Holly Olivarez (Mar 29 2024 at 19:49): Holly Olivarez (Mar 29 2024 at 19:49):
Holly Olivarez (Mar 29 2024 at 19:49): Holly Olivarez (Mar 29 2024 at 19:49):Hi all! Using dask and xr.open_mfdataset, I want to call CESM2-LE monthly DIC output from 185001-201412. What is an efficient way to do this? Previously I only needed two decades so I called one decade a time and concatenated them. Thanks in advance for suggestions and/or script you can share.
Michael Levy (Apr 01 2024 at 14:04):@Holly Olivarez The biggest slowdown is typically in trying to compare common variables among all the files; for CESM output, where you know (for example) that all the grid information is the same in each file, you can use xr.open_mfdataset('*.nc', compat='override', data_vars='minimal', coords='minimal') (the data_vars and coords arguments will prevent the time dimesion from being added to time invariant variables / coordinates). I would recommend being more specific than *.nc in the paths argument :)
Holly Olivarez (Apr 01 2024 at 16:47):@Michael Levy Thanks. My issue, though, is how to type the path in order to get all of those decades at once. I am sorry I wasn't more clear.
Michael Levy (Apr 01 2024 at 17:51):If I'm understanding right, I think it'll be a little tricky to set up (but we can definitely do it) - there are 50 ensemble members, and each one has 165 years of output split over 17 files for the historical period and another 86 years split over 9 files for future runs. Do you want to read in all 1300 files and add a member_id or ensemble_id dimension?
If so, I think you need to do this step by step... start with looping over ensemble members, and for each one use two calls to xr.open_mfdataset() to get separate datasets for the historical and future runs. Then use xr.concat() to concatenate them along the time dimension. Once you have 50 datasets, I think you can use xr.concat() again to create the member_id dimension (but use the data_vars='DIC' to avoid adding the new dimension to every variable).
Holly Olivarez (Apr 01 2024 at 18:42):Thank you for thinking on this with me, Mike! Let me clarify what I am trying to do.
In order to call the first decade from the above list, I used these file names to get:
50 historical cmip6 ensemble members
/b.e21.BHISTcmip6.f09_g17.*.*.pop.h.DIC.199001-199912.nc
and
50 historical smbb ensemble members
/b.e21.BHISTcsmbb.f09_g17.*.*.pop.h.DIC.199001-199912.nc
I did this for each decade listed above and concatenated along the way to create one time series that consisted of 100 ensemble members from 199001-201412.
xr.concat() along the time dimension is great, but would I add that to my script within the parenthesis of the open_mfdataset cell? I haven't done that before. Michael Levy (Apr 01 2024 at 19:25):Thanks for clarifying! Only looking at the historical makes things a bit easier :) It sounds like you have two options:
time to stitch them togethermember_id (which will be created by xr.concat()The first option worked well when you were just looking at three decades, but feels unwieldy when looking at 17 decades. The second option is how I would approach this problem - even though it requires reading 100 ensemble members individually, I'd rather add the new dimension at the very end of the process than trust xarray to organize member_id the same for each of the decades (I mean, it's probably based on file name and therefore consistent, but how would you even tell if member_id=N was one ensemble member prior to 1920 and a different member after?).
It's a little messy because the ensemble members aren't just numbered 001 ... 050, so I needed some messy bookkeeping to track the file names (made messier by different naming conventions for smbb than cmip6). But something like
cmip6_ens_ids = {}
cmip6_ens_ids[1001] = [1]
cmip6_ens_ids[1021] = [2]
cmip6_ens_ids[1041] = [3]
cmip6_ens_ids[1061] = [4]
cmip6_ens_ids[1081] = [5]
cmip6_ens_ids[1101] = [6]
cmip6_ens_ids[1121] = [7]
cmip6_ens_ids[1141] = [8]
cmip6_ens_ids[1161] = [9]
cmip6_ens_ids[1181] = [10]
cmip6_ens_ids[1231] = [1,2,3,4,5,6,7,8,9,10]
cmip6_ens_ids[1251] = [1,2,3,4,5,6,7,8,9,10]
cmip6_ens_ids[1281] = [1,2,3,4,5,6,7,8,9,10]
cmip6_ens_ids[1301] = [1,2,3,4,5,6,7,8,9,10]
smbb_ens_ids = {}
smbb_ens_ids[1011] = [1]
smbb_ens_ids[1031] = [2]
smbb_ens_ids[1051] = [3]
smbb_ens_ids[1071] = [4]
smbb_ens_ids[1091] = [5]
smbb_ens_ids[1111] = [6]
smbb_ens_ids[1131] = [7]
smbb_ens_ids[1151] = [8]
smbb_ens_ids[1171] = [9]
smbb_ens_ids[1191] = [10]
smbb_ens_ids[1231] = [11,12,13,14,15,16,17,18,19,20]
smbb_ens_ids[1251] = [11,12,13,14,15,16,17,18,19,20]
smbb_ens_ids[1281] = [11,12,13,14,15,16,17,18,19,20]
smbb_ens_ids[1301] = [11,12,13,14,15,16,17,18,19,20]
lensdir = '/glade/campaign/cgd/cesm/CESM2-LE/ocn/proc/tseries/month_1/DIC'
ds_list = []
for year in cmip6_ens_ids:
for id in cmip6_ens_ids[year]:
ens_files = f'{lensdir}/b.e21.BHISTcmip6.f09_g17.LE2-{year}.{id:03d}.pop.h.DIC.*.nc'
ds_list.append(xr.open_mfdataset(ens_files, compat='override', data_vars='minimal', coords='minimal')
for year in smbb_ens_ids:
for id in smbb_ens_ids[year]:
ens_files = f'{lensdir}/b.e21.BHISTcsmbb.f09_g17.LE2-{year}.{id:03d}.pop.h.DIC.*.nc'
ds_list.append(xr.open_mfdataset(ens_files, compat='override', data_vars='minimal', coords='minimal')
ds = xr.concat(ds_list, 'member_id', data_vars=['DIC'], coords='minimal', compat='override')
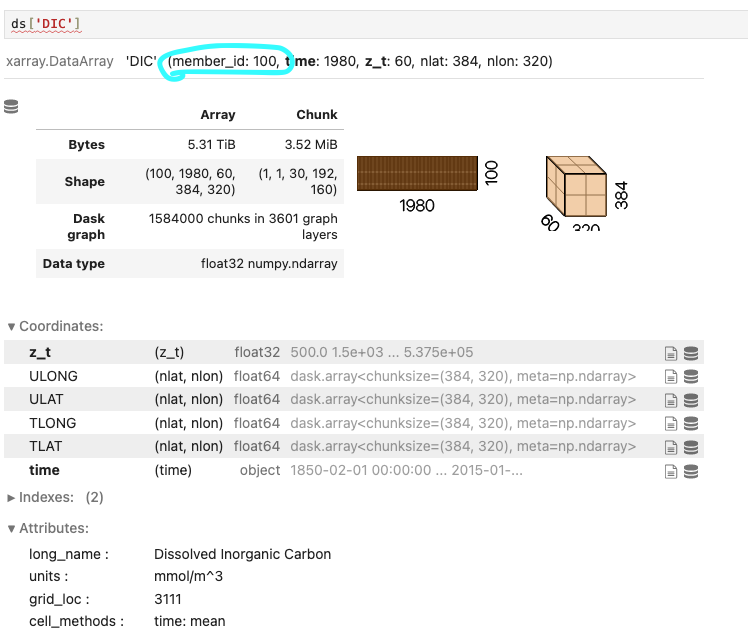
took ~5 minutes to run and resulted in DIC with the correct dimensions:
Michael Levy (Apr 01 2024 at 19:28):It looks like something weird happened with the chunking -- I'd expect time to have chunksize 12 instead of 1, and nlat and nlon to have size 384 and 320, respectively... but lets start with this and see how actually using the data goes
Holly Olivarez (Apr 01 2024 at 19:28):Oh wow, this is great! This is exactly what I was asking for. I am going to try it now. You just taught me something, Mike, and I will be sure to pass it along. Thank you! :grinning_face_with_smiling_eyes:
Michael Levy (Apr 01 2024 at 19:30):note that I just edited the long message; the last line should be
ds = xr.concat(ds_list, 'member_id', data_vars=['DIC'], coords='minimal', compat='override')
to avoid some concatenation errors (the trouble with writing code in zulip and then testing it, rather than testing it first and then copying it over :)
Michael Levy (Apr 01 2024 at 19:39):Okay, it looks like open_mfdataset() needs help with the chunking... I added the chunks={'time': 4, 'nlat': 384, 'nlon': 320, 'z_t': 60} argument to both calls (inside the ds_list.append() calls), which should give you 112.5 MB chunks. Too late for me to go back and edit the long call, though
Holly Olivarez (Apr 01 2024 at 19:54):No problem. Thanks again! I'll follow up if I get stuck anywhere.
Last updated: May 16 2025 at 17:14 UTC