Anna-Lena Deppenmeier (Apr 02 2021 at 18:04): Anna-Lena Deppenmeier (Apr 02 2021 at 18:04):
Anna-Lena Deppenmeier (Apr 02 2021 at 18:04): Anna-Lena Deppenmeier (Apr 02 2021 at 18:04):Hi all,
I have an issue with chunking while loading my dataset. I read my datasets like this
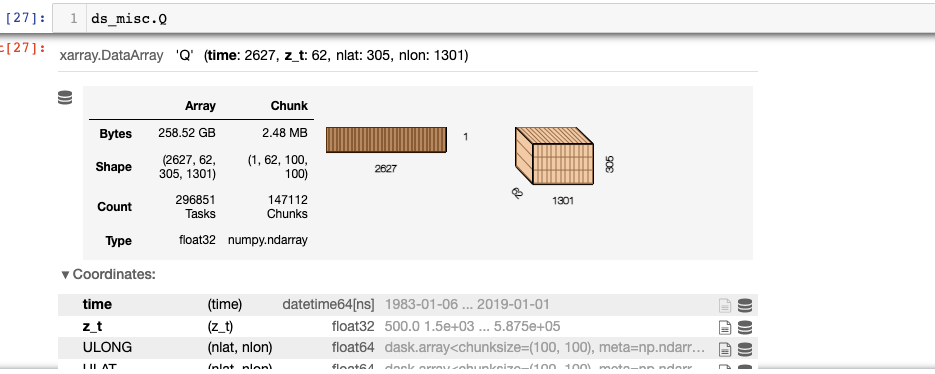
def read_dat(files, variables, pop=False, chunks={'time':100, 'nlat':100, 'nlon':100, 'z_t':-1}): def preprocess(ds): return ds[variables].reset_coords(drop=True) # reset coords means they are reset as variables ds = xr.open_mfdataset(files, parallel=True, preprocess=preprocess, chunks=chunks, combine='by_coords') if pop==True: file0 = xr.open_dataset(files[0], chunks=chunks) ds.update(file0[['ULONG', 'ULAT', 'TLONG', 'TLAT']]) file0.close() ds return ds
but somehow this doesn't result in the desired chunks (120MB each) when I use it
flist = glob.glob('/project/oce/deppenme/process-dat/more_years/Pac_POP0.1_JRA_IAF_*.nc') ds_misc = read_dat(flist, ['TEMP', 'WVEL', 'UVEL', 'VVEL', 'DIA_IMPVF_TEMP', 'Q'], pop=True, chunks={'time':100, 'nlat':100, 'nlon':100, 'z_t':-1})
pasted image
Any ideas how to better do this?
(I am currently trying chunking while just reading with xr.open_mfdataset() and it takes way too long)
Deepak Cherian (Apr 02 2021 at 18:09):It looks like you have one file per timestep, so open_mfdataset cannot apply chunking along time. I would chunk the other 3 dimensions to make bigger chunks, if you can. If you really need to chunk along time, you'll have to do it after reading the files.
Anna-Lena Deppenmeier (Apr 02 2021 at 18:22):Thanks! Trying other chunks to get to the desired chunk size.
Last updated: May 16 2025 at 17:14 UTC