2021 at 22:25):Hi Anderson, this looks great! :) I think I'll be able to take pieces of this code and add it to my function! Thanks for all your help, I really appreciate it.
Muntaha Pasha (Apr 13 2021 at 21:34):Hi @Anderson Banihirwe ! So I was testing your code and functions, which do the same thing as what I wrote, however, for some reason, it's not changing the date time even though you've allocated it to change with the header. Do you know why this is? The rest of the information does change but the header date/time stays the same throughout the record even though ideally it should change as well.
Last updated: May 16 2025 at 17:14 UTC