Rudradutt Thaker (Jun 02 2022 at 19:37): Rudradutt Thaker (Jun 02 2022 at 19:37):
Rudradutt Thaker (Jun 02 2022 at 19:37): Rudradutt Thaker (Jun 02 2022 at 19:37):Hey, I am trying to calculate an ensemble mean for CESM2 data which is 1.9TB in size and the final mean is around 50GB. I am using dask to read the data through intake function. I tried different ways and combination of chunks, number of workers, but some of the workers run out of memory and then the entire process freezes. Any suggestions to overcome this?
The data has 40 ensemble members and years from 1850-2015 at 6 hourly interval.
Deepak Cherian (Jun 02 2022 at 21:12):You'll have to "batch" it. Dask is bad about optimizing for memory and will tend to execute more "read-data" tasks than "reduce-data" tasks unfortunately. Are you doing this for multiple variables at the same time? If so, the easiest would be to just loop through the variables and compute them one at a time.
Rudradutt Thaker (Jun 02 2022 at 21:24):I am just doing it for one variable. I am rechunking it so that all the ensemble members are in one chunk, also each chunk is around 85MB in memory. How do I batch it?
Deepak Cherian (Jun 02 2022 at 22:31):Can you not calculate it without rechunking?
Rudradutt Thaker (Jun 02 2022 at 22:46):It can be done without rechunking but then each chunk would be larger. Also, I thought it would be better to keep all the members in one chunk across which the mean is to be taken. Let me try it without rechunking and see. Thanks for the help.
Deepak Cherian (Jun 02 2022 at 22:49):It can be done without rechunking but then each chunk would be larger
In that case control the chunk size at read time along dimensions present in a single file.
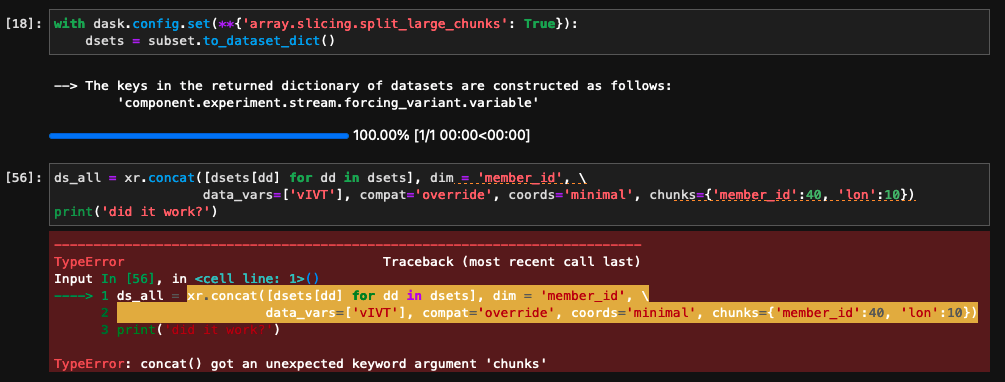
Rudradutt Thaker (Jun 02 2022 at 22:59):I thought of that. The thing is I am reading in files through the intake function, and the way the instruction I am following the files are read in and then concatenated through xr.concat. Now the concat function does not give an option to chunk it while reading in (or does it?).
Deepak Cherian (Jun 02 2022 at 23:09):pass something like chunks={"nlat": 100, "nlon": 100} in cdf_kwargs or zarr_kwargs to chunk along those dimensions
Rudradutt Thaker (Jun 02 2022 at 23:17):That could be helpful and I am sorry but I am confused a little bit. I don't see any syntax regarding chunks in xr.concat. Here is a screenshot if it helps:
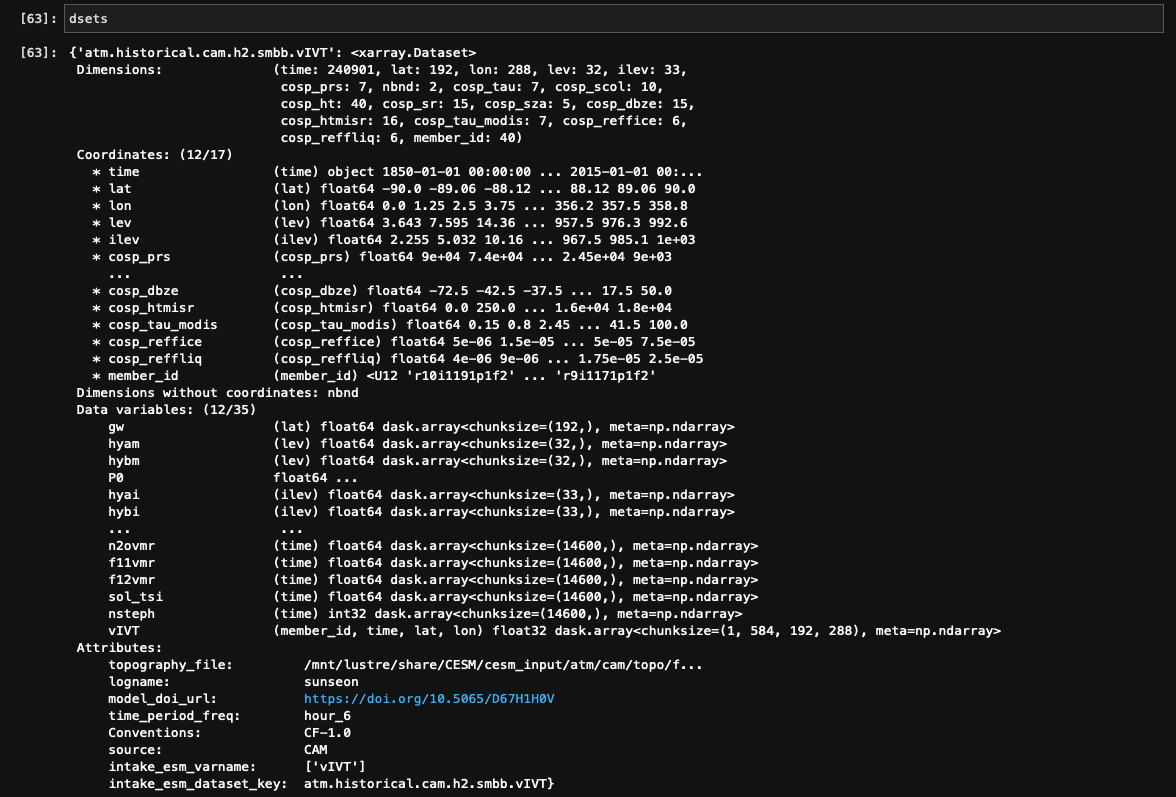
Deepak Cherian (Jun 02 2022 at 23:19):Thanks thats helpful. Can you show me what one ds in dsets looks like. You'll have to pass chunks in to_dataset_dict() not to concat. That will set chunks at read time
Rudradutt Thaker (Jun 02 2022 at 23:32):This is how the dsets look. I tried doing the chunks in the to_dataset_dict but it shows the same error and the reason is that the to_dataset_dict command is an esm command and not xarray.
Also, thank you so much Deepak for helping me with this.
Deepak Cherian (Jun 03 2022 at 15:17):Ah I forgot to mention that you'll need to_dataset_dict(cdf_kwargs={"chunks": ...}). That said this seems to be chunked OK (128MiB). Along which dimensions are you calculating the mean?
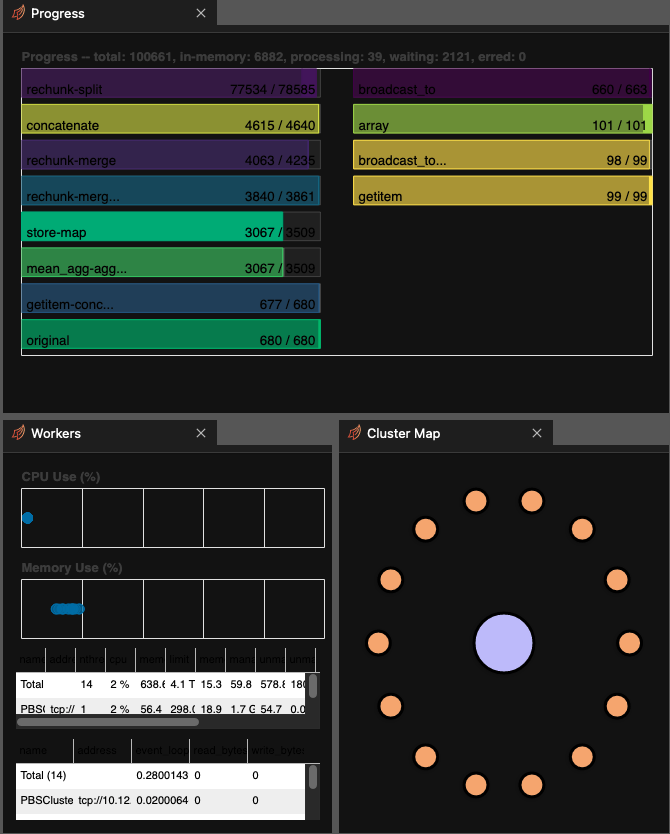
Rudradutt Thaker (Jun 03 2022 at 18:12):That makes sense and I might try that. I tried sub selecting certain longitudes beforehand and that sped up the process for sure. What happens is that near the end of the entire process, even though the memory of workers are at 20% (80% remaining) it would just freeze.
I am calculating the mean along ensemble members. But the data is 6 hourly. I know you are busy but I can meet you on zoom or at NCAR if that would be more convenient. Once again thank you so much for taking out time to help :).
Deepak Cherian (Jun 03 2022 at 18:50):Are you using .compute or .load. If so, the 'freeze' might be that it's sending 50GB of data back to your "head node" and then stitching it together to create an array. Instead you could call to_zarr which would write in parallel as each chunk is done.
Rudradutt Thaker (Jun 03 2022 at 19:38):The final step is saving the file as netcdf on scratch directory and that means it would be invoking .load. I used the cdf_kwargs and it worked. A quick question, where do I put the to_zarr command? I have never used it. Thanks, Deepak.
Deepak Cherian (Jun 03 2022 at 19:40):Replace to_netcdf with to_zarr (and change the extension). If you do need a netCDF file, you can convert it later. parallel writes with zarr work a lot better with dask+distributed in my experience.
Rudradutt Thaker (Jun 03 2022 at 19:40):Awesome. That might just work. I will try it.
Rudradutt Thaker (Jun 03 2022 at 20:03):vivt_ds.to_zarr('/glade/scratch/rudradutt/AR_CESM2/hist_sim/trial.zarr') This is what I wrote. And yet it again froze near the end. It nearly made it and then froze. This is so strange. I have never ran into issues like this.
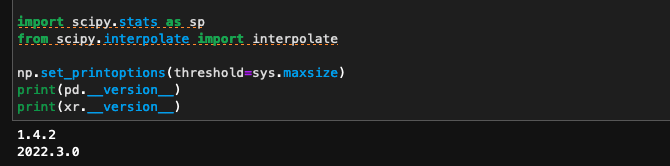
Deepak Cherian (Jun 03 2022 at 20:04):ah really close. Can your print out xarray.show_versions()
Rudradutt Thaker (Jun 03 2022 at 20:05):Yeah sure. It is the v2022.3.0. It is the only one in which the esm-intake function was compatible.
Deepak Cherian (Jun 03 2022 at 20:05):what about dask and distributed. I think that's where the issue lies
Rudradutt Thaker (Jun 03 2022 at 20:07):dask is 2022.05.1
distributed is 2022.5.1
Deepak Cherian (Jun 03 2022 at 20:09):Here's a report of a similar "deadlock": https://github.com/dask/distributed/issues/6493
Maybe try upgrading on downgrading. Sorry I don't have any better solutions.
Rudradutt Thaker (Jun 03 2022 at 20:09):I will try that. And you have been huge help Deepak! Thank you so much.
Rudradutt Thaker (Jun 03 2022 at 22:22):Huh. This was the most annoying thing. It was just an issue with the version of Dask. I am sorry for all the hassle. But thank you so much for all the help and tips, Deepak.
Deepak Cherian (Jun 03 2022 at 22:23):Ah too bad. So to conclude, needed latest dask/distributed and used to_zarr instead of to_netcdf to write output in parallel
Rudradutt Thaker (Jun 03 2022 at 22:27):Yeah. Phew!! And to_netcdf also works perfectly fine.
Last updated: May 16 2025 at 17:14 UTC