Isla Simpson (Apr 01 2024 at 20:06): Isla Simpson (Apr 01 2024 at 20:06):
Isla Simpson (Apr 01 2024 at 20:06): Isla Simpson (Apr 01 2024 at 20:06):Hello, I had a script that was working well a few months ago to do a number of computations on ERA5 model level data. Deepak helped me get this script working and it used to churn through a month of ERA5 data in about half an hour. I haven't changed anything other than the call to open up the PBS cluster which had to be updated, but now it is ridiculously slow. I left it running for 3 hours earlier and it didn't complete the analysis on one day. My script is here:
/glade/u/home/islas/python/sortera5/grabera5zmfluxes_mlev.ipynb
I've tried with both an older environment and a newer environment. My new call to open up the PBS cluster looks like this...
Screen-Shot-2024-04-01-at-2.03.56-PM.png
Can anyone advise me whether there's something inefficient here. Or has something else changed such that the coding practices in the original script are now no longer efficient? The only other thing I can think of is that the data I'm opening is in the rda which moved from /gpfs/fs1 to /glade/campaign. Is it possible that this could have caused the slowdown?
Thanks for any help on this.
Isla Simpson (Apr 01 2024 at 20:40):An update: I think it's the interpolation from hybrid to pressure levels that is taking much longer than it used to. In the past I had tested the timing of that step alone and it was a wall time of 4.83s. I don't know how long that particular step takes now because I'm still waiting for it to finish. But it's definitely longer than 4.83s.
Isla Simpson (Apr 01 2024 at 21:11):I have also tried using the GeoCAT interpolation routines directly and I have the same problem @Katelyn FitzGerald @Orhan Eroglu - can you think of any reason why the interp_hybrid_to_pressure subroutine with extrapolation = True would have slowed down drastically in the last while? It is fast if I set extrapolation = False, but it seems to be much slower with the extrapolation now compared to when I was running these a few months ago.
Orhan Eroglu (Apr 01 2024 at 21:20):Pinging also @Anissa Zacharias from GeoCAT-comp
Isla Simpson (Apr 01 2024 at 21:36):I have been looking at this with @Brian Medeiros and we think it is in the subroutine _vertical_remap_extrap and specifically this line, which seems to be very slow...
output.loc[dict(plev=lev)] = xr.where(
lev <= p_sfc, output.sel(plev=lev),
data.isel(**dict({lev_dim: sfc_index})))
Thanks
Isla Simpson (Apr 01 2024 at 21:49):OK, we have managed to get this to work much faster by adding compute commands to p_sfc, data, output i.e.,
p_sfc = p_sfc.compute()
data = data.compute()
output = output.compute()
after the computation of p_sfc and before "if variable =='temperature'".
This completed in 2.69 seconds whereas before it was taking more than 3 hours (I didn't let it get to completion).
Katelyn FitzGerald (Apr 01 2024 at 23:08):Thanks for letting us know. Anissa is out on PTO, but I can try to take a look.
It definitely looks like there's an issue with how the function works with Dask or at least how Dask is configured here. Do you have info on how you had the PBS cluster set up before?
I did look through the geocat-comp code and didn't see any recent changes of concern, but there is some more complex usage of Dask in this function.
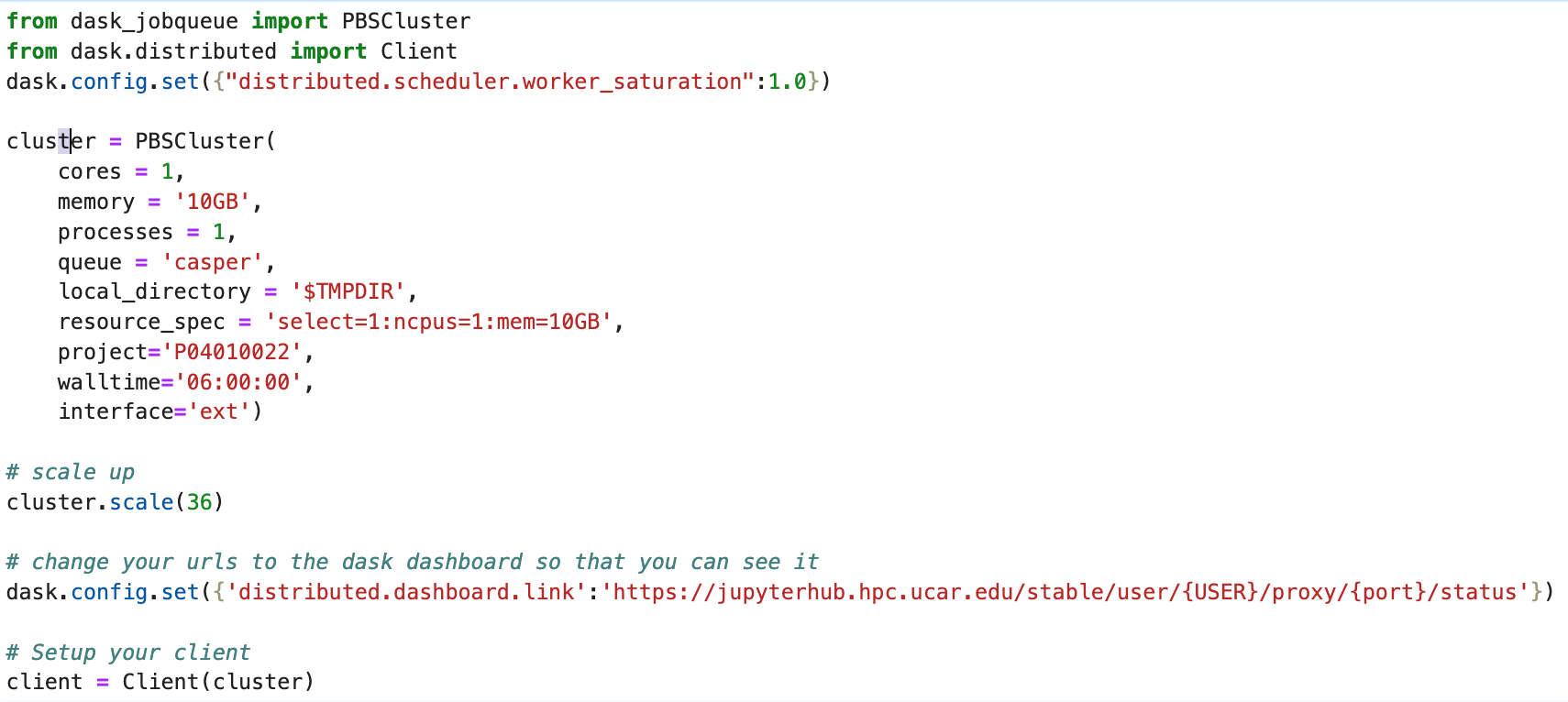
Isla Simpson (Apr 01 2024 at 23:09):Thanks for looking into it. Here is how I had my dask cluster set up before...
from dask_jobqueue import PBSCluster
from dask.distributed import Client
dask.config.set({"distributed.scheduler.worker_saturation":1.0})
cluster = PBSCluster(
cores = 1,
memory = '30GB',
processes = 1,
queue = 'casper',
local_directory = '$TMPDIR',
resource_spec = 'select=1:ncpus=1:mem=20GB',
project='P04010022',
walltime='24:00:00',
interface='ib0')
cluster.scale(36)
dask.config.set({'distributed.dashboard.link':'https://jupyterhub.hpc.ucar.edu/stable/user/{USER}/proxy/{port}/status'})
client = Client(cluster)
Orhan Eroglu (Apr 02 2024 at 17:12):Katelyn FitzGerald said:
Thanks for letting us know. Anissa is out on PTO, but I can try to take a look.
Yeah, just for reference when she's back. Thanks very much for looking into this. FWIW, Dask had a recent release 2024.3.1 that had some changes to Dataframe AFAIK and 2024.4.0 yesterday
Katelyn FitzGerald (Apr 03 2024 at 02:10):A quick update:
I did get a modified example running (yesterday) using NPL 2024a. Thanks for sharing your notebook and example code!
I was hoping to have a more clear answer / path forward by now, but am still trying to better understand what's going on. The dask task graphs in here pretty complex and even when calling .compute() on the arrays the resource usage is very inefficient. There's certainly some stuff we can work on cleaning up that should improve performance, but I haven't identified anything that would have changed in the last few months. And it looks like the Dask changes Orhan mentioned are after the versions included in the NPL envs.
Is it possible you weren't using extrapolate=True before? That would certainly have improved performance.
I'm going to see if I can create a smaller example we can use for benchmarking and try to clean up the dask usage in the function a bit more, but that might take a bit. Maybe we can get someone else to take a quick look as well who has more familiarity with configuring dask on Casper and/or the history of the relevant GeoCAT function.
Isla Simpson (Apr 03 2024 at 13:14):HI Katelyn, Thanks for looking into it. I was definitely using extrapolate = True before. I didn't do anything to my code from the previous time I ran it. The first time I tried to re-run my code I actually wasn't using the geocat function. I was using an old one that I had pulled out of geocat and put in my own script. So my feeling is that its not something that has changed about the geocat code, but rather it's something that has changed about the system or dask as environments have been updated that now causesthe geocat routine to run really slow. In case it's helpful, while I have updated my environment fairly recently, it still appears to be using an older version of dask (2022.2.0). I don't know what it was using back when I had previously run this code, but it was definitely within the last year.
Katelyn FitzGerald (Apr 03 2024 at 15:42):Thanks for the additional details.
I did see something in the notebook referring to the old ncar conda channel for GeoCAT. It looked like you were using your own version of the GeoCAT function like you mentioned so I didn't bring it up earlier, but based on that and the old version of dask you mentioned I wonder if you have some packages in there that might only be preventing newer versions from being installed for compatibility reasons. Let me know if you'd like help with this. It might be easier to just message me directly or set up an ESDS office hours appt.
The other thing I was wondering about are system changes, but I think folks from CSG could probably help better with understanding if anything significant has changed system-wise in the time from before to now. It didn't seem like memory was an issue for dask workers, but like I said the task graphs were quite large (this is something optimization on the geocat side could help with, but it may not have been as much of a problem before if the system resources/config changed). From Jupyter it looked like there might be some issues w/ memory.
Have you spoken with Negin or anyone else from the HPC Research Computing Support - Consulting Services Group?
Isla Simpson (Apr 03 2024 at 20:26):Sounds good. Thanks. I'll email you separately about the dask update issue. I haven't spoken with @Negin Sobhani or anyone else in HPC research computing about this issue. It does seem like there's a chance that some change to the system could be responsible.
Katelyn FitzGerald (Apr 03 2024 at 20:30):I'll see if I can chat with someone from CSG. It'd be good for me to get a better understanding of this (considerations for Dask on HPC) anyway.
Katelyn FitzGerald (Apr 09 2024 at 16:22):It's still a little unclear to me why exactly it would be more problematic now vs. earlier, but I did find some items we can address on the geocat-comp side of things to make this much more performant. I also logged an issue over on the GitHub repo that we'll close once the update has been merged. For now there's a draft PR with some updates that seem to address the core of the problem. We'll try to get this in ASAP.
Let us know if you have any questions and thanks again for reporting this!
Isla Simpson (Apr 09 2024 at 23:53):Great, thanks. I look forward to trying this more performant version. I was trying some other things last week and I seemed to be able to run a script on the machines in CGD relatively quickly without having to add in the .compute(). I wasn't using a dask cluster there though, so maybe that's the difference. But maybe it does point to it being more than inefficiencies in the GeoCAT code or maybe these are inefficiencies that only come into play when using multiple processors with dask.
Last updated: May 16 2025 at 17:14 UTC