Stephen Yeager (Oct 15 2021 at 22:42): Stephen Yeager (Oct 15 2021 at 22:42):
Stephen Yeager (Oct 15 2021 at 22:42): Stephen Yeager (Oct 15 2021 at 22:42):I'm using intake-esm to ingest CMIP6 OMIP data using:
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cmip6.json'
col = intake.open_esm_datastore(catalog_file)
cat_so = col.search(
experiment_id=['omip1', 'omip2'],
variable_id=['so'],
table_id='Omon'
)
dset_dict_so = cat_so.to_dataset_dict(
cdf_kwargs={'chunks': {'time':12},'decode_times': True, 'use_cftime': True}
)
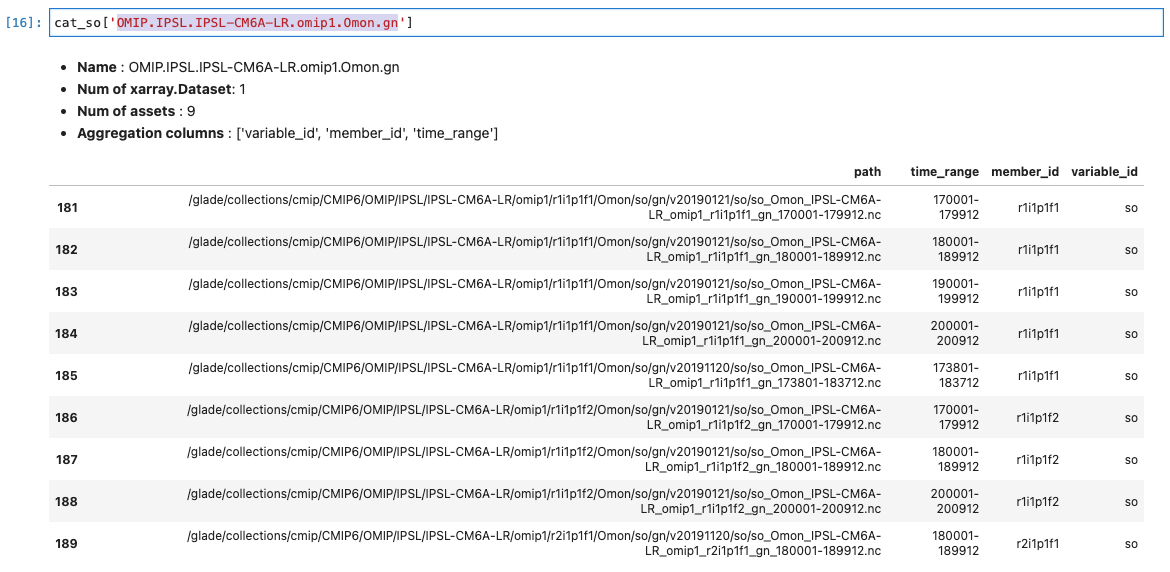
This returns an xarray.concat() error for key 'OMIP.IPSL.IPSL-CM6A-LR.omip1.Omon.gn'. The catalog for that key (Screen-Shot-2021-10-15-at-4.41.26-PM.png) shows duplicate entries (different versions) as well as missing data for one member_id. I don't know if this is related to ongoing updates to OMIP data holdings or if the json catalog needs updating. Who should I ask about this?
Anderson Banihirwe (Oct 18 2021 at 13:48):This returns an xarray.concat() error for key 'OMIP.IPSL.IPSL-CM6A-LR.omip1.Omon.gn'. The catalog for that key (Screen-Shot-2021-10-15-at-4.41.26-PM.png) shows duplicate entries (different versions)
@Stephen Yeager, It appears that there's a bug in the catalog generation code. Some of these files should be excluded from the catalog. I will look into it. For a temporary workaround, you can use the .drop() method to modify the dataframe:
indices_to_drop = [...]
cat_so.df = cat_so.df.drop(indices_to_drop)
as well as missing data for one member_id. I don't know if this is related to ongoing updates to OMIP data holdings
I just checked the directories on Glade, and the data are just missing on the filesystem:
$ ls /glade/collections/cmip/CMIP6/OMIP/IPSL/IPSL-CM6A-LR/omip1/r2i1p1f1/Omon/so/gn/v20191120/so
so_Omon_IPSL-CM6A-LR_omip1_r2i1p1f1_gn_180001-189912.nc
Thanks @Anderson Banihirwe . Shiquan Su informed me that the update to OMIP data holdings on glade is still ongoing. Will the glade-cmip6.json file get updated automatically as data is added?
Anderson Banihirwe (Oct 18 2021 at 18:13):Will the glade-cmip6.json file get updated automatically as data is added?
Unfortunately not... I have to run the script.
Matt Long (Oct 18 2021 at 23:07):@Eric Nienhouse, there is a growing community using intake-esm to access data on the CMIP AP. Would be great to discuss with @xdev how to automate the process of keep catalogs up to date.
Stephen Yeager (Oct 22 2021 at 16:53):I'd like to be part of this discussion. @Max Grover wrote a blog post discussing a problem I was having using intake-esm for CMIP6 OMIP data (https://ncar.github.io/esds/posts/2021/intake_cmip6_debug/). The root of the problem was missing data on the CMIP AP. I put in a request for a full update of OMIP data on CMIP AP back in late September, and am finding that this process takes a very long time, to the point that intake-esm may not be a viable solution for me.
Stephen Yeager (Apr 13 2022 at 14:50):I'd like to revisit the issues with the CMIP6 data catalog discussed above. The download for CMIP6 OMIP data is complete and it would be helpful if someone could regenerate the catalog (/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cmip6.json) to exclude duplicate/erroneous entries for experiment_id=['omip1', 'omip2']. The workarounds discussed above introduce messy kludges in notebooks that we want to eventually share.
Last updated: May 16 2025 at 17:14 UTC