Brian Vanderwende (Jun 15 2023 at 21:22): Brian Vanderwende (Jun 15 2023 at 21:22):
Brian Vanderwende (Jun 15 2023 at 21:22): Brian Vanderwende (Jun 15 2023 at 21:22):Hello all - I'm following up on a report from @Elena Romashkova that there has been flaky/unstable behavior observed by her colleagues on Casper recently (perhaps specific to Dask workflows - which is why I am posting it here). If you have been noticing this too, it'd be helpful to us in HPCD if you can share any descriptions of what you have seen. For example:
- What sorts of failures or weird behavior are you seeing now that you didn't see (or saw less) before?
- How long have you noticed the problem?
- Is it particular to a type/amount of resource or time of day?
- Have you found any helpful mitigations?
Anything else you'd like to share is welcome, of course. Thanks in advance!
Lev Romashkov (Jun 15 2023 at 21:23):Brian Vanderwende said:
Hello all - I'm following up on a report from Elena Romashkova that there has been flaky/unstable behavior observed by her colleagues on Casper recently (perhaps specific to Dask workflows - which is why I am posting it here). If you have been noticing this too, it'd be helpful to us in HPCD if you can share any descriptions of what you have seen. For example:
- What sorts of failures or weird behavior are you seeing now that you didn't see (or saw less) before?
- How long have you noticed the problem?
- Is it particular to a type/amount of resource or time of day?
- Have you found any helpful mitigations?Anything else you'd like to share is welcome, of course. Thanks in advance!
cc @Michael Levy @Kristen Krumhardt @Deepak Cherian
Michael Levy (Jun 15 2023 at 22:13):@Brian Vanderwende This is the same notebook tripping @Elena Romashkova up, but I figured I'd write up the details for others to see.
Back in January, I was able to run a notebook that requested 72 workers (each worker was a single core with 20 GB of memory). Tuesday afternoon I tried to run the same notebook in the same environment, and got unexpected behavior spinning up the cluster:
cluster.scale(72) command took several minutes to finishqstat from a terminal and see workers get submitted to the queue (slowly)OSError: Timed out trying to connect to tcp://10.12.206.56:38276 after 30 sThe end result is that after a few minutes, the cell running cluster.scale(72) would finish but I'd have less than 10 workers running and there wouldn't be any more queued up.
cluster.scale(1) or cluster.scale(2) seemed to work fine, which made me wonder if I should just do something like
for count in range(1,73,1):
cluster.scale(count)
But I never got desperate enough to try it. (Instead I started playing around with trying to reduce the number of jobs I submitted to get 72 workers, e.g. asking for 9 cores and 180 GB memory per worker, but I was having trouble figuring out how to have dask do that).
Deepak Cherian (Jun 15 2023 at 22:47):During one of Elena's experiments with fixing this, she passed interface="mgt" (I think) to PBSCluster. Debugging with that, we concluded that the dask workers couldn't talk to the scheduler and would give up with TimeoutError. Changing to interface="ib0" fixed it at that point, and seemed to decrease frequency of errors in the next couple of weeks.
When looking at Mike's notebooks, I saw the same TimeoutError. Is it possible that it's an intermittent network issue?
Anna-Lena Deppenmeier (Jun 16 2023 at 16:34):I am also experiencing lots of flaky notebook behaviour, and I have interface='ib0' specified. I have started to play with cluster.scale() instead of cluster.adapt() and that seemed to help for a while, but yesterday it got stuck on one of my calculations again that really shouldn't have been an issue
Anna-Lena Deppenmeier (Jun 16 2023 at 17:05):And just now I am getting another error I have seen often recently:
OSError: [Errno -51] NetCDF: Unknown file format: b'/glade/campaign/cgd/oce/projects/FOSI_BGC/HR/g.e22.TL319_t13.G1850ECOIAF_JRA_HR.4p2z.001/ocn/proc/tseries/day_1/g.e22.TL319_t13.G1850ECOIAF_JRA_HR.4p2z.001.pop.h.nday1.SST.19700102-19710101.nc'
even though the file is there and also this cell ran without problems yesterday.
(edit: and now it just executed without changing anything)
Anna-Lena Deppenmeier (Jun 16 2023 at 17:54):Similarly currently I am trying to take a mean over some data and plot it, this has worked just a couple of minutes ago, but now it is not doing anything, and I don't even see any workers queueing, plus casper doesn't look that full. (I just keep adding to this thread with things as they come up, is this helpful or should I send an email to the helpdesk?)
Holly Olivarez (Jun 16 2023 at 17:55):I say keep posting here as you are not the only one encountering odd behavior!
Anna-Lena Deppenmeier (Jun 16 2023 at 17:58):And just to clarify what's happening right now: I have processes waiting that I can see on the dashboard, but no workers are being submitted or started. Usually at this point I expect to be able to see the queueing workers but there are none. qstat only shows my login.
Anna-Lena Deppenmeier (Jun 16 2023 at 18:56):it's still exactly the same as I left it before lunch. any advice on what to do?
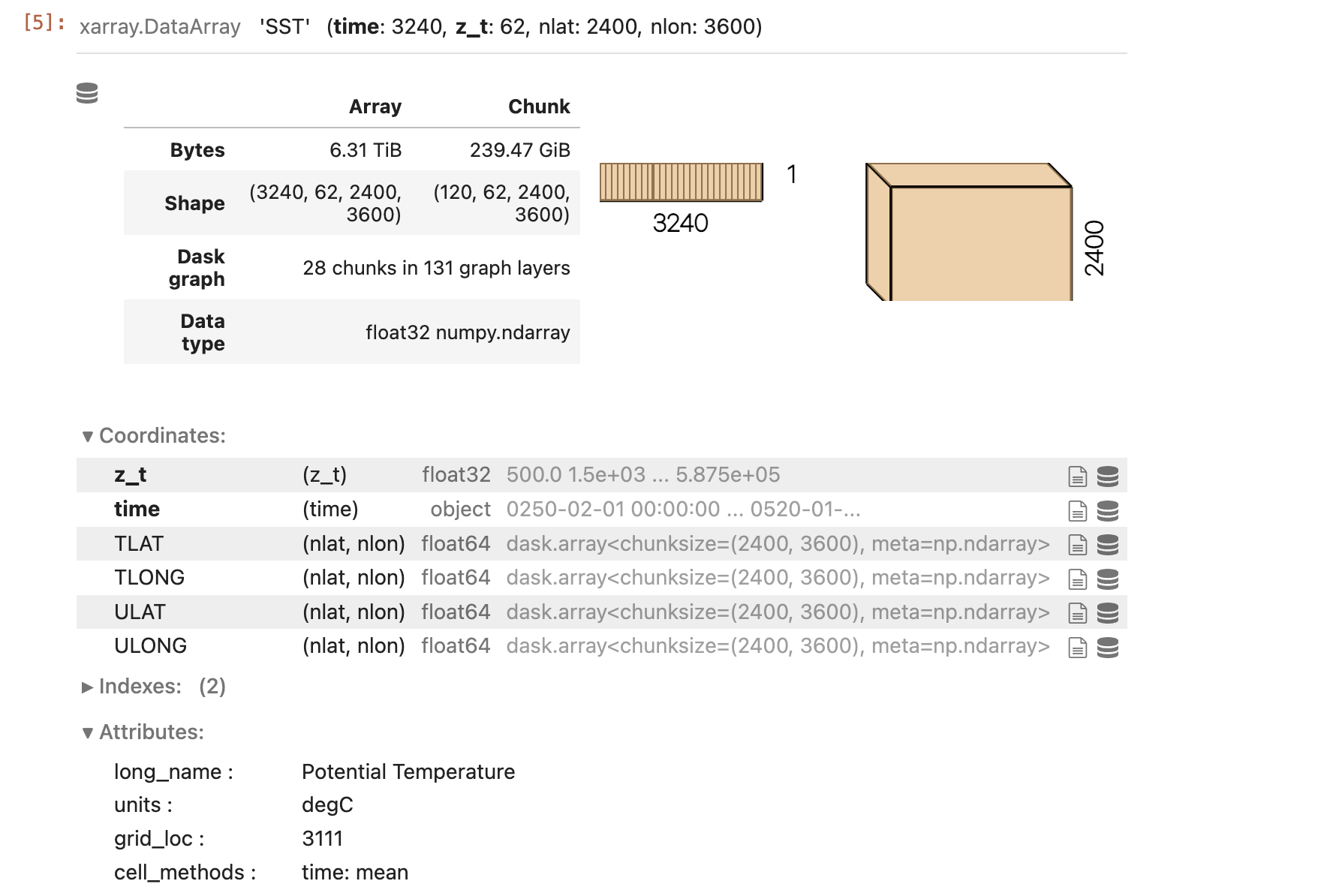
Nish Etige (Jun 16 2023 at 20:52):I am having trouble plotting a map using data in a dask array.
plot_data = dataset.SST.isel(time = 200, z_t = 0)
plot_data.plot()
here's the error.
2023-06-16 12:44:38,736 - distributed.protocol.core - CRITICAL - Failed to deserialize
Traceback (most recent call last):
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/protocol/core.py", line 158, in loads
return msgpack.loads(
^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 128, in unpackb
ret = unpacker._unpack()
^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 592, in _unpack
ret[key] = self._unpack(EX_CONSTRUCT)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 602, in _unpack
obj = obj.decode("utf_8", self._unicode_errors)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 6-7: invalid continuation byte
2023-06-16 12:44:38,741 - distributed.core - ERROR - Exception while handling op register-client
Traceback (most recent call last):
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/core.py", line 832, in _handle_comm
result = await result
^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/scheduler.py", line 5386, in add_client
await self.handle_stream(comm=comm, extra={"client": client})
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/core.py", line 885, in handle_stream
msgs = await comm.read()
^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/tcp.py", line 254, in read
msg = await from_frames(
^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/utils.py", line 100, in from_frames
res = _from_frames()
^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/utils.py", line 83, in _from_frames
return protocol.loads(
^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/protocol/core.py", line 158, in loads
return msgpack.loads(
^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 128, in unpackb
ret = unpacker._unpack()
^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 592, in _unpack
ret[key] = self._unpack(EX_CONSTRUCT)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 602, in _unpack
obj = obj.decode("utf_8", self._unicode_errors)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 6-7: invalid continuation byte
Task exception was never retrieved
future: <Task finished name='Task-24116' coro=<Server._handle_comm() done, defined at /glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/core.py:738> exception=UnicodeDecodeError('utf-8', b'\x00\x00\x00\x00\x00\x00\xf0\xbf\x00\x00\x00\x00\x00\x00\xf0\xbf\x00\x00\x00\x00\x00\x00\xf0\xbf\x00\x00\x00\x00\x00\x00\xf0', 6, 8, 'invalid continuation byte')>
Traceback (most recent call last):
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/core.py", line 832, in _handle_comm
result = await result
^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/scheduler.py", line 5386, in add_client
await self.handle_stream(comm=comm, extra={"client": client})
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/core.py", line 885, in handle_stream
msgs = await comm.read()
^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/tcp.py", line 254, in read
msg = await from_frames(
^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/utils.py", line 100, in from_frames
res = _from_frames()
^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/comm/utils.py", line 83, in _from_frames
return protocol.loads(
^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/distributed/protocol/core.py", line 158, in loads
return msgpack.loads(
^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 128, in unpackb
ret = unpacker._unpack()
^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 592, in _unpack
ret[key] = self._unpack(EX_CONSTRUCT)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 565, in _unpack
ret.append(self._unpack(EX_CONSTRUCT))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/netige/.conda/envs/nishenv/lib/python3.11/site-packages/msgpack/fallback.py", line 602, in _unpack
obj = obj.decode("utf_8", self._unicode_errors)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 6-7: invalid continuation byte
Anna-Lena Deppenmeier said:
it's still exactly the same as I left it before lunch. any advice on what to do?
I usually shut it all down and try try again but I am on day 5 of having issues so am going to give up for the weekend :shrug:
Daniel Kennedy (Jun 20 2023 at 22:14):Chiming in to say that I have also been experiencing this issue.
My typical ask is:
m='10GB'
cluster = PBSCluster(
cores=1, # The number of cores you want
memory=m, # Amount of memory
processes=1, # How many processes
queue='casper', # The type of queue to utilize (/glade/u/apps/dav/opt/usr/bin/execcasper)
local_directory='$TMPDIR', # Use your local directory
resource_spec='select=1:ncpus=1:mem='+m, # Specify resources
project=project, # Input your project ID here
walltime='03:00:00', # Amount of wall time
interface='ib0', # Interface to use
)
cluster.scale(30)
Thanks all. I've been discussing these issues with the system engineers over the past week and their initial suspicion is that slowness in the PBS server is affecting workflows that are sensitive to PBS, which could certainly impact PBSClusters. I'm not fully convinced that the OSError messages are a side-effect of this, since in some cases it seems to be happening after workers initialize but then they have trouble communicating, but since better PBS performance is a win all-around it does seem like a good starting point.
To that end - a change was made in Casper's PBS server today that should improve performance of certain operations dramatically. While these operations aren't ones typically done by Dask workflows (except perhaps the very largest clusters), it should improve performance of the scheduler all around, and this should help both Dask and JupyterHub. Our synthetic tests have shown up to 100x speedup for certain qsub patterns.
But we'd like some real-world data points. This change was made in the past 30 minutes. As you use Dask and JuptyerHub over the coming days, please note performance and reliability. If you see any improvements, we'd love to hear it, but if you keep seeing the same issues that's very useful to know too.
Thanks for your patience as we dig into these problems.
Kristen Krumhardt (Jun 27 2023 at 20:03):I was just finally able to run the fish model FEISTY on the high resolution CESM ocean model output, which we haven't been able to do for the past ~month (I was finally able to grab all 72 requested dask workers at the same time), so I think this new change is working great!
Lev Romashkov (Jun 27 2023 at 20:18):Kristen Krumhardt said:
I was just finally able to run the fish model FEISTY on the high resolution CESM ocean model output, which we haven't been able to do for the past ~month (I was finally able to grab all 72 requested dask workers at the same time), so I think this new change is working great!
Adding to this - this was a big roadblock for us working on this project, huge thanks to @Brian Vanderwende and others working on this!
Anna-Lena Deppenmeier (Jun 27 2023 at 22:17):Hi all, @Brian Vanderwende thanks for this, I have noticed some improvements too! I still have an issue which I think is related to what @Negin Sobhani and I have been discussing, sometimes I try to calculate something, I can see the processes appear and be processed in the dashboard, but then in the end the cell hangs and the notebook gets stuck in this stage =/ I tried seeing if I can execute any other cell but it really is stuck.
Anna-Lena Deppenmeier (Jun 27 2023 at 22:17):Can provide an example if that is helpful.
Holly Olivarez (Jun 28 2023 at 17:54):Anna-Lena Deppenmeier said:
Hi all, Brian Vanderwende thanks for this, I have noticed some improvements too! I still have an issue which I think is related to what Negin Sobhani and I have been discussing, sometimes I try to calculate something, I can see the processes appear and be processed in the dashboard, but then in the end the cell hangs and the notebook gets stuck in this stage =/ I tried seeing if I can execute any other cell but it really is stuck.
I have the same issue. I watch the dashboard complete the processing but then the cell stays "thinking" for hours until I interrupt the kernel and start over to try again.
Deepak Cherian (Jun 28 2023 at 18:09):hen the cell stays "thinking" for hours until I interrupt the kernel
Is this always the data reading step with or without intake?
Holly Olivarez (Jun 28 2023 at 18:16):I am not sure about your question but it is the ds.load() cell that initiates the processing but even when the dashboard shows processing is complete, the cell never stops 'thinking.' Thank you for trying to assist, Deepak!
Brian Vanderwende (Jun 28 2023 at 19:49):@Holly Olivarez - thanks for the report. Would you be willing to provide a sample notebook and execution instructions (mainly the characteristics of the server running the notebook along with the kernel used) that demonstrate your cell stalls? I'd like to investigate whether it shares any commonalities with the issue that Anna-Lena and Negin are troubleshooting.
Holly Olivarez (Jun 28 2023 at 20:14):@Brian Vanderwende Yes, absolutely! Thank you for the offer. I'll get working on a sample notebook asap and send you the path once it's finished.
Holly Olivarez (Jun 28 2023 at 20:37):Holly Olivarez said:
Brian Vanderwende Yes, absolutely! Thank you for the offer. I'll get working on a sample notebook asap and send you the path once it's finished.
The path for a sample notebook is /glade/work/olivarez/cant/olivarez_sample_nb_cmip6.nc
Thank you so much @Brian Vanderwende! :grinning_face_with_smiling_eyes:
Brian Vanderwende (Jun 28 2023 at 20:38):Perfect - thanks. I'll let you know what we find.
Brian Vanderwende (Jun 28 2023 at 20:40):One other thing - what Python language kernel/environment should I use to run it? Do you have a custom environment or do you use our NPL (or something else?). And how much memory do you typically request for the main server you start up (if it's a login server, you'd get 4 GB)?
Holly Olivarez (Jun 28 2023 at 20:43):I use a custom environment and I typically get 4 GB of memory. How can I share the custom environment with you?
Brian Vanderwende (Jun 28 2023 at 20:44):If you point me to the path of the environment, I can make a kernel to use it in the Hub. Thanks!
Holly Olivarez (Jun 28 2023 at 20:46):Great! Here is the path of the environment: /glade/u/home/olivarez/.conda/envs/pinatubo-LENS
Anna-Lena Deppenmeier (Jun 28 2023 at 23:45):Hi, just to also chime in that I am having this problem once again. I created a short notebook here /glade/u/home/deppenme/NOTEBOOKS/RossSea/HeatFluxThroughMixedLayer.ipynb i am using environment /glade/u/home/deppenme/analysis6_versions.yml any help would be appreciated!
Brian Vanderwende (Jun 29 2023 at 16:26):@Anna-Lena Deppenmeier - thanks for the heads up. Is this the problem you are working on with Negin or a separate issue?
Brian Vanderwende (Jun 29 2023 at 16:27):@Holly Olivarez - I do believe I see the issue with your notebook, but I'm doing just a bit of testing so that I can give you a good recommendation for how to configure your cluster and make any necessary changes to the notebook.
Brian Vanderwende (Jun 29 2023 at 19:46):@Holly Olivarez ... so from my testing, I believe the reason you are seeing workers complete but the cell stall during this load operation is indeed because the load is trying to bring all of these data into the memory of notebook server. For a login server, you only get 4 GB, but even if I requested a 200 GB batch server, it was not enough to fit even the first dataset. However, if you are simply trying to do this concatenate the datasets and save to a monolithic netcdf file, you shouldn't need to load the data into the notebook environment. If I comment those load lines out, the workers will directly read in and write data and your memory footprint exists entirely with the workers.
Now, it's still a very large dataset and the load - concatenate - save step when you run to_netcdf will take a very long time. I think there may be some chunking changes that could help there, but I haven't drilled down that far yet. On the cluster config side of things, I'd suggest using 1 worker per job and asking for 4 GB of memory per worker, rather than packing the workers 9-per-node as you are currently doing. Having workers spread across more nodes could help with I/O operations, and in general you'll see better job queue times with more, smaller, jobs.
If you want to see the changes I've made, my copy is at /glade/scratch/vanderwb/tickets/holly-dask/olivarez_sample_nb_cmip6.ipynb. I shrunk things down to 40 workers as I don't think this operation will scale super well, but you could scale that back up to 90 if you like.
Holly Olivarez (Jun 29 2023 at 21:59):Brian Vanderwende said:
Holly Olivarez ... so from my testing, I believe the reason you are seeing workers complete but the cell stall during this load operation is indeed because the load is trying to bring all of these data into the memory of notebook server. For a login server, you only get 4 GB, but even if I requested a 200 GB batch server, it was not enough to fit even the first dataset. However, if you are simply trying to do this concatenate the datasets and save to a monolithic netcdf file, you shouldn't need to load the data into the notebook environment. If I comment those load lines out, the workers will directly read in and write data and your memory footprint exists entirely with the workers.
Now, it's still a very large dataset and the load - concatenate - save step when you run
to_netcdfwill take a very long time. I think there may be some chunking changes that could help there, but I haven't drilled down that far yet. On the cluster config side of things, I'd suggest using 1 worker per job and asking for 4 GB of memory per worker, rather than packing the workers 9-per-node as you are currently doing. Having workers spread across more nodes could help with I/O operations, and in general you'll see better job queue times with more, smaller, jobs.If you want to see the changes I've made, my copy is at
/glade/scratch/vanderwb/tickets/holly-dask/olivarez_sample_nb_cmip6.ipynb. I shrunk things down to 40 workers as I don't think this operation will scale super well, but you could scale that back up to 90 if you like.
This is very helpful, @Brian Vanderwende! You are teaching me so much here. I will look at the sample notebook and adjust my dask cluster setup settings and follow up to let you know of my progress/success. Thank you so very much!
Last updated: May 16 2025 at 17:14 UTC