Anna-Lena Deppenmeier (Mar 13 2020 at 17:02): Anna-Lena Deppenmeier (Mar 13 2020 at 17:02):
Anna-Lena Deppenmeier (Mar 13 2020 at 17:02): Anna-Lena Deppenmeier (Mar 13 2020 at 17:02):Hi all, I am currently trying to process 4D data, i.e. performing a roll operation and cutting a smaller piece out of it, and then saving it to netcdf. This has worked in the past but is not working currently.
I am trying
dscut.chunk(chunks={'nlat':50, 'nlon':50, 'time':1, 'z_t':1}).to_netcdf(path='/glade/scratch/deppenme/C-HIRES/Pacific/iHESP_Pac_CESM_0.1_008301-008312_TEND_TEMP.nc', mode='w', format='NETCDF4')
and have specified
cluster = ncar_jobqueue.NCARCluster(memory = '50GB')
Everytime, one of my multiple workers starts accruing memory load up to ~26GB, and then the cell stops working with the
KilledWorker: ("('open_dataset-5004937b0b94363a0162fe759f5e3597TEND_TEMP-7bdebbf2a030fe15400fc074b2b9ae8f', 0, 0, 0, 0)", <Worker 'tcp://10.12.205.34:40041', memory: 0, processing: 1>)
error.
The size of the dataset dscut is 1.25GB
Anderson Banihirwe (Mar 13 2020 at 18:39):The size of the dataset dscut is 1.25GB
Since the dataset seems to be relatively small (~1.3GB), can you write it directly by bypassing dask's chunking:
dscut.load().to_netcdf(path='/glade/scratch/deppenme/C-HIRES/Pacific/iHESP_Pac_CESM_0.1_008301-008312_TEND_TEMP.nc', mode='w', format='NETCDF4')
Anderson Banihirwe (Mar 13 2020 at 18:42):Everytime, one of my multiple workers starts accruing memory load up to ~26GB, and then the cell stops working with the
KilledWorker: ("('open_dataset-5004937b0b94363a0162fe759f5e3597TEND_TEMP-7bdebbf2a030fe15400fc074b2b9ae8f', 0, 0, 0, 0)", <Worker 'tcp://10.12.205.34:40041', memory: 0, processing: 1>)
error.
The size of the dataset dscut is 1.25GB
If you can put together a reproducible example or provide a link to a notebook/script, I am happy to look into the dask killedWorker issue
Gustavo M Marques (Mar 17 2020 at 14:39):I am having the same issue as @Anna-Lena Deppenmeier. Here is a reproducible example:
https://nbviewer.jupyter.org/gist/gustavo-marques/2a8ab5a0f6135bb1cfa6c91c16bddbe6
Deepak Cherian (Mar 17 2020 at 14:52):Gustavo, can you add this after creating ds1?
import dask import numpy as np for var in ds1.variables: if dask.is_dask_collection(ds1[var]): ds1[var].data = ds1[var].data.map_blocks(np.copy)
adapted from https://github.com/dask/dask/issues/3595#issuecomment-449546228
Gustavo M Marques (Mar 17 2020 at 15:04):Thanks for the suggestion Deepak. I am still getting the same error.
Deepak Cherian (Mar 17 2020 at 16:09):Does it look like memory is blowing up?
Deepak Cherian (Mar 17 2020 at 16:10):(I assumed that was the issue)
Gustavo M Marques (Mar 17 2020 at 16:26):Yes, it does. Here is the error message:
KilledWorker: ("('open_dataset-concatenate-9db462417b1d809952e026b98a806c0a', 1, 0, 0, 0)", <Worker 'tcp://10.12.205.13:40577', name: 9, memory: 0, processing: 1>)
Deepak Cherian (Mar 17 2020 at 16:27):That memory is the number of tasks in the worker's memory waiting to be run. So you'll have to look at the memory usage dashboard plot.
Gustavo M Marques (Mar 17 2020 at 16:43):The memory usage dashboard keeps "blinking". I cannot see the values. I do see that many of the bars become orange before the error message appears.
Deepak Cherian (Mar 17 2020 at 16:46):hmmm... OK I'll take a look this afternoon. This seems to be a common issue, it'd be nice to find a workaround.
Anderson Banihirwe (Mar 18 2020 at 15:31):@Gustavo M Marques & @Deepak Cherian,
I am starting to suspect that there is some issue going on when xr.open_mfdataset() is used in conjunction with dask's distributed:
Below is what I am seeing when I try to write the netcdf file with ds2.load().to_netcdf(path='/glade/scratch/abanihi/test.nc', mode='w', format='NETCDF4') while using the original open_mfdataset()
# read dataset ds = xr.open_mfdataset(path, parallel=True, concat_dim="time", # concatenate along time data_vars='minimal', coords='minimal', compat='override', combine='nested', preprocess=preprocess, ).chunk({"time": 4})
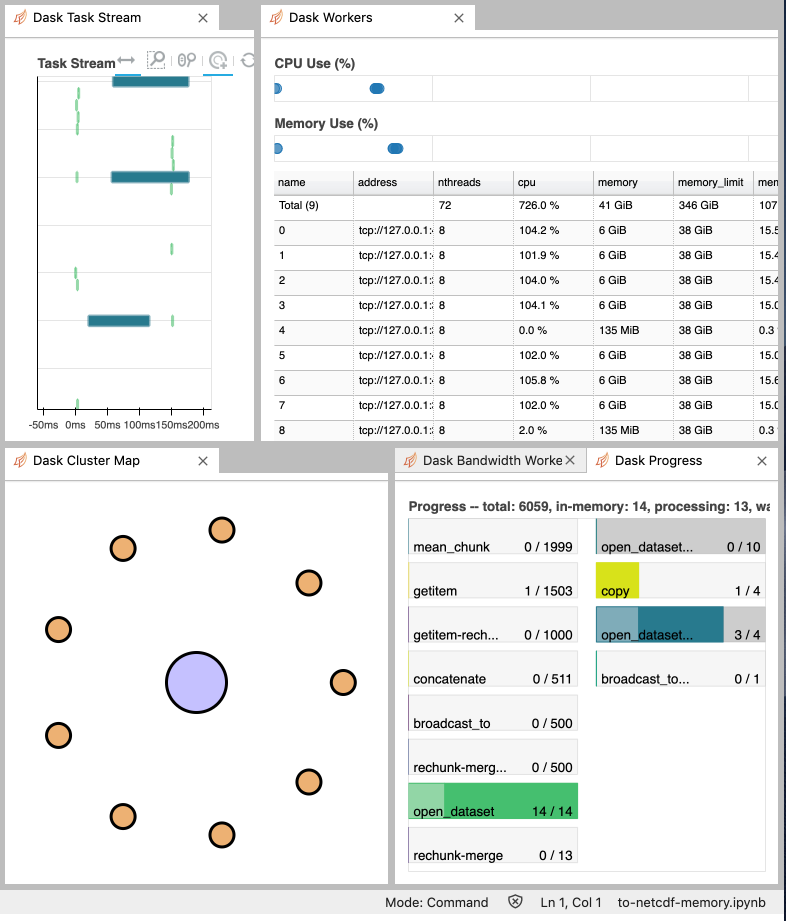
Screen-Shot-2020-03-18-at-9.24.13-AM.png
Anderson Banihirwe (Mar 18 2020 at 15:31):Notice the memory spike on all workers
Anderson Banihirwe (Mar 18 2020 at 15:32):When I try using open_dataset() to read the data, everything works perfectly fine
dsets = [] for path in paths: x = xr.open_dataset(path, chunks={'time': 4}) x = preprocess(x) dsets.append(x) ds = xr.concat(dsets, dim='time')
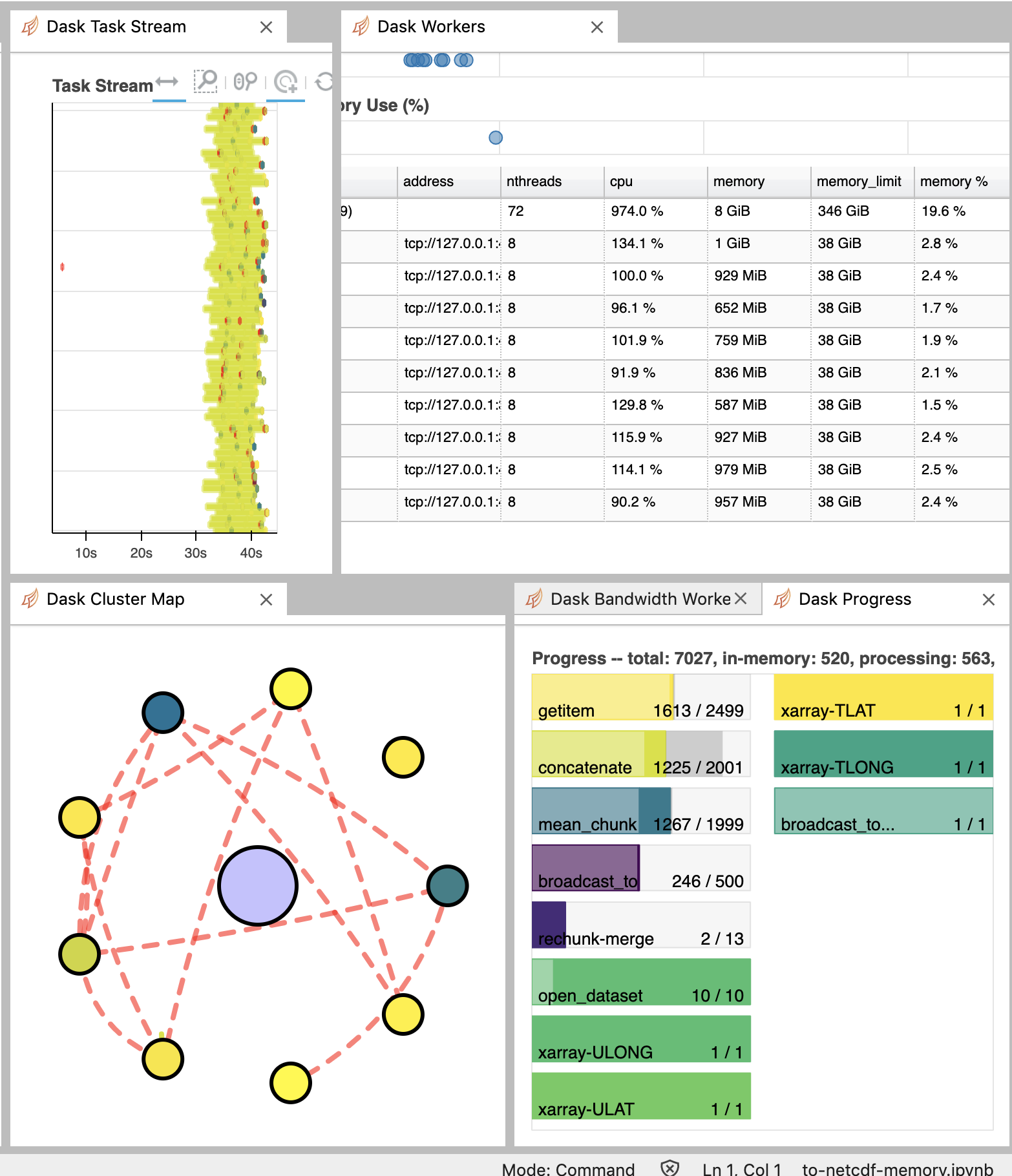
Anderson Banihirwe (Mar 18 2020 at 15:33):Screen-Shot-2020-03-18-at-9.22.11-AM.png
Anna-Lena Deppenmeier (Mar 18 2020 at 15:33):When I try writing to netcdf I see similar memory spikes, after which the worker dies.
Anderson Banihirwe (Mar 18 2020 at 15:34):When I try writing to netcdf I see similar memory spikes, after which the worker dies.
Were you using open_mfdataset() too?
Anna-Lena Deppenmeier (Mar 18 2020 at 15:40):When I try writing to netcdf I see similar memory spikes, after which the worker dies.
Were you using
open_mfdataset()too?
yes
Gustavo M Marques (Mar 18 2020 at 15:44):Thanks for looking at this issue, Anderson. I am going to try your example and see what happens.
Gustavo M Marques (Mar 18 2020 at 15:47):Thanks for looking at this issue, Anderson. I am going to try your example and see what happens.
Once jupyterhub starts working again...
Anna-Lena Deppenmeier (Mar 18 2020 at 15:48):Thanks for looking at this issue, Anderson. I am going to try your example and see what happens.
Once jupyterhub starts working again...
I'm trying to look at it, too, but I can't get allocation on casper, even with ssh.
Deepak Cherian (Mar 18 2020 at 15:53):@Anderson Banihirwe What if you stuck the chunk bit as a kwarg to open_mfdataset
Anderson Banihirwe (Mar 18 2020 at 16:01):Anderson Banihirwe What if you stuck the
chunkbit as a kwarg toopen_mfdataset
# read dataset ds = xr.open_mfdataset(path, parallel=True, concat_dim="time", # concatenate along time data_vars='minimal', coords='minimal', compat='override', combine='nested', preprocess=preprocess, chunks={'time': 4} )
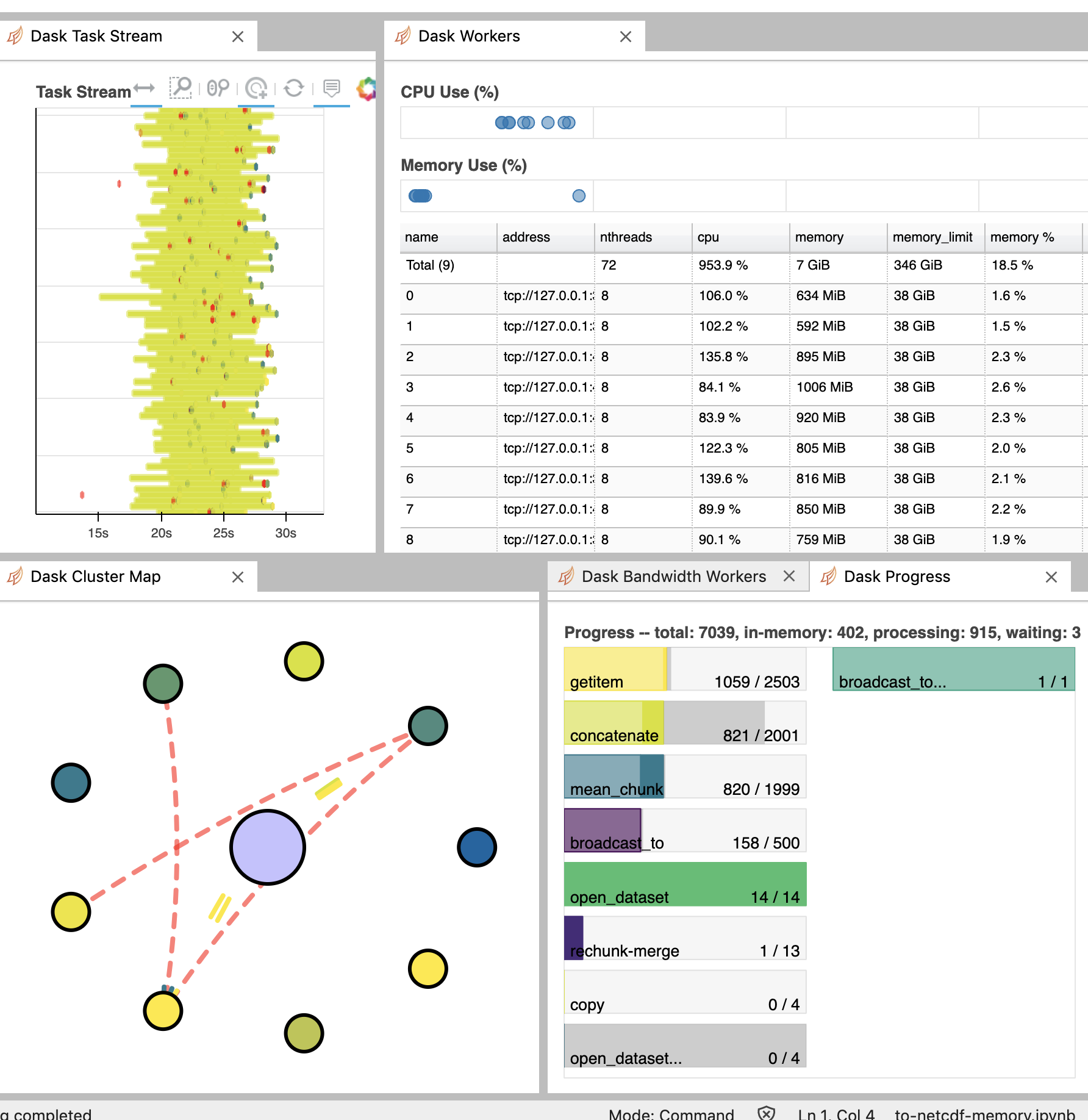
It works and the memory usage looks pretty good :slight_smile:
Screen-Shot-2020-03-18-at-9.58.29-AM.png
P.S.: I hadn't noticed that we were rechunking right after open_mfadataset
Deepak Cherian (Mar 18 2020 at 16:04):Yeah that was pretty subtle. :) cc @Anna-Lena Deppenmeier @Gustavo M Marques
I think dask was loading each fully completely before subsetting to chunk-size-along-dim and that was blowing memory. We have some tips here: https://xarray.pydata.org/en/stable/dask.html#optimization-tips. Should add something about passing chunks to open_mfdataset instead of chunking later.
Gustavo M Marques (Mar 18 2020 at 17:06):It works now! Thanks, @Deepak Cherian and @Anderson Banihirwe. Perhaps It would be helpful to have a tool that does the xarray + dask stuff under the hood (just the data loading part). There are so many "knobs" already that it is hard for users to keep track of everything. Plus, sometimes certain arguments work sometimes they do not. This tool is something I can start working on as a hack-project.
Deepak Cherian (Mar 18 2020 at 20:26):Yeah I don't know how useful yet-another-package would be. intake-esm handles (or will handle) all the published datasets.
For the others: At some point you have to know how to load data into xarray. A number of options in that open_mfdataset call could be removed if xarray changes its defaults to be more sensible which is something we want to do but no one has done yet (https://github.com/pydata/xarray/issues/2064#issuecomment-531818131)
Gustavo M Marques (Mar 18 2020 at 22:44):Yeah I don't know how useful yet-another-package would be.
intake-esmhandles (or will handle) all the published datasets.For the others: At some point you have to know how to load data into xarray. A number of options in that
open_mfdatasetcall could be removed if xarray changes its defaults to be more sensible which is something we want to do but no one has done yet (https://github.com/pydata/xarray/issues/2064#issuecomment-531818131)
I see your point, thanks for the feedback. Something else that could be done 'automatically' is the chunking part. This might be really hard to generalize and at some point, again, the user might have to know how to specify the chunk sizes for certain purposes. I will focus on writing a model that can be used in mom6-tools for now.
Deepak Cherian (Mar 18 2020 at 22:47):Yeah the appropriate chunk size depends on what you want to do with the data so it's really hard to generalize. Again, you have to learn by trial and error unfortunately
Last updated: May 16 2025 at 17:14 UTC