Abishek Gopal (Feb 22 2021 at 17:07): Abishek Gopal (Feb 22 2021 at 17:07):
Abishek Gopal (Feb 22 2021 at 17:07): Abishek Gopal (Feb 22 2021 at 17:07):Hi folks,
I'm a software engineer with iHESP, which is a collaboration between NCAR, Texas A&M and QNLM, China. @Matt Long added me on here a while ago, but I finally thought I'd drop in and ask a question. One of our projects is the Regional Community Earth System Model (R-CESM), which uses the existing CESM framework to couple ROMS and WRF for a regional domain. As part of that project, we have been learning how to post-process ROMS model output using the Pangeo framework. We're making use of xroms , which builds on grid metrics available through xgcm.
I'm having issues when trying to chain xgcm's vertical interpolation (wrapped by xroms) with a simple time mean operation. salt has dimensions (ocean_time, s_rho, eta_rho, xi_rho).
depths = [-500, -1000] varout = xroms.isoslice(ds.salt, depths, ds.salt.attrs['grid']).mean('ocean_time') varout.compute()
The above statements are successful with a small number of files open, but crashes when the dataset is large. I inspected the dask dashboard and realized that dask is trying to open too many time steps (and interpolate them) without sufficiently reducing data with the mean operation. And so the workers run out of memory. Kristen Thyng pointed me to a very helpful thread on memory backpressure, and so I tried one of the solutions listed in the thread: dask.config.set(**{"optimization.fuse.ave-width": 20}), and the operations seemed to work for moderately-sized datasets, but still failed for the larger ones. I wanted to ask if you had any ideas on how I should proceed here.
I was wondering if I'd have more luck with manually parallelizing the vertical interpolation + mean operation using dask.delayed. The intention being that I might at least get a say on how much data is being opened before the average operation. I wanted to ask if the below statements could be equivalently performed using map_blocks(either the xarray or dask version).
I have a seemingly strange issue with below implementation. dask.array.stack seems to work if delayed_arrays is pre-computed before the stack operation, but fails if it's evaluated lazily (like below).
def func(da): import xroms depths = [-500,-1000] avg = xroms.isoslice(da, depths, da.attrs['grid']).mean('ocean_time') return avg var = ds['salt'].chunk({"ocean_time": 8, "s_rho":-1, "eta_rho": -1, "xi_rho": -1}) delayed_tasks = [dask.delayed(func)(var[i:i+8]) for i in range(var.shape[0]) if i%8 == 0] template = dask.delayed(func)(var[0:8]).compute(scheduler='single-threaded') delayed_arrays = [] for task in delayed_tasks: delayed_arrays.append(dask.array.from_delayed(task,template.shape,template.dtype)) output = dask.array.stack(delayed_arrays, axis=0).mean(axis=0).compute()
Deepak Cherian (Feb 22 2021 at 17:17):@Abishek Gopal can you post a reproducible example that I can run on casper?
One trick is to try .isoslice(..).to_zarr this will write to disk in parallel, and decrease memory. You can then open the zarr file to calculate the time mean.
Deepak Cherian (Feb 22 2021 at 17:25):If that doesn't work then wrap the .isoslice(...).to_zarr() in a map_blocks call. This forces dask to interpolate and write in the same task (you're forcing dask to "fuse" the two steps), and should definitely work. You can use the region keyword in to_zarr to write to the same store.
Abishek Gopal (Feb 22 2021 at 17:30):Thank you @Deepak Cherian! I haven't tried to_zarr() before, and will need to check out your suggestions.
I will also look into getting you a reproducible notebook. Some of our datasets might be on glade, but will need to check.
Abishek Gopal (Feb 22 2021 at 22:28):@Deepak Cherian I'm running into a few issues when trying to wrap .isoslice(...).to_zarr() in a map_blocks call.
Here's my code snippet:
def write_zarr(ds_block): ds_block.to_zarr('./zarr_path',consolidated=True) depths = [-50, -100] ds1 = xr.Dataset(attrs=ds.attrs ) ds1['salt'] = xroms.isoslice(ds.salt, depths, ds.salt.attrs['grid']) for ii in ds1.data_vars: if 'grid' in ds1[ii].attrs: del ds1[ii].attrs['grid'] ## grid attribute incompatible with to_zarr() xr.map_blocks(write_zarr, ds1)
Deepak Cherian (Feb 22 2021 at 22:33):return something small like ds_block.time and pass template=ds1.time in map_blocks
Deepak Cherian (Feb 22 2021 at 22:34):(ideally we would have Dataset.to_delayed but we don't so this is a workaround...)
Abishek Gopal (Feb 23 2021 at 15:45):Thanks for your suggestions! I eventually got map_blocks to work by using template = xr.DataArray(data=np.arange(1)).chunk((1,)). I tried with ds.ocean_time before, but I got an error saying the object was not iterable, probably because it wasn't chunked.
My map_blocks function appears to write to a zarr store now, but it seems to be writing out only one block in total, despite there being 9 chunks in salinity. Would this be because I haven't used the region keyword in to_zarr yet? I wasn't sure how to get the extents of the current block within the callable function (from map_blocks). I've seen there is a block_info variable in the dask version of map_blocks, but haven't seen an equivalent in the xarray docs.
Here's my current code
def func3(da): depths = [-500, -1000] varout = xroms.isoslice(da, depths, da.attrs['grid']) if 'grid' in varout.attrs: del varout.attrs['grid'] varout.to_dataset(name='salt').to_zarr('./zarr_path') return xr.DataArray(data=np.arange(1)).chunk((1,)) template = xr.DataArray(data=np.arange(1)).chunk((1,)) xr.map_blocks(func3,ds.salt,template=template)
Deepak Cherian (Feb 23 2021 at 15:54):Would this be because I haven't used the region keyword in to_zarr yet?
yes absolutely.
I wasn't sure how to get the extents of the current block within the callable function (from map_blocks).
block_info wasn't implemented because you know it from the coordinate variables (lat_rho, lon_rho)
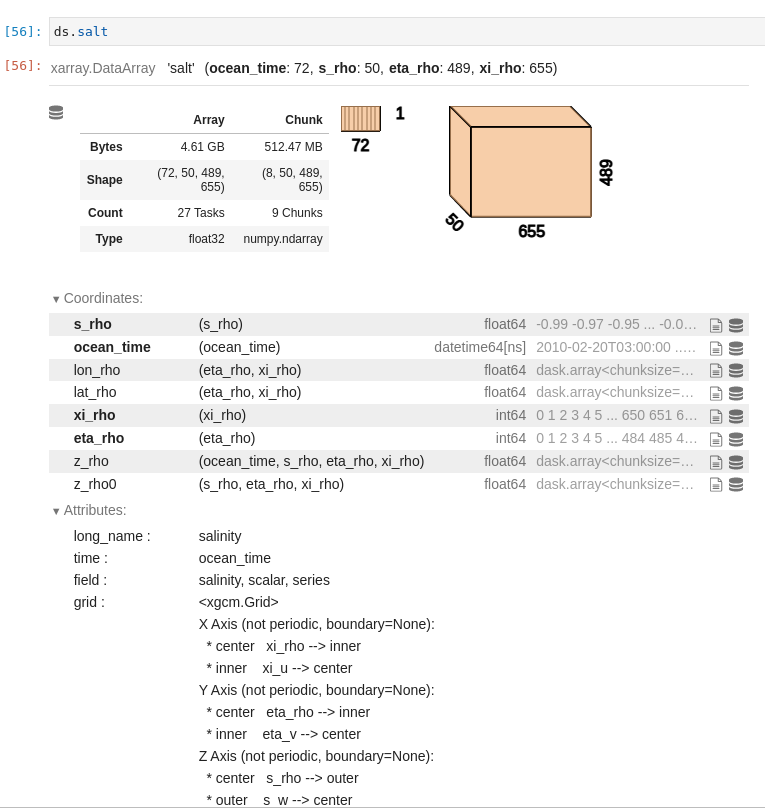
I see now that region expects integers. Can you show me the repr for ds.salt?
Abishek Gopal (Feb 23 2021 at 16:57):Oh got it. Here's what ds.salt looks like.
Deepak Cherian (Feb 23 2021 at 17:52):right so you can use xi_rho and eta_rho to write to the right region
Deepak Cherian (Feb 23 2021 at 17:53):See https://xarray.pydata.org/en/stable/io.html#appending-to-existing-zarr-stores
Abishek Gopal (Feb 23 2021 at 21:21):Thanks @Deepak Cherian! Since I'm chunking in time, I decided to create a temp index along time to simplify the process of selecting the region (.assign_coords(ind=("ocean_time", np.arange(varin.ocean_time.size)))). And then I followed the link you sent to first create a dummy zarr store with zeros across the full size of the variable, and call map_blocks to overwrite specific regions.
I checked that the dummy zarr store had size:72 along time before calling map_blocks, but I still get this message when appending to the dummy store.
**ValueError: variable 'ocean_time' already exists with different dimension sizes: {'ocean_time': 7} != {'ocean_time': 0}. to_zarr() only supports changing dimension sizes when explicitly appending, but append_dim=None.
**
Here's my code:
def func3(da): depths = [-500, -1000] varout = xroms.isoslice(da, depths, da.attrs['grid']).compute() t0=da.ind[0].data t1=da.ind[-1].data if 'grid' in varout.attrs: del varout.attrs['grid'] varout.to_dataset(name='salt').to_zarr('./zarr_path', region={"ocean_time": slice(t0,t1)}) ## also call .drop(['lon_rho', 'lat_rho', 'xi_rho', 'eta_rho', 'z_rho']) prior to to_zarr() return xr.DataArray(data=np.arange(1)).chunk((1,)) template = xr.DataArray(data=np.arange(1)).chunk((1,)) depths = [-50, -100] varin = ds.salt dummies = xr.zeros_like(varin) if 'grid' in dummies.attrs: del dummies.attrs['grid'] dummies.to_dataset(name='salt').to_zarr('./zarr_path', compute=False, consolidated=True) varin = varin.assign_coords(ind=("ocean_time", np.arange(varin.ocean_time.size))) xr.map_blocks(func3,varin,template=template)
Deepak Cherian (Feb 23 2021 at 21:58):hmm... not sure. I would try the simple example in the documentation first and work from there.
Last updated: May 16 2025 at 17:14 UTC