Matt Long (Feb 26 2020 at 22:33): Matt Long (Feb 26 2020 at 22:33):
Matt Long (Feb 26 2020 at 22:33): Matt Long (Feb 26 2020 at 22:33):I think we want to have a relatively paired down output suite to keep the model cost down. @Keith Lindsay, do you have a Google Sheet on hand with the model output fields that we can use as a basis for discussion.
We can consider re-running periods with higher-frequency output if necessary.
How much storage do we have?
Keith Lindsay (Feb 28 2020 at 00:13):We do not have dedicated storage. Output has to fit into existing storage allocations.
The largest appropriate location is /glade/campaign/cesm, which currently has 366 TB available.
This is for all of CESM, we don't get all of it. I'm just posting it for reference.
I can't find an existing sheet with the current list of output fields. I'll make one.
Keith Lindsay (Feb 28 2020 at 04:34):I've got an initial attempt at google sheet of ocean output from a gx1v7 case at
https://docs.google.com/spreadsheets/d/1exAFCkXmIhqn-Pws8qMqgmogwQM9xPhb40lxIP-LllI/edit?usp=sharing
I included physics and BGC variables.
I made a separate sheet for each frequency and another sheet summarizing output size.
The output size does not take compression into account.
The physics variables in the sheet are based on gx1v7 defaults. My next step is to replace these with tx1v3 defaults.
Keith Lindsay (Feb 28 2020 at 05:56):I've now marked physics fields not output at tx1v3 as such.
The spreadsheet has an on/off column with values 1/0 respectively.
So the non-output fields are still in the spreadsheet, but don't contribute to the storage.
Matt Long (Mar 11 2020 at 16:30):@all, in the context of planning an output suite, let's enumerate a list of potential applications for this run
Please reply to this thread with additional ideas.
Dan Whitt (Mar 11 2020 at 19:44):Some thoughts:
General comment:
I suggest we follow a similar approach to the JRA physics case, in which we output monthly 3D fields for most of the run, then more thorough and high-frequency output over a select period of with length ~20-25 years, maybe 1996-2019 to span a few key ENSO cycles.
Applications:
- ocean boundary conditions for submesoscale regional simulations.
5-day 3D output would be helpful if we want to use this directly without branching with different outputs or having a very large box.
but 5-day (U,V,T,S,SSH) and monthly BGC fields could potentially help this application too.
In the case we want to branch and re-run, at least annual restarts would help.
physical drivers of BGC variability in coastal and boundary current regions; we probably want at least 5-day output in these dynamic regions, otherwise we're left with a pretty indirect picture of the oceanic variability.
global to regional bgc response to climate variability in general (ENSO, NAO, PDO, SAM, AMV, IOD, etc.); role of mesoscale processes (e.g. TIV/ENSO/O2 in the tropical pacific). Again, 5-day output for a select period of the run would be helpful.
BGC impacts of small-scale/short-lived atmospheric phenomena such as synoptic storms, atmospheric fronts, hurricanes, etc. that are newly resolved in JRA55do; also some air-sea-ice interactions at the ocean mesoscale (eddy/wind interactions); these applications could benefit from high-frequency 3-hour surface currents, SST, MLD and BLT, surface fluxes of heat, momentum and gases, surface chlorophyll and surface inorganic nutrients (ALK,DIC,Fe,Si,P,N,pO2,pCO2). These atmospheric features move quickly, and the ocean physical response is also quick!
Daily output for some 2D variables that reflect BGC rates: e.g. integrated organic carbon in different pools, primary productivity maybe "J" terms integrated over 50 m and 150 m (a lot of remin occurs between 50 and 150, top 50 is mostly prod). The sub-daily response will be largely associated with physical transport, so probably not necessary for BGC rates.
Again, I think this could be done for a ~20 year subset of the run.
-I'd like to see 3D poc flux fields at least monthly, so we can study how export depth horizon impacts export questions (e.g., Hillary Palevsky's work)
Matt Long (Apr 16 2020 at 21:11):@all the output spreadsheet (mainly thanks to the efforts of @Keith Lindsay) has been dialed in with a proposed output suite:
https://docs.google.com/spreadsheets/d/1exAFCkXmIhqn-Pws8qMqgmogwQM9xPhb40lxIP-LllI/edit?usp=sharing
Comments welcome.
Dan Whitt (Apr 17 2020 at 00:15):One comment: Cutting the 3-D, 5-day U,V,T,S to 15 levels might be a useful savings of 10% of the storage requirement. Not clear to me that high-frequency deep physical fields will be of much use without any corresponding high-frequency BGC variables, and physics questions can be addressed with existing physics-only runs
Frank Bryan (Apr 17 2020 at 00:38):Small potatoes for storage, but we do not have the EBM exchange flow turned on in 0.1 deg, so you do not need
S_FLUX_EXCH_INTRF
T_FLUX_EXCH_INTRF
We do have the vertical spreading of river flux turned on so you do need the other EBM terms.
I tend to agree with Dan that we have lots of other sources of output for 5 day full column physics. However, we might consider a "special sampling period" late in the run or a re-run of a short segment with some special physics sampling. Anna and I have talked with Yassir about applying her diapycnal mass flux analysis to oxygen budgets. That would require 5-day output at least through the depth of the O2 min zone.
Dan Whitt (Apr 17 2020 at 00:44):I agree with Frank; some period of the run with 5-day output that includes key BGC variables at the same 5-day frequency, e.g. deeper nuts. + O2, DIC, etc. could add substantial value.
Another comment with reductions in mind. This one is more speculative, but so be it:
I think the 3-D 5-day ecosys. vars are good candidates for reduction right now.
I'm not convinced we need 3-D structure for so many different constituents for each PFTs, right now: Chl,C,Fe,P,Si,CaCO3.
Corresponding depth-integrals for most of these would probably be sufficient for most questions, together with a select number of 3D (15-level) fields.
Perhaps the most extreme reduction in this spirit would be to drop the 3D fields to just total chl and then spC, diazC, and diatC? That would produce another ~10% overall reduction in the storage requirement. But, less extreme cuts to 5-day 3D ecosys. vars would be worth considering...
Yassir Eddebbar (Apr 18 2020 at 01:33): Michael Levy (Jul 06 2020 at 19:43):I've gone through the spreadsheet mentioned above, and produced a sample contents file that assumes 6 streams:
# 1: monthly (physics and BGC) # 2: daily (physics) # 3: daily (BGC) # 4: annual (BGC) # 5: 5-day (physics) # 6: 5-day (BGC)
I don't know if this is really the best way to divide up the output, though. There are only 4 physics fields being output daily, and another 4 in the 5-day category, so maybe it makes sense to combine streams 2 & 3 into a single daily stream, and combine streams 5 and 6 into a single 5-day stream? That would be
# 1: monthly # 2: daily # 3: annual # 4: 5-day
Or maybe it's worth breaking the monthly stream into two files? (There are 50 physics fields and 219 BGC fields in the monthly stream).
@Keith Lindsay and I talked about only turning the 5-day stream on for the last 20 years of the run, which I plan to manage via user_nl_pop:
n_tavg_streams = 4 ltavg_ignore_extra_streams = .true.
Hence my insistence that 5-day be the last stream(s).
Michael Levy (Jul 06 2020 at 19:46):Oh, I should mention two things:
tavg_contents_override_file in user_nl_pop, which is a mechanism to say "use this specific tavg_contents file rather than the one auto-generated by ocn.*.tavg.csh/glade/work/mlevy/hi-res_BGC_JRA/tx0.1v3_tavg_contents -- I haven't yet done a test run to see what performance numbers look like (and it's possible I'll uncover some typos during initialization) Matt Long (Jul 06 2020 at 22:26):@Michael Levy,
I think it's preferable to consolidate variables into streams by frequency (i.e., have the fewest possible streams) unless there are significant performance (or other technical) implications associated with (possibly very) large files.
@Jim Edwards, will the model run slower writing more data to a single file? Mike can probably give you a quick estimate of file size—but I am guessing >100 GB.
Very large files may also impact analysis workflows. @Keith Lindsay, do you have insight on this?
I could imagine that if performance issues are a concern that the daily and 5-day streams can be consolidated, but we might what to split up the monthly.
Keith Lindsay (Jul 06 2020 at 22:59):I'm fine consolidating daily and 5-day streams. That said, I was expecting that we were going to convert history files to single variable timeseries files. If so, we would control file size for analysis by how many time slices are in each file.
Having input from @Jim Edwards on impacts of large history files on I/O performance would still be useful.
Michael Levy (Jul 06 2020 at 23:29):Is there a convention for what to use for tavg_file_freq and tavg_file_freq_opt for the 5-day averages? It seems like the options are "write a new file every five days", or "write a new file every year"; we're expected ~380 GB / sim-yr, so I suspect it would be better to write a new (5.2 GB) file every five days, but I want to make sure I'm not missing a third option
Keith Lindsay (Jul 06 2020 at 23:59):I suggest 1 new file every 5 days, particularly because I'd like to add some more z_t_150m fields.
Matt Long (Jul 07 2020 at 00:38):That said, I was expecting that we were going to convert history files to single variable timeseries files. If so, we would control file size for analysis by how many time slices are in each file.
Single variable timeseries files are an option—and preferable in some respects. However, a single 3D var at monthly resolution is about 24 GB/yr, so we probably will want to make timeseries with 5 years at most?
Michael Levy (Jul 07 2020 at 00:42):Something that came to mind as my one-month job was waiting in the queue -- we're running with coccolithophores, but the spreadsheet is based on the 3-autotroph model; besides missing all the cocco-based variables, we'll run into problems with spCaCo3_zint_100m and spCaCO3 not being defined. As a first pass, I'll duplicate all the sp variables for cocco and remove the sp calcification-related variables just to (hopefully) get the first month run overnight
Keith Lindsay (Jul 07 2020 at 01:48):@Matt Long , @Michael Levy was going to verify what was done for the non-BGC high-res JRA run for timeseries files.
Keith Lindsay (Jul 07 2020 at 01:50):@Michael Levy , yes, the spreadsheet needs to be updated for explicit coccolithophores. I've never done a run with explicit coccolithophores, so I'm not sure what fields are added/removed.
Matt Long (Jul 07 2020 at 01:55):I am pretty sure the physics-only JRA run was not made into timeseries files. I played around with timeseries files for my previous run, but the files become very large quickly. I had 5-day output, for instance, and found that concatenating a year (73 time levels) yielded files that were too big.
We don't necessarily need to answer this question now...
Michael Levy (Jul 07 2020 at 02:10):Michael Levy , yes, the spreadsheet needs to be updated for explicit coccolithophores. I've never done a run with explicit coccolithophores, so I'm not sure what fields are added/removed.
I can update the spreadsheet tomorrow; comparing ecosys_tavg_contents from a run without cocco to a run with cocco, it looks like what I outlined above:
I'll duplicate all the
spvariables forcoccoand remove thespcalcification-related variables
Is the default behavior, but I'll use the ecosys_tavg_contents diffs to guide what I do in the spreadsheet.
Michael Levy (Jul 07 2020 at 02:12):If what I did was correct, it'll add 7 variables to the monthly stream, 3 to the daily, and 17 to the 5day (but I don't know the breakdown between 2D and 3D fields)
Michael Levy (Jul 07 2020 at 16:27):@Keith Lindsay in the spreadsheet, row 246 is the beginning of the "EBM" section. I thought we were running without the EBM, so should I turn these variables off? Or should I be turning the EBM on for this run?
Keith Lindsay (Jul 07 2020 at 16:38):See Frank's message from Apr 16. EBM is partially on.
Michael Levy (Jul 07 2020 at 16:49):Oh, I see - I'm testing my tavg_contents file in a gx3v7 sandbox because I still have some kinks to work out, and I didn't realize I needed to update the pop namelist to [partially] turn on EBM. Though Frank said
Small potatoes for storage, but we do not have the EBM exchange flow turned on in 0.1 deg, so you do not need
S_FLUX_EXCH_INTRF
T_FLUX_EXCH_INTRF
We do have the vertical spreading of river flux turned on so you do need the other EBM terms.
And those two flux exchange variables are on in the spreadsheet -- I'll turn them off but keep S_FLUX_ROFF_VSF_SRF
Michael Levy (Jul 07 2020 at 19:52):The spreadsheet has been updated to include coccolithophores (and to remove sp calcification diagnostics). After copying all the sp diagnostics and changing sp -> cocco, the only other addition I made was to add cocco_C_lim_Cweight_avg_100m to the 5-day stream and also note that we are turning off cocco_C_lim_surf (which is monthly by default)
Michael Levy (Jul 09 2020 at 14:55):After two days of waiting in the queue, my 1-month run died with
$ cat /glade/scratch/mlevy/g.e22b04.G1850ECOIAF_JRA_HR.TL319_t13.first_month.001/run/cesm.log.3013835.chadmin1.ib0.cheyenne.ucar.edu.200709-084732
MPT: Launch error on r4i4n30.ib0.cheyenne.ucar.edu
MPT ERROR: could not run executable.
(HPE MPT 2.19 02/23/19 05:31:12)
I've been having what I think of as "usual glade issues" (file system slow to react), and I wonder if r4i4n30 just lost track of the directory with cesm.exe? In any event, I've resubmitted the job and also let the CISL help desk know. :fingers_crossed:
Keith Lindsay (Jul 09 2020 at 15:00):For what it's worth, I had 2 running jobs die on cheyenne at about the same time.
Michael Levy (Jul 09 2020 at 15:04):I wonder if the only reason there were enough nodes free to start my job was because so many other jobs got killed
Keith Lindsay (Jul 09 2020 at 15:06):That sounds entirely plausible.
Michael Levy (Jul 09 2020 at 15:09):oh, but the re-launched job is actually going! Through 5 days, so initialization was happy with the tavg_contents_file
Michael Levy (Jul 09 2020 at 15:10):and those first few days look like ~1.15 or 1.2 SYPD
Michael Levy (Jul 09 2020 at 15:33):I guess the big I/O hangup will be writing the monthly history file though... the daily file is writing <1 GB / day, the 5-day is writing 15 GB per day, and the monthly file will be >200 GB
Michael Levy (Jul 09 2020 at 16:54):Argh, made it through Jan 28th and then
6441:MPT ERROR: Assertion failed at ibdev_multirail.c:4328: "0 <= chan->rdma_reads"
6441:MPT ERROR: Rank 6441(g:6441) is aborting with error code 0.
6441: Process ID: 15674, Host: r10i1n11, Program: /glade/scratch/mlevy/g.e22b04.G1850ECOIAF_JRA_HR.TL319_t13.first_month.001/bld/cesm.exe
6441: MPT Version: HPE MPT 2.19 02/23/19 05:30:09
@Keith Lindsay is that similar to the error you got when your two runs crashed? There's a traceback that goes through POP_HaloMod.F90 and PMPI_Waitall, which tracks with network issues causing communication issues. I guess I'll wait till CISL gives the "all clear", but there is daily and 5-day output in /glade/scratch/mlevy/g.e22b04.G1850ECOIAF_JRA_HR.TL319_t13.first_month.001/run
I also noticed that we're getting warnings about breaking conservation:
12037:(Task 11209, block 1) Message from (lon, lat) ( 197.050, -10.295), which is global (i,j) (3071, 1079). Level: 13
12037:(Task 11209, block 1) MARBL WARNING (marbl_interior_tendency_mod:compute_large_detritus_prod): dz*DOP_loss_P_bal= 0.262E-010 exceeds Jint_Ptot_thres= 0.271E-
013
There are 160 warnings from that grid cell, but most of them have dz*DOP_loss_P_bal close to 1e-11 rather than a steady increase in that quantity.
Michael Levy (Jul 09 2020 at 23:34):So one good thing to come of the delays with these timing tests: I realized I was missing some POP tuning updates in my sandbox... I've moved my testing from a sandbox based on cesm2_2_beta04 to one based on cesm2_2_alpha06b and have merged the latest POP tags into my high-res branch. I have four jobs in the queue, all using the latest code (which I've tested on lower resolution runs):
NTASKS_OCN=7577, omitting 5-day stream (but writing many of the variables to the monthly stream instead)NTASKS_OCN=14666, omitting 5-day stream (but writing many of the variables to the monthly stream instead)NTASKS_OCN=7577, writing the 5-day streamNTASKS_OCN=14666, writing the 5-day stream (will NOT be bit-for-bit with the 28 days that ran in /glade/work/mlevy/codes/CESM/cesm2_2_beta04+GECO_JRA_HR/cases/g.e22b04.G1850ECOIAF_JRA_HR.TL319_t13.first_month.001)The first two cases will have CICE's age tracer enabled, though I suspect CICE will still be faster than POP so it won't have any effect on throughput. I remembered to update CICE_CONFIG_OPTS for the last two tests.
Michael Levy (Jul 09 2020 at 23:44):@Keith Lindsay My last concern with setting up these runs is that I'm keeping RUN_TYPE: startup instead of setting up a hybrid run. For the production run, should I be setting up a hybrid off of /glade/campaign/cesm/development/omwg/g.e20.G.TL319_t13.control.001_hfreq_1718/rest/0062-01-01-00000? If so, will the 1-month runs I have queued up still be useful, or should I cancel them all and set up a proper hybrid instead?
Keith Lindsay (Jul 09 2020 at 23:58):I think the startup is fine for these kick the tires runs. The ocean starts 1 coupling interval late, which is just 30 minutes.
Keith Lindsay (Jul 10 2020 at 01:47):For the production run, we do want to start from an existing run.
@Alper Altuntas , my recollection is that we have multiple cycles of JRA-forced hi-res G runs, but I only see out to 0062-01-01 on campaign storage, in the directory /glade/campaign/cesm/development/omwg/g.e20.G.TL319_t13.control.001_hfreq_1718/rest
. Do we have more years, particularly restart files, elsewhere?
Michael Levy (Jul 10 2020 at 13:35):@Keith Lindsay the two runs with NTASKS_OCN=7507 (with and without 5-day output; the run without added fields to monthly) ran over night. I realized ncview isn't really cut out for opening these files :) -- if you have specific fields in mind to look at, I can put together a dask-based notebook for you. Output is in the following run directories:
/glade/scratch/mlevy/g.e22a06b.G1850ECOIAF_JRA_HR.TL319_t13.first_month.004/run/glade/scratch/mlevy/g.e22a06b.G1850ECOIAF_JRA_HR.TL319_t13.first_month.005/runI did a quick sanity check -- the coupling intervals are correct, and the time-step matches Alper's run (though it's weird: 10 full and 1 half step every 30 minutes => full timestep is 171.428571 sec)
Michael Levy (Jul 10 2020 at 13:38):Throughput on those runs were 0.68 SYPD, so I think I'd aim for 3 months in a 10 hour window (they both took just a hair over 3 hours to run, so 4 months in 12 hours is likely doable with very little breathing room for machine-induced slow-downs). The NTASKS=14666 jobs are still in the queue, which make me think the smaller layout is better
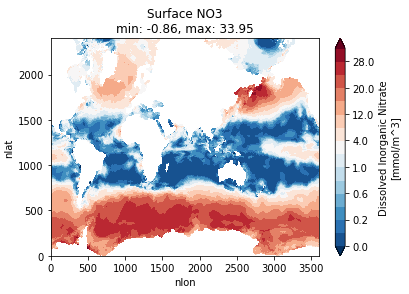
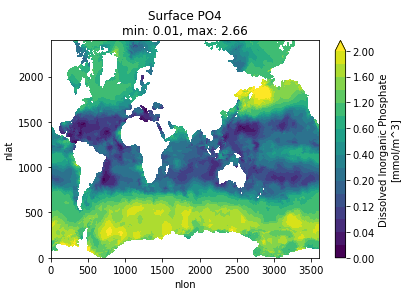
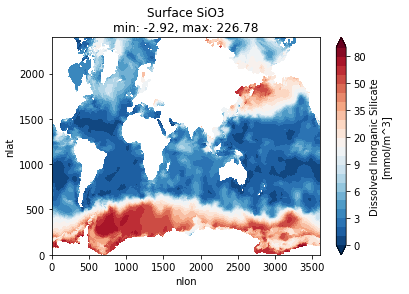
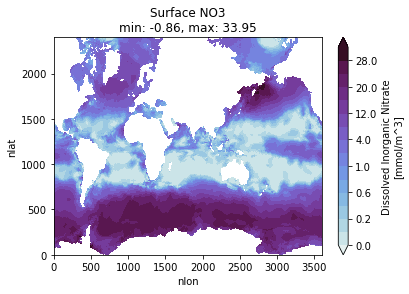
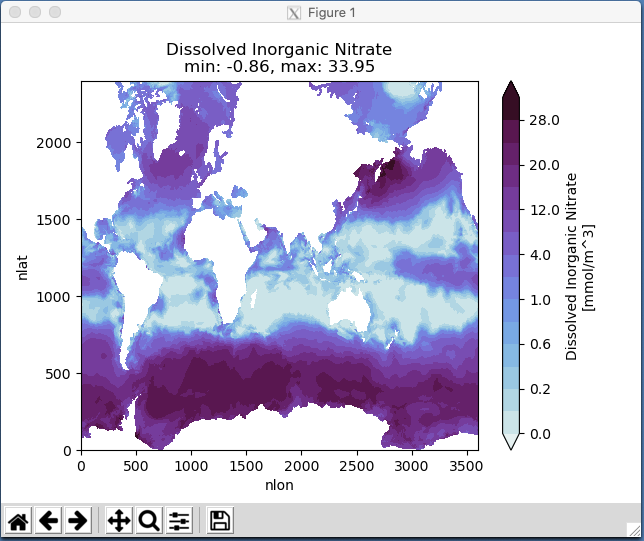
Michael Levy (Jul 10 2020 at 17:02):It looks like xarray on Casper can generate plots without needing to spin up dask, though I've kept the plots on the native grid rather than asking cartopy to make them pretty. Here are some surface nutrients plots as a proof of concept, but I'm happy to [try to] generate other plots / statistics:
As Keith mentioned, this is the "kick the tires" run. Besides setting up our experiment, I was also hoping to put together the final POP tag (move files to inputdata) after we work out any kinks but I'm not sure if the fact that this run has coccolithophores and the out-of-the-box compset will not means I'm trying to get too much out of this run...
Michael Levy (Jul 10 2020 at 17:12):If the following color map is easier to see, I can repost PO4 and SiO3 as well:
Michael Levy (Jul 10 2020 at 22:25):I think glade is supposed to be available throughout the cheyenne downtime (with the exception of Tuesday), but I copied the POP history files from both runs to the CGD space: /project/oce02/mlevy/high-res_BGC_1mo. That directory also has environment.yaml and quick-plot.py; if you run
$ conda env create --name environment.yaml $ conda activate quick-plot
you can use the quick-plot.py script to generate figures similar to the above. Currently the tool relies on x-forwarding and the plot comes to stdout -- it is under version control at https://github.com/mnlevy1981/quick_plot so you can check out the issues page to see what else it lacks :) (And I'm open to suggestions on improvements, if this type thing is useful to others.)
Michael Levy (Jul 10 2020 at 22:26):(Running ./quick-plot.py -h is the closest thing to documentation I have at the moment, sorry!)
Michael Levy (Jul 10 2020 at 22:29):It took about 30s for
$ ./quick-plot.py -v NO3
to draw
so the script name might be considered optimistic by some
Michael Levy (Jul 24 2020 at 15:03):@Keith Lindsay when we were first exploring the NaN bug, you mentioned updating the history file spreadsheet -- I think maybe to replace photoC_TOT with the per-autotroph photoC fields? If there are changes to make, can you update the spreadsheet and then I'll get the tavg_contents files updated? The first three months will probably run with what we have, but my jobs are still queued so there's a chance I can get the file updated before they start running
Keith Lindsay (Jul 25 2020 at 03:18):I have a modified version of tx0.1v3_tavg_contents at /glade/work/klindsay/hi-res_BGC_JRA/tx0.1v3_tavg_contents. Here's a description of the changes:
add photoC_{autotroph} to 5-day
add photoC_NO3_{autotroph} to 1-month
rm photoC_TOT terms
rm photoC_NO3_TOT terms
rm photoC_{autotroph}_zint_100m terms
rm photoNO3_{autotroph} terms
rm photoNH4_{autotroph} terms
Michael Levy (Jul 26 2020 at 18:24):@Keith Lindsay did you mean /glade/work/klindsay/hi-res_BGC_JRA/tx0.1v3_tavg_contents.ktl? The file you mentioned looks identical to the old one. (Also, are these changes reflected in the spreadsheet? I'm unclear about whether this spreadsheet was just a tool to help us get the tavg_contents sorted, or if it'll be kept as part of the documentation of the run -- if the latter, I think it should be updated)
Also, the first 3-month segment of g.e22.G1850ECO_JRA_HR.TL319_g17.001 (WOA for some nutrients) finished overnight. Output is in /glade/scratch/mlevy/archive/g.e22.G1850ECO_JRA_HR.TL319_g17.001/. Unfortunately I didn't check Zulip until just now, so it uses the old tavg contents -- when g.e22.G1850ECO_JRA_HR.TL319_g17.002 (all BGC initial conditions from Kristen's 1-degree run) starts, it'll have the improved output.
Michael Levy (Jul 26 2020 at 18:24):Ugh, and I just realized that I botched the case name
Michael Levy (Jul 26 2020 at 18:24):it should be g.e22.G1850ECO_JRA_HR.TL319_t13.001 (not g17)
Keith Lindsay (Jul 26 2020 at 18:27):I did mean the file with the ktl suffix. I haven't yet updated the spreadsheet to reflect these changes. I do plan on doing that.
Michael Levy (Jul 26 2020 at 18:27):so I'll leave the output from 001 where it is, but between the bad case name and the un-updated tavg I feel like I should start over one more time... unless it makes more sense to branch off the three months that I have and fix the file names for this first three month period by hand? 002 hadn't started yet, so it makes more sense to me to start that one cleanly with the correct case name
Keith Lindsay (Jul 27 2020 at 12:48):I propose
1) branching a new 001 case from the existing 001 case, using the correct case name and updated tavg
2) rename existing 001 tavg files to correct case name
The renaming in 2) eases comparison of drift between 001 and 002. But we don't need the modified output in order to do this comparison. If we end up going with the 001 option then we can rerun the 1st 3 months of the new 001 to get the full consistent tavg output. But don't do that unless we decide that we like 001 better than 002.
If the drifts in 001 and 002 are comparable, then 002 is to 001, because 002's IC are simpler. So I think we'll only go with 001, and need to rerun the 1st 3 months, if it is qualitatively better.
Does that make sense to you?
Michael Levy (Jul 27 2020 at 13:49):Thanks Keith, that does make sense. If we go with 001, I'll plan on re-running the first three months otherwise I'll leave things be.
In other news, 002 crashed after ~4 1/2 hours: /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/run. I didn't see anything informative in the ocn.log file, and the cesm.log looks like maybe a machine glitch:
5397:MPT ERROR: Assertion failed at ibdev_multirail.c:4331: "0 <= chan->queued" 5397:MPT ERROR: Rank 5397(g:5397) is aborting with error code 0. 5397: Process ID: 45050, Host: r10i1n11, Program: /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/cesm.ex e 5397: MPT Version: HPE MPT 2.21 11/28/19 04:21:40 5397: 5397:MPT: --------stack traceback------- ... 5397:MPT: #7 ib_progress_send (vchan=<optimized out>, wc=<optimized out>, 5397:MPT: dom=<optimized out>) at ibdev_multirail.c:4369 5397:MPT: #8 handle_send_completion (wc=<optimized out>, board=<optimized out>, 5397:MPT: dom=<optimized out>) at ibdev_multirail.c:6204 5397:MPT: #9 check_send_queue (dom=dom@entry=0x2b010d633020 <dom_default>) 5397:MPT: at ibdev_multirail.c:6231 5397:MPT: #10 0x00002b010d2756e6 in MPI_SGI_ib_progress ( 5397:MPT: dom=dom@entry=0x2b010d633020 <dom_default>) at ibdev_multirail.c:6753 5397:MPT: #11 0x00002b010d285238 in MPI_SGI_progress_devices ( 5397:MPT: dom=0x2b010d633020 <dom_default>) at progress.c:165 5397:MPT: #12 MPI_SGI_progress (dom=0x2b010d633020 <dom_default>) at progress.c:313 5397:MPT: #13 0x00002b010d28c2e3 in MPI_SGI_request_wait ( 5397:MPT: request=request@entry=0x2b210e6c6c80, status=status@entry=0x2b2108a037c0, 5397:MPT: set=set@entry=0x7ffeb59e97ac, gen_rc=gen_rc@entry=0x7ffeb59e9740) 5397:MPT: at req.c:1666 5397:MPT: #14 0x00002b010d36c158 in MPI_SGI_waitall (array_of_statuses=0x2b2108a037c0, 5397:MPT: array_of_requests=<optimized out>, count=8) at waitall.c:23 5397:MPT: #15 PMPI_Waitall (count=8, array_of_requests=<optimized out>, 5397:MPT: array_of_statuses=0x2b2108a037c0) at waitall.c:80 5397:MPT: #16 0x00002b010d36c4dd in pmpi_waitall__ () 5397:MPT: from /glade/u/apps/ch/opt/mpt/2.21/lib/libmpi.so 5397:MPT: #17 0x000000000086d2bf in pop_halomod_mp_pop_haloupdate2dr8_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/POP_HaloMod.F90:1923 5397:MPT: #18 0x00000000008cc421 in pop_solversmod_mp_pcsi_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/POP_SolversMod.F90:1757 5397:MPT: #19 0x00000000008c7222 in pop_solversmod_mp_pop_solversrun_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/POP_SolversMod.F90:455 5397:MPT: #20 0x00000000008f7047 in barotropic_mp_barotropic_driver_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/barotropic.F90:592 5397:MPT: #21 0x00000000007aad58 in step_mod_mp_step_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/step_mod.F90:437 5397:MPT: #22 0x000000000074827f in ocn_comp_mct_mp_ocn_run_mct_ () 5397:MPT: at /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.002/bld/ocn/source/ocn_comp_mct.F90:649
Maybe I should try the mpt/2.22 module instead of the 2.21 default? I had been inadvertently running with 2.22 all week, because I switched when I was first seeing the errors after Cheyenne's maintenance period and forgot to switch back... after verifying that the two versions were bit-for-bit (comparing restart files from a gx1v7 run), I thought it made sense to switch back to 2.21 because it's the CESM default. That decision was greeted with another Launch error followed by the above.
Keith Lindsay (Jul 27 2020 at 13:50):"then 002 is to 001" should have read "then 002 is preferable to 001".
Oh joy about 002. I'll take a look.
Keith Lindsay (Jul 27 2020 at 13:59):I would only switch to mpt/2.22 if there was evidence that it resolves a problem that we are having. I'm not aware of such evidence, and the initial 001 ran for 3 months without this problem. So I suggest resubmitted 002.
What do you think of setting REST_N=1 to reduce lost time if another crash occurs, but keep DOUT_S_SAVE_INTERIM_RESTART_FILES=FALSE?
Keith Lindsay (Jul 27 2020 at 15:53):@Michael Levy , the following fields are all zeros. Let's omit them from the output.
sp_loss_poc_zint_100m diat_loss_poc_zint_100m diaz_loss_poc_zint_100m
Michael Levy (Jul 27 2020 at 15:55):Sounds good. I've kept the other two loss_poc_zint_100m terms:
$ grep loss_poc_zint tx0.1v3_tavg_contents 4 cocco_loss_poc_zint_100m 4 zoo_loss_poc_zint_100m $ grep loss_poc_zint tx0.1v3_tavg_contents_no5day 1 cocco_loss_poc_zint_100m 1 zoo_loss_poc_zint_100m
Michael Levy (Jul 28 2020 at 16:08):CISL gave me a reservation through Sunday, so my branch off of the poorly-named 001 case has just begun and the 002 rerun should start when it finishes. If all the runs take 10 hours, that's 14 runs (3 1/2 years); best case scenario is that we have 2 years of 001 and 21 months of 002 when the reservation ends and I'm back to being frustrated with the way PBS computes priority but we'll see how the reservation holds up (fingers crossed that the nodes they gave me are stable)
Michael Levy (Jul 28 2020 at 16:10):(I should say that CISL wasn't clear on exactly when the reservation ends... if it runs through 11:59p on Sunday then 14 jobs are possible; if it ends early in the day, that'll obviously mean fewer jobs)
Michael Levy (Jul 28 2020 at 19:56):g.e22.G1850ECO_JRA_HR.TL319_t13.001 crashed in late April with
919:(Task 91, block 1) Message from (lon, lat) ( 339.750, -72.472), which is global (i,j) (898, 143). Level: 1 919:(Task 91, block 1) MARBL ERROR (marbl_diagnostics_mod:store_diagnostics_iron_fluxes): abs(Jint_Fetot)= 0.971E-016 exceeds Jint_Fetot_thres= 0.951E-017 919:(Task 91, block 1) MARBL ERROR (marbl_diagnostics_mod:marbl_diagnostics_interior_tende ncy_compute): Error reported from store_diagnostics_iron_fluxes 919:(Task 91, block 1) MARBL ERROR (marbl_interior_tendency_mod:marbl_interior_tendency_co mpute): Error reported from marbl_diagnostics_interior_tendency_compute() 919:(Task 91, block 1) MARBL ERROR (marbl_interface:interior_tendency_compute): Error repo rted from marbl_interior_tendency_compute() 919:(Task 91, block 1) MARBL ERROR (ecosys_driver:ecosys_driver_set_interior): Error repor ted from marbl_instances(1)%set_interior_forcing()
The daily stream has 24 days of output, so I think the run is initialized correctly (I would have expected bad initial conditions to cause issues sooner in the run); does it make sense to increase Jint_Ctot_thres_molpm2pyr a couple of orders of magnitude, or does this look like the beginning of going off the rails?
Case root: /glade/work/mlevy/hi-res_BGC_JRA/cases/g.e22.G1850ECO_JRA_HR.TL319_t13.001
Run dir: /glade/scratch/mlevy/g.e22.G1850ECO_JRA_HR.TL319_t13.001/run
The re-run of the first three months of 002 is currently in progress, but I'd like to have a run queued up for when it finishes (ETA ~10:30p)
Keith Lindsay (Jul 28 2020 at 20:43):There are also a lot of marbl_co2calc_mod warnings at the same (i,j) location, throughout the water column. This worries me that we might be hitting a CFL problem. This is right off the coast of Antarctica, on the eastern edge of the Wedell Sea.
That said, the immediate cause of the crash is a failed iron conservation check. So let's loosen the criteria on that. Please change the formula for Jint_Fetot_thres to Jint_Fetot_thres = 1.0e2_r8 * parm_Red_Fe_C * Jint_Ctot_thres (in marbl_settings_mod.F90). This should get us past the failed conservation check. Then we cross our fingers that the marbl_co2calc_mod warnings don't become fatal.
Michael Levy (Jul 28 2020 at 22:45):Things are not going well for me on cheyenne... just sent this to CISL help:
I had a job fail and the CESM log was reporting
MPT Warning: 16:24:45: rank 6941: r8i5n13 HCA mlx5_0 port 1 had an IB
timeout with communication to r8i6n6. Attempting to rebuild this
particular connection.There were many warnings, all having trouble with r8i6n6; the output stream from my job says
PBS: job killed: node 219 (r8i6n6.ib0.cheyenne.ucar.edu) requested job die, code 15009
The next job that started up died ~5 minutes in to the run with similar errors:
MPT Warning: 16:32:04: rank 2481: r8i1n28 HCA mlx5_0 port 1 had an IB
timeout with communication to r8i1n30. Attempting to rebuild this
particular connection.and
=>> PBS: job killed: node 70 (r8i1n30.ib0.cheyenne.ucar.edu) requested job die, code 15009
The first run was the re-run of 002, which previously died on Feb 12th and this time made it to Feb 8th. The second was the rerun of 001, which previously made it to Apr 25 and this time didn't get through Apr 1. On the bright side, I have a restart from 0001-02-01 for the 002 run.
Keith Lindsay (Jul 28 2020 at 22:55):sigh
Michael Levy (Jul 28 2020 at 23:32):Okay, new reservation begins at 1:00a and it's contained in a single rack rather than being spread across the machine. 002 will start from February restarts, then 001 will try the April branch again. Both have the marbl_settings_mod.F90 SourceMod to increase Jint_Fetot_thres. :fingers_crossed:
Keith Lindsay (Jul 29 2020 at 16:28):Good news. 002 is now past where 001 had the failed iron conservation check. There is comparable noise in both001 and 002 in the nday1 surface fields right around the location of the abort in 001, at the ice edge. Fingers crossed that 001 will get past this point as well.
Michael Levy (Jul 29 2020 at 17:06):Thanks for checking up on it, Keith! 002 finished successfully ~10 minutes ago, so the first four months of output are in /glade/scratch/mlevy/archive/g.e22.G1850ECO_JRA_HR.TL319_t13.002. 001 is going, and the next 3 months of 002 has been queued up.
The previous crash in 001 came 2 1/2 [wallclock] hours into the run, so I'll check on the run around 1:30
Michael Levy (Jul 29 2020 at 20:06):Looks like 001 crashed again... same grid point, but this time the issue is in the co2 solver
919:(Task 91, block 1) Message from (lon, lat) ( 339.750, -72.472), which is global (i,j) (898, 143). Level: 37 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) it = 4 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) x1,f = 0.2541340E-009 0.7685970E-001 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) x2,f = 0.4027752E-006 0.2731281E-003 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): bounding bracket for pH solution not found 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) dic = 0.2306659E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) ta = 0.2418340E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) pt = 0.1702004E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) sit = 0.2023047E+006 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) temp = 0.7946957E-002 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) salt = 0.3469127E+002 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:comp_htotal): Error reported from drtsafe
Michael Levy (Jul 29 2020 at 20:09):Given that these errors tend to be the canary in the coal mine for when the time step is too large, this lines up with @Keith Lindsay's comment
This worries me that we might be hitting a CFL problem.
From the log
There are 480 full steps each day There are 48 half steps each day There are 528 total steps each day ... Surface tracer time step = 1.714286E+02 seconds
So not quite 3 minutes per time-step; is it worth testing with a smaller time step? If so, how small?
Michael Levy (Jul 29 2020 at 20:13):And we lost 002 to the same error on a neighboring grid point:
919:(Task 91, block 1) Message from (lon, lat) ( 339.850, -72.429), which is global (i,j) (899, 144). Level: 28 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) it = 4 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) x1,f = 0.2463634E-009 0.1500757E+000 919:(Task 91, block 1) MARBL WARNING (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) x2,f = 0.3904597E-006 0.8409355E-004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): bounding bracket for pH solution not found 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) dic = 0.2300371E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) ta = 0.2411414E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) pt = 0.1282488E+004 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) sit = 0.4130503E+006 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) temp = 0.3514307E-001 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:drtsafe): (marbl_co2calc_mod:drtsafe) salt = 0.3466589E+002 919:(Task 91, block 1) MARBL ERROR (marbl_co2calc_mod:comp_htotal): Error reported from drtsafe
002 died on May 5, 001 on Apr 25 (at least, the coupler didn't report getting to May 6 or Apr 26, respectively)
Keith Lindsay (Aug 04 2020 at 19:30):@Matt Long & @Michael Levy , I propose that we have a call to discuss diagnostic/analysis tools for this run. A couple of high priority items to be addressed are: sanity checks, to detect if a run is going off the rails; evaluate drift, to enable decision on moving forward with 003 or 004 (once they are out farther)
What do you think about 1) today @ 4 PM, 2) Wed @ 10 AM, 3) Wed @ 1 PM, 4) Thu AM, 5) Thu PM?
Matt Long (Aug 04 2020 at 19:31):How about Wed, 1p?
Michael Levy (Aug 04 2020 at 19:31):Wed @1 works for me
Keith Lindsay (Aug 04 2020 at 19:38):Invite sent. If anyone else on this channel is interested in participating, the zoom info is
https://ncar-cgd.zoom.us/j/96288619161
Meeting ID: 962 8861 9161
Passcode: 4J4Uw+..
Michael Levy (Aug 05 2020 at 23:16):Per a conversation with @Matt Long and @Keith Lindsay earlier, I've created https://github.com/marbl-ecosys/HiRes-CESM-analysis to provide some quick diagnostics for the high-res run. Main objectives for this package:
I'm focusing first on that first bullet point, and the initial few commits are cleaning up the notebook I linked to last week that plots mix layer depth at a given grid point.
I want to clean up the routines that read data from the various case roots because it's currently hard-coded to only read history files through May, and then I'll work on providing more useful metrics than the HMXL plot.
Matt Long (Aug 20 2020 at 13:27):@Keith Lindsay, I was skimming the output and considering tracer budgets. Did we omit the diagnostic term associated with the Robert Filter tendency? Is the Robert Filter on? It looks like we have the total tendency term.
Keith Lindsay (Aug 20 2020 at 14:48):We are not using the Robert filter. I don't think it has been exercised in a hi-res configuration.
Frank Bryan (Aug 20 2020 at 14:58):There is no need for Robert filter in 0.1 deg because dt << coupling interval, therefore standard averaging timestep scheme is not a problem.
Matt Long (Sep 01 2020 at 15:39):@all, we're considering reshaping our history file output into single-year timeseries files. We have monthly data for 3D vars; a single monthly history file is about ~230 GB now. I think a single year of monthly data for 3D var will be about 24 GB. This seems like a reasonable file size to me. We will also apply lossless compression to the files, which should cut the file size on disk by about a factor of 2.
Does anyone have concerns with this plan? @Frank Bryan, you have expressed concern about using time-series files for hi-res output previously. Do you think this plan is problematic?
Frank Bryan (Sep 01 2020 at 15:48):I think your plan is reasonable. I have not gone down that path primarily because we were more typically working with 5-day output which makes the annual concatenated 3D files unwieldly.
Michael Levy (Sep 01 2020 at 16:12):@Frank Bryan We had some concerns about that, as we do plan on writing some 5-day output late in the run. For the 3D fields we will only write the top 15 levels, though, and I think 73 time samples of those variables would be ~35 GB each. Our analysis tools are okay reading in the monthly history files, so we don't anticipate issues with the time series.
Matt Long (Sep 02 2020 at 18:56):We are coordinating analysis and development of diagnostic output here:
https://github.com/marbl-ecosys/HiRes-CESM-analysis
cc @geocat
Michael Levy (Nov 27 2020 at 16:30):Back in July, @Keith Lindsay recommended the following changes to tavg:
add photoC_{autotroph} to 5-day
add photoC_NO3_{autotroph} to 1-month
rm photoC_TOT terms
rm photoC_NO3_TOT terms
rm photoC_{autotroph}_zint_100m terms
rm photoNO3_{autotroph} terms
rm photoNH4_{autotroph} terms
I just updated the spreadsheet to reflect these changes... I was comparing the number of time series files being produced to the summary tab of the spreadsheet and noticed some discrepancies but I think the problem is that these changes were missing from the spreadsheet (my time series count matches the variables per stream in tavg_contents)
Michael Levy (Nov 27 2020 at 16:48):The spreadsheet also includes changes from this comment:
the following fields are all zeros. Let's omit them from the output.
sp_loss_poc_zint_100m diat_loss_poc_zint_100m diaz_loss_poc_zint_100m
Matt Long (Jan 14 2021 at 18:14):@Michael Levy, can you please make /glade/campaign/cesm/development/bgcwg/projects/hi-res_JRA world readable?
Michael Levy (Jan 14 2021 at 19:33):Michael Levy, can you please make
/glade/campaign/cesm/development/bgcwg/projects/hi-res_JRAworld readable?
Done! I'll probably need to rerun
$ cd /glade/campaign/cesm/development/bgcwg/projects ; chmod -R o+rX hi-res_JRA/
a couple more times before I remember to set the permissions correctly before transferring additional files into the directory...
Last updated: May 16 2025 at 17:14 UTC