Stephen Yeager (Oct 25 2021 at 18:12): Stephen Yeager (Oct 25 2021 at 18:12):
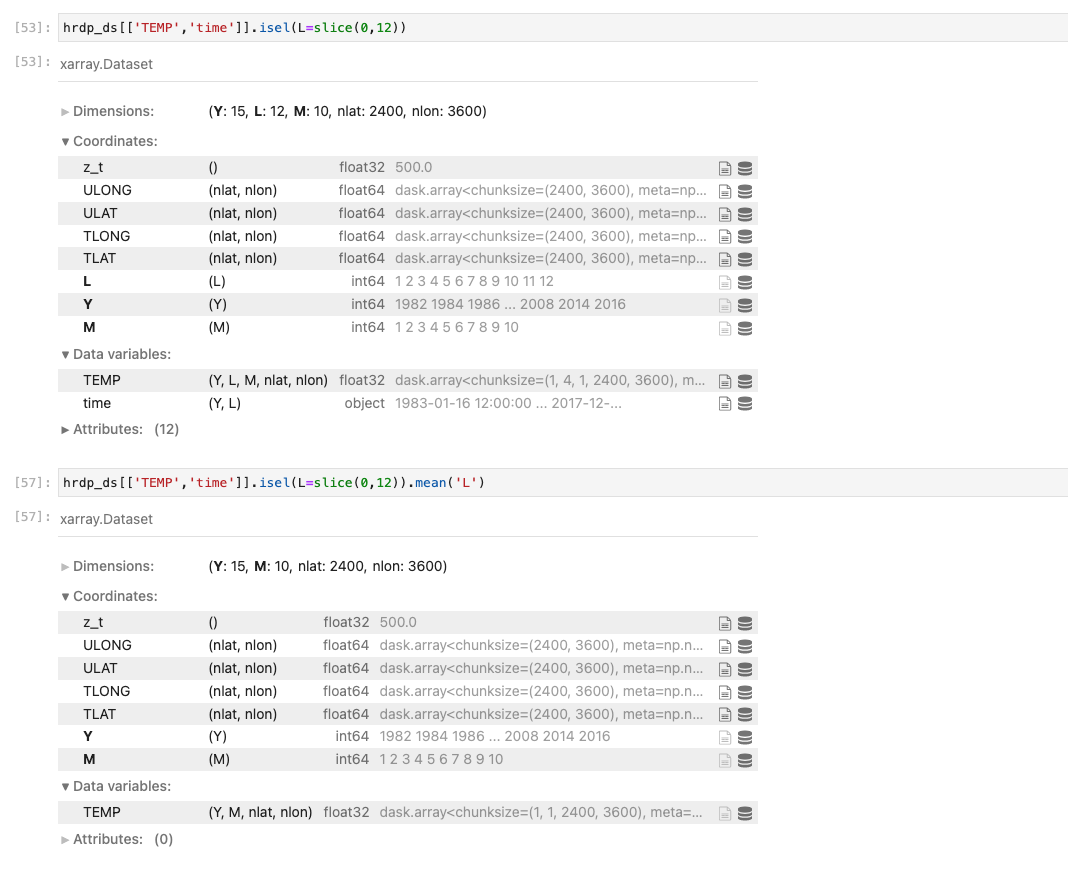
Stephen Yeager (Oct 25 2021 at 18:12): Stephen Yeager (Oct 25 2021 at 18:12):I have a dataset with two variables that have an 'L' dimension, and I want to take the mean over a slice of 'L'. One of these variables ("time") is an array of cftime objects. Here, "time" is a variable, not a coordinate, because this is an initialized prediction dataset. When I apply the 'mean' method, the "time" variable gets dropped from the dataset for some reason:
hrdp_ds[['TEMP','time']].isel(L=slice(0,12)).mean('L')
However, the mean method does work when applied to "time". The following returns good values that I want included in the dataset:
hrdp_ds.time.isel(L=slice(0,12)).mean('L')
Screen-Shot-2021-10-25-at-12.04.01-PM.png
Anderson Banihirwe (Oct 25 2021 at 20:10):When I apply the 'mean' method, the "time" variable gets dropped from the dataset for some reason:
Reduce methods such as mean drop non-numeric data variables ( ref)
Since you are reducing over dim='L', any non-numeric data variables with this dimension are going to be dropped prior to applying the mean.
Anderson Banihirwe (Oct 25 2021 at 20:16):Note that this happens when invoking reduce methods on xr.Dataset. You should be able to get the mean for the time dataarray:
Anderson Banihirwe (Oct 25 2021 at 20:16):temp_ds = hrdp_ds[['TEMP', 'time']].isel(L=slice(0, 12))
result = temp_ds.mean('L')
result['time'] = temp_ds.time.mean('L')
Thanks. I think this would be useful information to include here: http://xarray.pydata.org/en/stable/generated/xarray.Dataset.mean.html?highlight=mean
Last updated: May 16 2025 at 17:14 UTC