Anna-Lena Deppenmeier (Aug 05 2020 at 15:34): Anna-Lena Deppenmeier (Aug 05 2020 at 15:34):
Anna-Lena Deppenmeier (Aug 05 2020 at 15:34): Anna-Lena Deppenmeier (Aug 05 2020 at 15:34):Hi all, I'm currently trying to look for some variables in the OMIP experiment on glade using intake_esm and I'm getting an error I haven't seen before. I have loaded the columns
catalog_path = "/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cmip6.json" col = intake.open_esm_datastore(catalog_path)
and then my catalog
cat = col.search(
experiment_id=["omip1"],
)
I get 24 keys and choose one to get my dataset
ds_cnrm = cat['OMIP.CNRM-CERFACS.CNRM-CM6-1.omip1.Omon.gn'](zarr_kwargs={'consolidated': True, 'decode_times': True})
ds_cnrm
<intake_esm.source.ESMGroupDataSource at 0x2b113f634150>
but when I try to add .to_dask I get
ds_cnrm.to_dask()
ValueError Traceback (most recent call last)
<ipython-input-26-1333ad1b871a> in <module>
----> 1 ds_cnrm.to_dask()
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/source.py in to_dask(self)
91 def to_dask(self):
92 """Return xarray object (which will have chunks)"""
---> 93 self._load_metadata()
94 return self._ds
95
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake/source/base.py in _load_metadata(self)
115 """load metadata only if needed"""
116 if self._schema is None:
--> 117 self._schema = self._get_schema()
118 self.datashape = self._schema.datashape
119 self.dtype = self._schema.dtype
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/source.py in _get_schema(self)
54
55 if self._ds is None:
---> 56 self._open_dataset()
57
58 metadata = {
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/source.py in _open_dataset(self)
83 self.zarr_kwargs,
84 self.cdf_kwargs,
---> 85 self.preprocess,
86 )
87 ds.attrs['intake_esm_dataset_key'] = self.name
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/merge_util.py in _aggregate(aggregation_dict, agg_columns, n_agg, v, lookup, mapper_dict, zarr_kwargs, cdf_kwargs, preprocess)
168 return ds
169
--> 170 return apply_aggregation(v)
171
172
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/merge_util.py in apply_aggregation(v, agg_column, key, level)
159 f'Merging {len(dsets)} dataset(s) into a single Dataset with options={agg_options}.\ndsets={dsets}'
160 )
--> 161 ds = union(dsets, options=agg_options)
162
163 ds.attrs = attrs
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/merge_util.py in union(dsets, options)
39 except Exception as e:
40 logger.error(f'Failed to merge datasets.')
---> 41 raise e
42
43
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/intake_esm/merge_util.py in union(dsets, options)
36 def union(dsets, options={}):
37 try:
---> 38 return xr.merge(dsets, **options)
39 except Exception as e:
40 logger.error(f'Failed to merge datasets.')
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/merge.py in merge(objects, compat, join, fill_value)
791 dict_like_objects.append(obj)
792
--> 793 merge_result = merge_core(dict_like_objects, compat, join, fill_value=fill_value)
794 merged = Dataset._construct_direct(**merge_result._asdict())
795 return merged
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/merge.py in merge_core(objects, compat, join, priority_arg, explicit_coords, indexes, fill_value)
548 coerced = coerce_pandas_values(objects)
549 aligned = deep_align(
--> 550 coerced, join=join, copy=False, indexes=indexes, fill_value=fill_value
551 )
552 collected = collect_variables_and_indexes(aligned)
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/alignment.py in deep_align(objects, join, copy, indexes, exclude, raise_on_invalid, fill_value)
407 indexes=indexes,
408 exclude=exclude,
--> 409 fill_value=fill_value,
410 )
411
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/alignment.py in align(join, copy, indexes, exclude, fill_value, *objects)
335 new_obj = obj.copy(deep=copy)
336 else:
--> 337 new_obj = obj.reindex(copy=copy, fill_value=fill_value, **valid_indexers)
338 new_obj.encoding = obj.encoding
339 result.append(new_obj)
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/dataset.py in reindex(self, indexers, method, tolerance, copy, fill_value, **indexers_kwargs)
2495 fill_value,
2496 sparse=False,
-> 2497 **indexers_kwargs,
2498 )
2499
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/dataset.py in _reindex(self, indexers, method, tolerance, copy, fill_value, sparse, **indexers_kwargs)
2526 copy=copy,
2527 fill_value=fill_value,
-> 2528 sparse=sparse,
2529 )
2530 coord_names = set(self._coord_names)
/glade/work/deppenme/miniconda3/envs/analysis/lib/python3.7/site-packages/xarray/core/alignment.py in reindex_variables(variables, sizes, indexes, indexers, method, tolerance, copy, fill_value, sparse)
547 raise ValueError(
548 "cannot reindex or align along dimension %r because the "
--> 549 "index has duplicate values" % dim
550 )
551
ValueError: cannot reindex or align along dimension 'time' because the index has duplicate values
If I try to load another dataset
ds_ncar = cat['OMIP.NCAR.CESM2.omip1.Omon.gn'](zarr_kwargs={'consolidated': True, 'decode_times': True})
ds_ncar
<intake_esm.source.ESMGroupDataSource at 0x2b113fa81a90>
and use .to_dask() I get
MergeError: conflicting values for variable 'lon' on objects to be combined. You can skip this check by specifying compat='override'.
and I haven't been able to add compat='override' anywhere so that the error goes away. The intake.__version__ I am using is '0.5.4'
I have used this before and it worked, and now it doesn't. any tips?
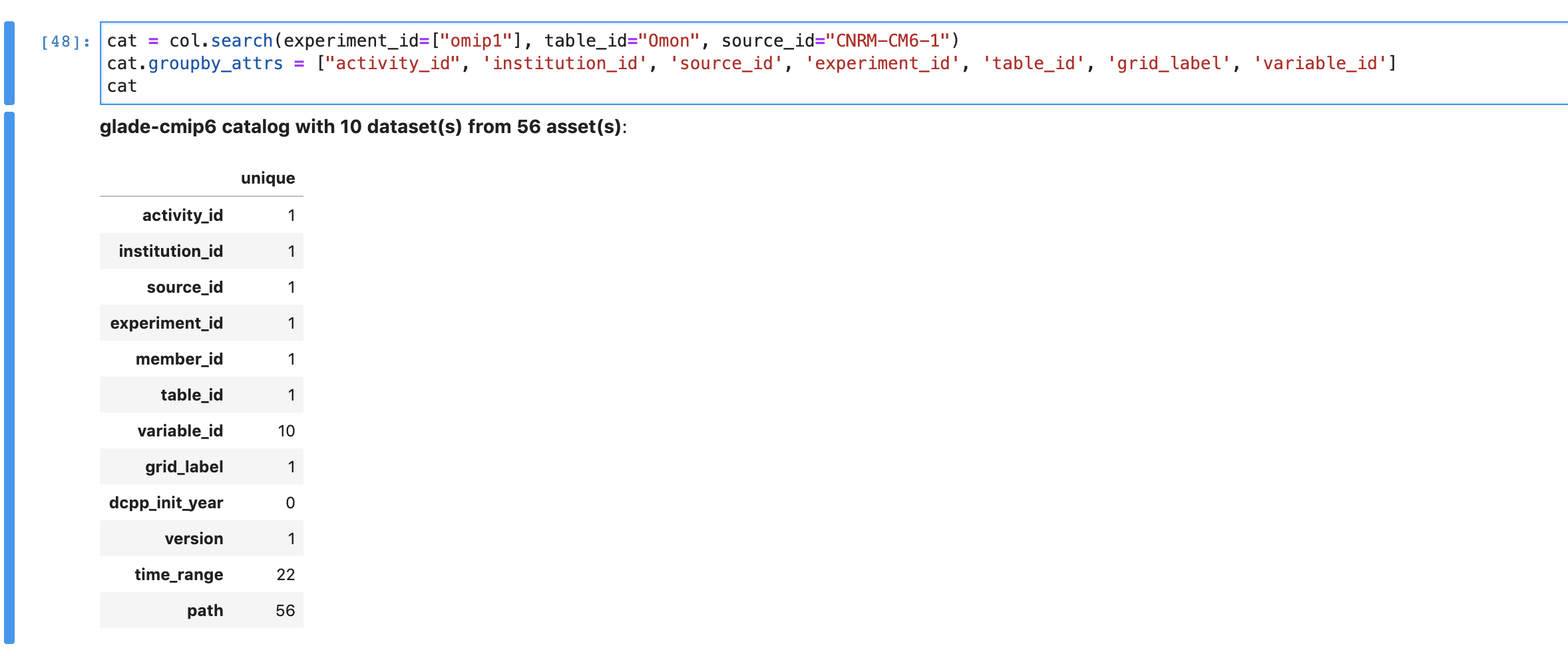
Anderson Banihirwe (Aug 05 2020 at 17:53):@Anna-Lena Deppenmeier, I am looking into this. So far, I have been able to isolate some of the problematic files/datasets by loading each variable in its own dataset instead of merging multiple variables into a single dataset:
Screen-Shot-2020-08-05-at-11.46.38-AM.png
As you can see below, some of the time axes aren't monotonic and have duplicate time values:
Screen-Shot-2020-08-05-at-11.46.45-AM.png
Anderson Banihirwe (Aug 05 2020 at 17:53):I will get back to you once I have a working solution
Deepak Cherian (Aug 05 2020 at 17:55):@Anderson Banihirwe how about adding a .debug_catalog function that prints these diagnostics to screen?
Anderson Banihirwe (Aug 05 2020 at 17:56):Anderson Banihirwe how about adding a
.debug_catalogfunction that prints these diagnostics to screen?
:+1:
Anderson Banihirwe (Aug 05 2020 at 17:57):I've been working on some utilities that will allow us to expose some debugging information to the user
Anderson Banihirwe (Aug 05 2020 at 17:58):E.g.. Turning aggregations off on the fly
Anderson Banihirwe (Aug 05 2020 at 18:00):I think the next step is to catch some of these recurring errors (duplicated time axis, coordinates mismatches, etc) and provide the user with some suggestions on how to address them.
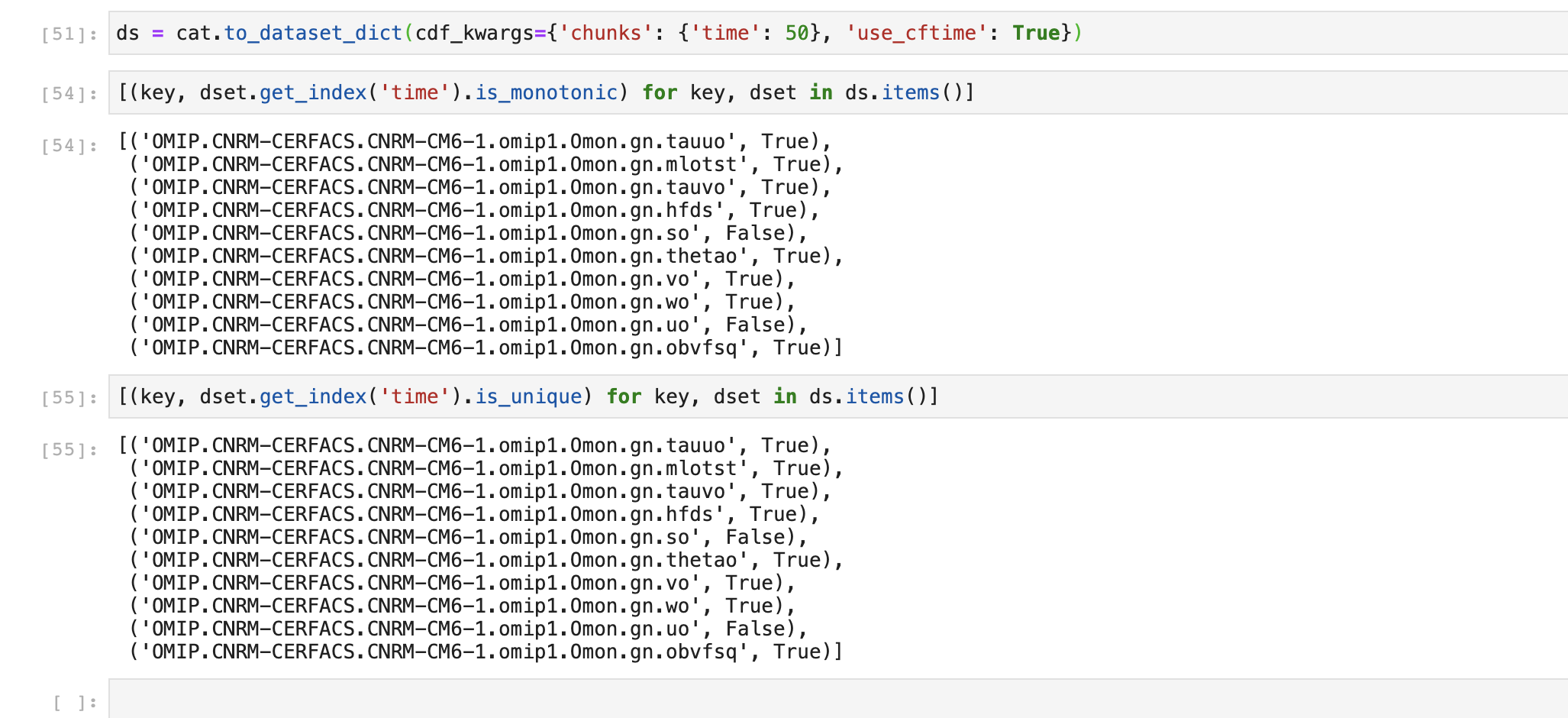
Anderson Banihirwe (Aug 05 2020 at 18:44):@Anna-Lena Deppenmeier, I think I now know where the time axis duplication is coming from:
Screen-Shot-2020-08-05-at-12.32.15-PM.png
Notice how for these two files, their time axes are overlapping:
File1: 1750-01 ---> 1796-12
File2: 1750-01 ---> 1799-12
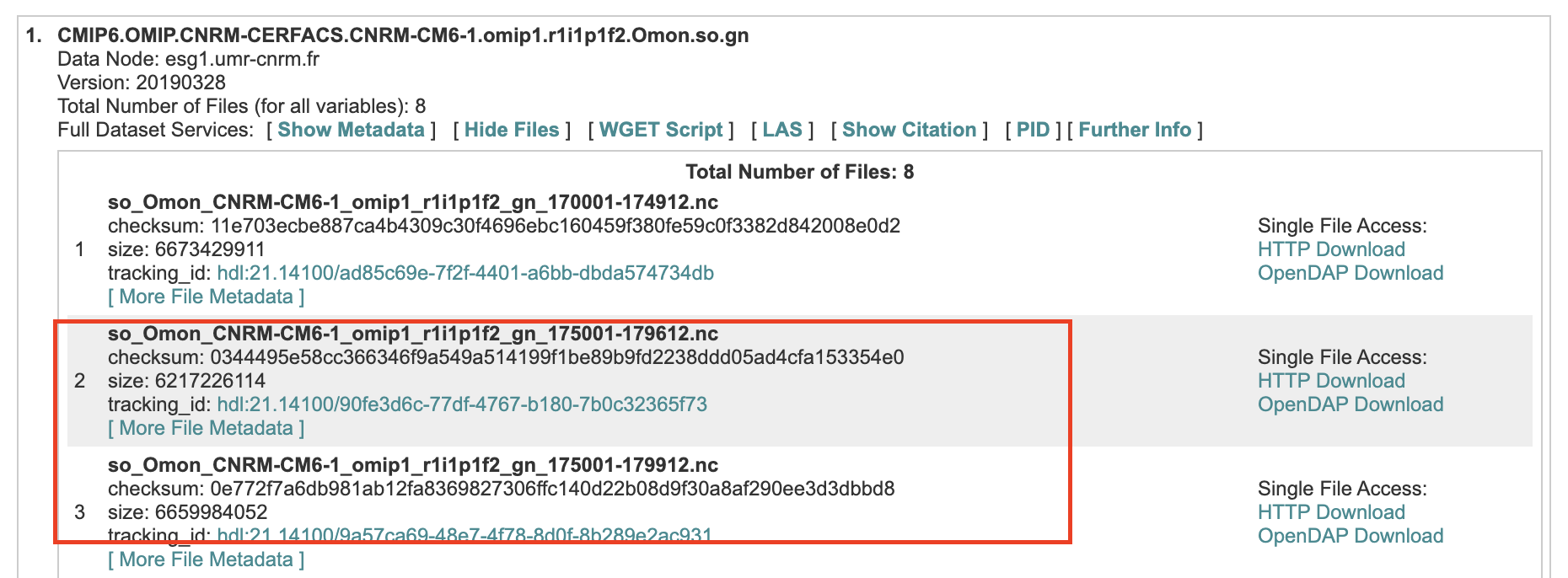
Could this have been a mistake when the model wrote the output or how the data was produced??? I did a quick search on ESGFs website, and found the two problematic files:
Screen-Shot-2020-08-05-at-12.42.49-PM.png
Anderson Banihirwe (Aug 05 2020 at 19:37):@Anna-Lena Deppenmeier, I have two recommendations:
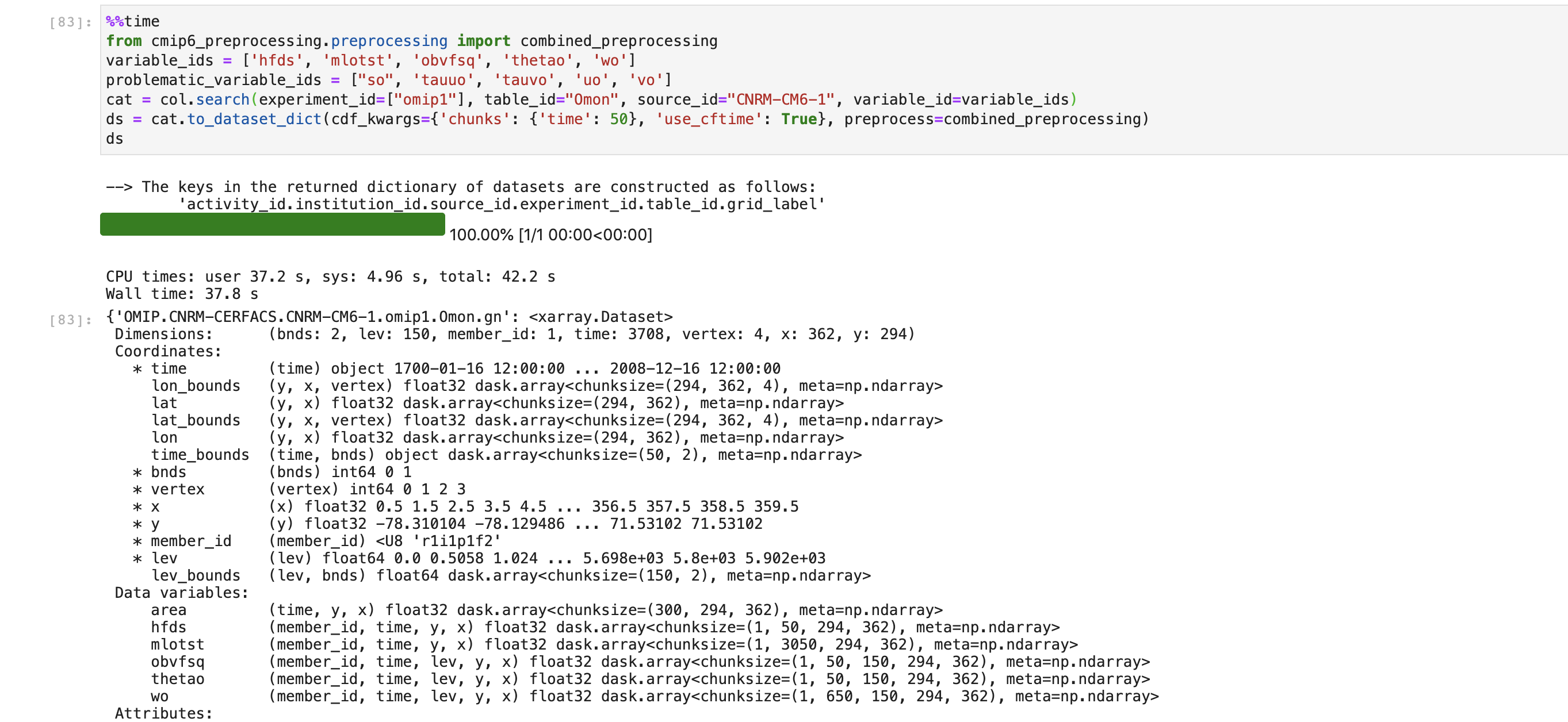
Option 1) You can work with a subset of variables ['hfds', 'mlotst', 'obvfsq', 'thetao', 'wo'] by excluding problematic variables ["so", 'tauuo', 'tauvo', 'uo', 'vo'] # duplicated time-axis and x-axis. Here, the variables that are okay, are merged into a single dataset.
Things seem to be working fine:
Screen-Shot-2020-08-05-at-1.15.38-PM.png
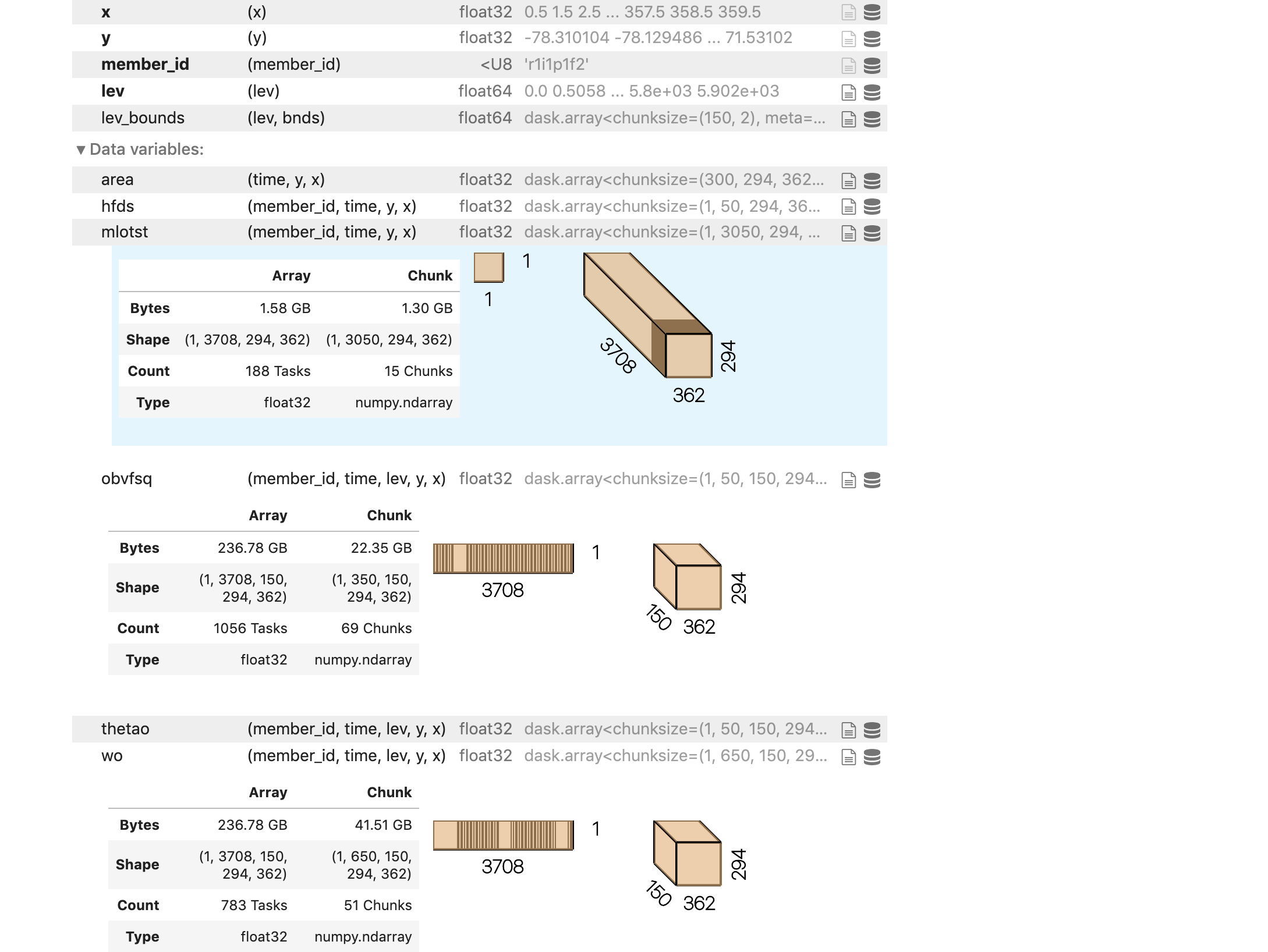
Dask appears to have messed up the chunking though. This may have to do with https://github.com/pydata/xarray/issues/4112 and https://github.com/intake/intake-esm/issues/225
Screen-Shot-2020-08-05-at-1.15.59-PM.png
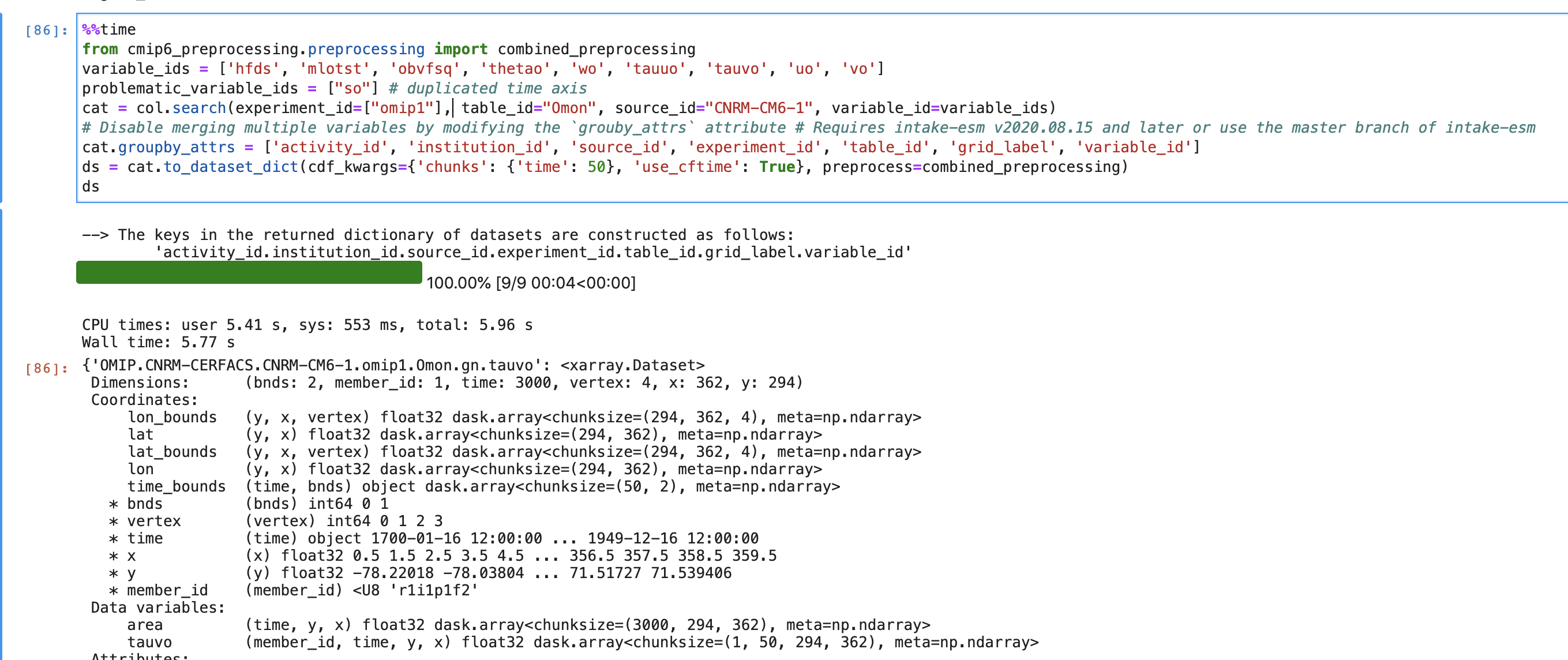
Option 2) Disable variable merging, and load each variable in its own datasets. For this option, variable_ids = ['hfds', 'mlotst', 'obvfsq', 'thetao', 'wo', 'tauuo', 'tauvo', 'uo', 'vo'] appear to be okay, and problematic_variable_ids = ["so"] # duplicated time axis is still problematic. Here, you get 9 datasets for the "okay" variables.
Screen-Shot-2020-08-05-at-1.26.10-PM.png
Anderson Banihirwe (Aug 05 2020 at 19:37):Note:
v2020.08.15 (which hasn't been released yet) and later or you can use the master branch of intake-esm (python -m pip install git+https://github.com/intake/intake-esm.git)cmip6preprocessing package. If you don't have it installed, you may want to install via pip or conda. Anna-Lena Deppenmeier (Aug 05 2020 at 19:37):Thank you @Anderson Banihirwe I will try that
Anna-Lena Deppenmeier (Aug 07 2020 at 19:08):Thanks @Anderson Banihirwe , it worked. What I actually want to find out, though, is which variables there are for which model (I am okay with specifying the experiment, I can go through the ones that interest me iteratively). Is there a clever way to do that?
Anderson Banihirwe (Aug 11 2020 at 17:49):What I actually want to find out, though, is which variables there are for which model (I am okay with specifying the experiment, I can go through the ones that interest me iteratively). Is there a clever way to do that?
@Anna-Lena Deppenmeier, the following may provide what you are looking for:
In [6]: col.df.groupby("source_id")["variable_id"].unique() Out[6]: source_id ACCESS-CM2 [clivi, clt, hfls, hus, huss, pr, prc, prsn, p... ACCESS-ESM1-5 [prsn, tas, tasmax, tasmin, zg, mrsol, cLitter... AWI-CM-1-1-MR [clivi, clt, clwvi, hfls, hus, huss, pr, prc, ... AWI-ESM-1-1-LR [clivi, clt, clwvi, evspsbl, hfls, pr, prc, pr... BCC-CSM2-MR [clt, co2, evspsbl, hfls, hfss, hus, huss, pr,... ... NorESM2-LM [mmrbc, mmrdust, mmroa, mmrso4, mmrss, od550ae... NorESM2-MM [clivi, clt, clwvi, co2mass, hfls, pr, prc, pr... SAM0-UNICON [clivi, clt, clwvi, co2mass, evspsbl, hfls, hf... TaiESM1 [od550aer, clivi, clt, clwvi, co2mass, hfls, p... UKESM1-0-LL [mmrbc, mmrdust, mmroa, mmrso4, mmrss, od550ae... Name: variable_id, Length: 76, dtype: object
As you can see, for brevity Pandas shows the first and last few values. For detailed information, you can just turn the results into a dictionary with:
In [8]: col.df.groupby("source_id")["variable_id"].unique().to_dict() Out[8]: {'ACCESS-CM2': array(['clivi', 'clt', 'hfls', 'hus', 'huss', 'pr', 'prc', 'prsn', 'prw', 'ps', 'psl', 'rlds', 'rlus', 'rlut', 'rlutcs', 'rsdt', 'rsut', 'rsutcs', 'sfcWind', 'ta', 'tas', 'tasmax', 'tasmin', 'ts', 'ua', 'uas', 'va', 'vas', 'wap', 'zg', 'mrsol', 'mrro', 'mrros', 'mrso', 'mrsos', 'areacello', 'sftof', 'agessc', 'bigthetao', 'evs', 'fsitherm', 'masscello', 'mlotst', 'msftbarot', 'msftmrho', 'msftyrho', 'pbo', 'prra', 'rlntds', 'rsntds', 'so', 'sos', 'thetao', 'tos', 'umo', 'uo', 'vmo', 'vo', 'volcello', 'volo', 'wfo', 'wmo', 'zos', 'siarean', 'siareas', 'siconc', 'siconca', 'siextentn', 'sisnconc', 'sisnthick', 'sithick', 'sivol', 'sivoln', 'sivols', 'sftlf', 'pfull', 'evspsbl', 'snw', 'basin', 'thkcello', 'hfds', 'msftmz', 'obvfsq', 'tauuo', 'tauvo', 'zostoga', 'hfss', 'rsds', 'rsdscs', 'rsus', 'rsuscs', 'areacella', 'od550aer'], dtype=object), 'ACCESS-ESM1-5': array(['prsn', 'tas', 'tasmax', 'tasmin', 'zg', 'mrsol', 'cLitter', 'cVeg', 'gpp', 'lai', 'mrro', 'mrros', 'mrso', 'mrsos', 'chl', 'detoc', 'dfe', 'dissic', 'dissicnat', 'eparag100', 'epc100', 'evs', 'fgco2', 'fgco2nat', 'fgo2', 'fsitherm', 'masscello', 'mlotst', 'no3', 'o2', 'pbo', 'po4', 'prra', 'rlntds', 'rsntds', 'so', 'spco2', 'spco2nat', 'thetao', 'umo', 'uo', 'vmo', 'vo', 'volo', 'wmo', 'cLeaf', 'nbp', 'npp', 'ra', 'chlos', 'tos', 'siconc', 'sisnconc', 'sisnthick', 'sithick', 'hfds', 'sos', 'clivi', 'clt', 'hfls', 'hus', 'huss', 'pr', 'prc', 'prw', 'ps', 'psl', 'rlds', 'rlus', 'rlut', 'rlutcs', 'rsdt', 'rsut', 'rsutcs', 'sfcWind', 'ta', 'ts', 'ua', 'uas', 'va', 'vas', 'wap', 'areacello', 'sftof', 'agessc', 'msftbarot', 'msftmrho', 'msftyrho', 'talk', 'volcello', 'wfo', 'zos', 'arag', 'siarean', 'siareas', 'siconca', 'siextentn', 'sivol', 'sivoln', 'sivols', 'sftlf', 'cProduct', 'bigthetao', 'evspsbl', 'msftmz', 'snw', 'basin', 'thkcello', 'dfeos', 'dissicnatos', 'intpp', 'no3os', 'obvfsq', 'phycos', 'po4os', 'tauuo', 'tauvo', 'zostoga', 'hfss', 'rldscs', 'rsds', 'rsdscs', 'rsus', 'rsuscs', 'areacella', 'od550aer'], dtype=object), .... .... ...
Anderson Banihirwe (Aug 11 2020 at 17:51):Let me know if this accomplishes what you want
Anna-Lena Deppenmeier (Aug 11 2020 at 17:53):Thanks Anderson I will try it -- at first glance it seems to be exactly what I was looking for!
Anderson Banihirwe (Aug 11 2020 at 18:01):Great!
By the way, when using the search() method, you may find the require_all_on argument to be useful in some cases: https://intake-esm.readthedocs.io/en/latest/notebooks/tutorial.html#Enhanced-search:-enforce-query-criteria-via-require_all_on-argument
Last updated: May 16 2025 at 17:14 UTC