Daniel Kennedy (Jan 17 2021 at 20:31): Daniel Kennedy (Jan 17 2021 at 20:31):
Daniel Kennedy (Jan 17 2021 at 20:31): Daniel Kennedy (Jan 17 2021 at 20:31):A few of us in the land section have been working on some analysis of the CESM large ensembles. We are using this as a chance to get up to speed with xarray. We've been having issues with xarray/dask, where some calculations seem to be spilling onto disk, creating a bunch of large files a la core-casper30-24189-153776-11, sometimes killing the calculations.
A given data array is 42 ensemble members * 1032 months * 192 lat * 288 lon, which xarray quotes as 9.6 GB. Per xarray documentation I've been chunking the data by ensemble member and every 2 years in order to achieve chunks of ~1.3e6 elements.
Yet even with 36 workers from casper (375GB memory), something like calculating annual means seems to 'spill' to disk. It seems like that should be plenty of memory?
The notebook is online here: https://nbviewer.jupyter.org/github/djk2120/cesm-lens/blob/main/src/memory_issue_casper.ipynb
It seems like there are lots of tricks for optimizing dask, and I was hoping for suggestions. Should I be using larger chunks? smaller? Do I just need more workers?
Likewise, is this a common issue that people are running into on Casper or is this unique to our group?
thanks for any suggestions!
-Daniel
further documentation:
xarray version: 16.2
dask version: 2020.12.0
notebook on github: https://github.com/djk2120/cesm-lens/blob/main/src/memory_issue_casper.ipynb
red herring?: when I try similar calculations on cheyenne I am less likely to trigger this type of problem
Deepak Cherian (Jan 18 2021 at 17:08):Hi Daniel, I checked and it completes with dask==2.30.0 with bigger chunks/ I used
ds = xr.open_mfdataset(
files, combine="nested", parallel=True, concat_dim=ensdim, chunks={"time": -1}
)
Max memory usage ≈ 100GB. So this may be a regression.
Another trick is to use .mean(skipna=True) then max memory usage ≈ 30GB. This will propagate NaNs (but it doesn't matter since you're using model output which shouldn't have NaNs).
Daniel Kennedy (Jan 19 2021 at 15:06):Great- thanks Deepak. This worked for me
Daniel Kennedy (Jan 21 2021 at 16:20):Oops, actually this is not totally working for me. It worked for CESM1, but not for CESM2. The main difference between them is that CESM2 splits the output across ensemble members, but also into 10-year chunks. I.e. CESM1 is split across 42 files for 42 ensemble members. CESM2 is split across 200 files for 50 ensemble members.
Similar to before I have a DataArray that is:
50 ensemble members x 420 months x 192 lat x 288 lon, quoted by xarray as 4.64GB
(Because this is land-focused, many elements are NaN. On disk, the files sum to 2.1GB.)
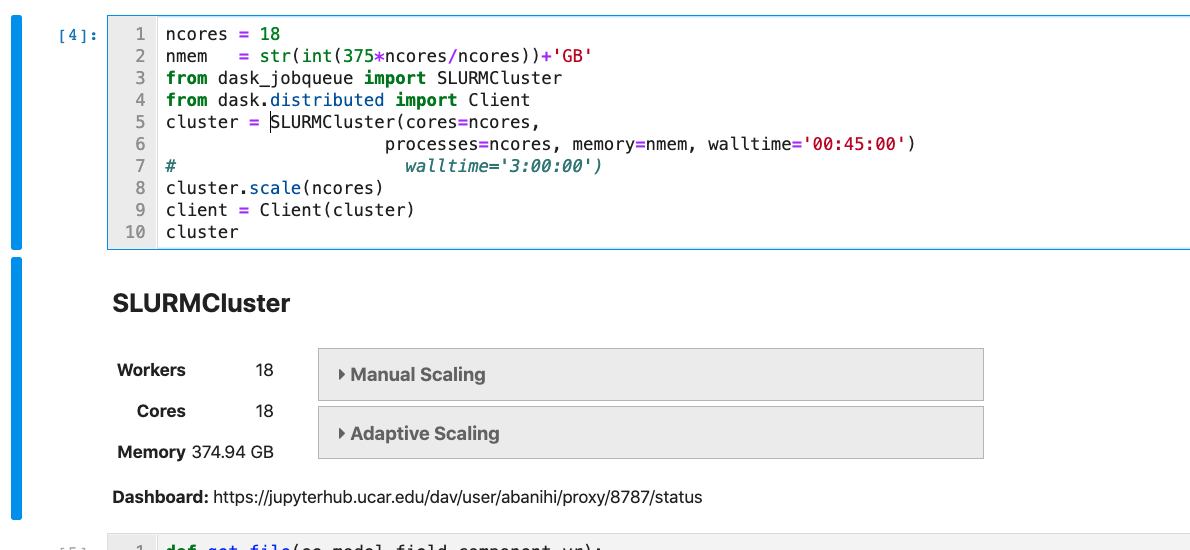
Using 36 dask workers (375GB memory), I am unable to perform calculations on the full DataArray without spilling to disk (e.g. da.mean(skipna=True). I tried a few different chunk layouts (200,50, and 350 chunks) and all created core-casper-xx files. It looked like I could work on about one tenth of the dataset at a time without spilling to disk.
Is this a common problem? In my mind it seems like that ratio of 375GB memory to 4.64GB of data should be very reasonable.
Any suggestions?
You can see my notebook here: https://nbviewer.jupyter.org/github/djk2120/cesm-lens/blob/main/src/memory_issue.ipynb
Or find it on github: https://github.com/djk2120/cesm-lens/blob/main/src/memory_issue.ipynb
thanks!
Anderson Banihirwe (Jan 21 2021 at 21:12):@Daniel Kennedy , can you post here the contents of ~/.config/dask/distributed.yaml when you get a moment? There's a chance that adjusting the worker configurations may help.
Daniel Kennedy (Jan 21 2021 at 21:16):This looks like a pertinent bit:
# Fractions of worker memory at which we take action to avoid memory blowup
# Set any of the lower three values to False to turn off the behavior entirely
memory:
target: 0.60 # target fraction to stay below
spill: 0.70 # fraction at which we spill to disk
pause: 0.80 # fraction at which we pause worker threads
terminate: 0.95 # fraction at which we terminate the worker
Daniel Kennedy (Jan 21 2021 at 21:19):Also:
scheduler:
allowed-failures: 3 # number of retries before a task is considered bad
bandwidth: 100000000 # 100 MB/s estimated worker-worker bandwidth
blocked-handlers: []
default-data-size: 1000
# Number of seconds to wait until workers or clients are removed from the events log
# after they have been removed from the scheduler
events-cleanup-delay: 1h
idle-timeout: null # Shut down after this duration, like "1h" or "30 minutes"
transition-log-length: 100000
work-stealing: True # workers should steal tasks from each other
worker-ttl: null # like '60s'. Time to live for workers. They must heartbeat faster th
Anderson Banihirwe (Jan 21 2021 at 21:20):Great! Try these settings
memory: target: false # don't spill to disk spill: false # don't spill to disk pause: 0.80 # fraction at which we pause worker threads terminate: 0.95 # fraction at which we terminate the worker
Anderson Banihirwe (Jan 21 2021 at 21:22):The scheduler settings look okay
Daniel Kennedy (Jan 21 2021 at 21:43):Hi Anderson,
That didn't actually work for me- I was still spilling to disk. I thought maybe my kernel wasn't ingesting that information correctly, so I switched how I access my notebook. I was using the 'start-jupyter' approach, and switched to jupyterhub, and that fixed it. Then I changed the spill settings back and it looks like it is still fixed. Not sure what was at fault in my other environment, but switching to jupyterhub seems to have fixed it for me.
Thanks. And thanks also, Deepak.
Anderson Banihirwe (Jan 21 2021 at 22:02):Glad to hear that adjusting the configurations works
I was using the 'start-jupyter' approach, and switched to jupyterhub, and that fixed it.
Interesting.... I don't know where the discrepancy between the two approaches is coming from ;). Can you confirm that dask is loading configurations from the same location in both approaches?
Here's some code snippet for inspecting where the configurations are coming from:
In [1]: import dask In [2]: dask.__version__ Out[2]: '2021.01.0' In [7]: dask.config.get('distributed.worker') Out[7]: {'memory': {'target': 0.9, 'spill': False, 'pause': 0.8, 'terminate': 0.95}} In [8]: dask.config.PATH Out[8]: '/glade/u/home/abanihi/.config/dask'
Daniel Kennedy (Jan 21 2021 at 22:41):For both:
dask.config.PATH is /glade/u/home/djk2120/.config/dask
And the dask version and all the 'distributed.worker' information is the same. (My settings match what you have printed above)
Daniel Kennedy (Jan 21 2021 at 22:57):I will note I am using different environments. E.g. h5py for my environment on jupyterhub is 3.1.0 and for ncar_pylib is 2.10.0
I've attached the rest of the version info, if you're interested to peruse...
npl_versions.txt myenv_versions.txt
Will Wieder (Feb 03 2021 at 23:48):new question on this thread you can maybe help with?
I'm trying to read in daily data, do some calculations, and then calculate a cumulative sum for each grid cell...
The code here was working with 2 ensemble members and ~10 years of data (albeit) slowly
https://github.com/wwieder/cesm-lens/blob/main/notebooks/lens2_FireRisk.ipynb
adding more years and ensemble members, however, quickly becomes prohibitively time consuming and eventually kills a worker (very sad). Suggestions for making this code more efficient would be very helpful.
Haiying Xu (Feb 04 2021 at 19:11):@Will Wieder , did you ever use yipsolon.visualize() to check if yipsolon parallel correctly?
Anderson Banihirwe (Feb 05 2021 at 17:44):@Will Wieder, I took a look at your notebook, and with a few adjustments I was able to get the entire notebook to run without a problem. Here's the output of the cell that was failing in your latest run: Screen-Shot-2021-02-04-at-9.59.24-PM.png
Here's a list the adjustments I made:
Screen-Shot-2021-02-04-at-10.00.19-PM.png
Screen-Shot-2021-02-05-at-10.35.43-AM.png
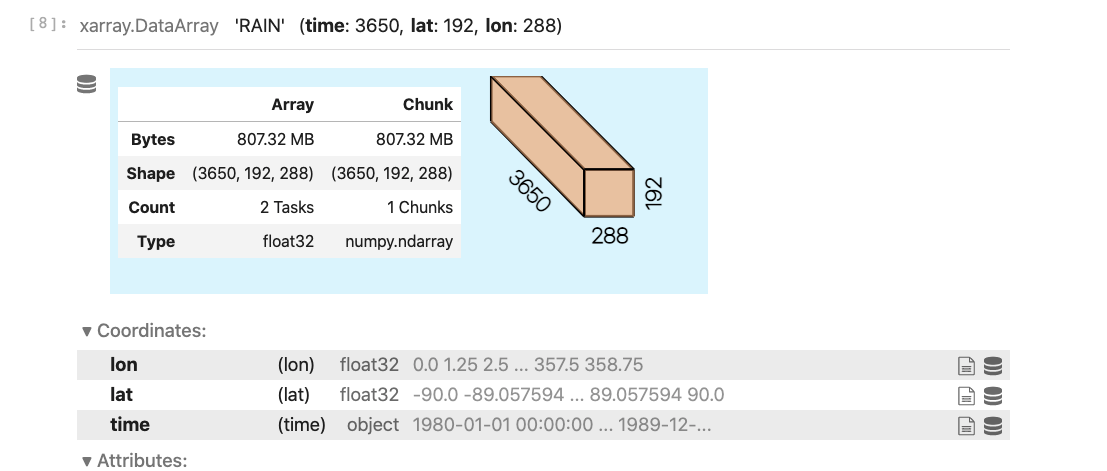
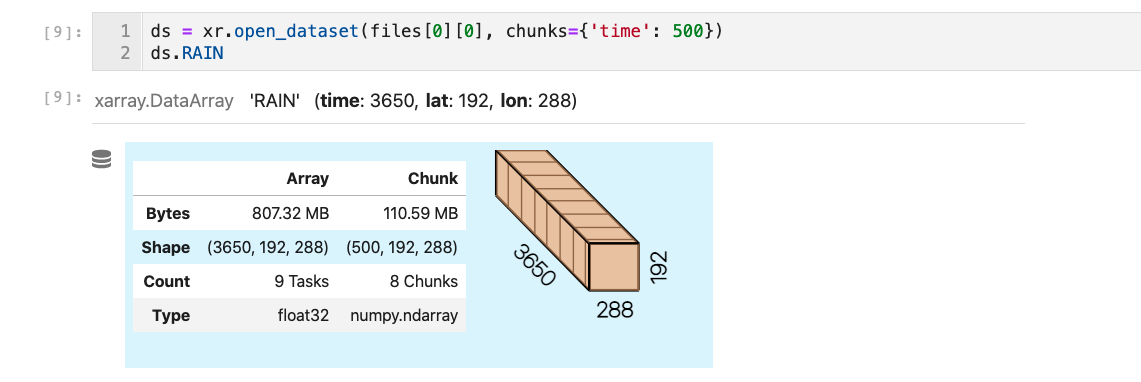
Reducing the chunksize to ~ 110MB helped
Screen-Shot-2021-02-05-at-10.35.52-AM.png
Anderson Banihirwe (Feb 05 2021 at 17:45):To address the chunking issue, here's the modified version of get_daily() function:
def get_daily(model,fields,firstyear, component,nens, chunks={'time': 500}): first = True for field in fields: #find the appropriate files files = all_files(model,field,firstyear, component,nens) #instantiation steps only required once if first: first = False # set up ensemble dimensions ensdim = xr.DataArray(np.arange(len(files)), dims='ens', name='ens') ensdim.attrs['long_name']='ensemble number' concat_dim = {'CESM1':ensdim,'CESM2':[ensdim,'time']} # instantiate ds if model=='CESM2': # LENS2 is split by decade, take only 1 copy of landfrac,area, etc. ds = xr.open_mfdataset(files[0],combine='by_coords',parallel=True, chunks=chunks) tmp = xr.open_dataset(files[0][0], chunks=chunks) for thisvar in tmp.data_vars: if 'time' not in tmp[thisvar].coords: ds[thisvar]=tmp[thisvar] else: ds = xr.open_dataset(files[0], chunks=chunks) tmp = xr.open_mfdataset(files,combine='nested',parallel=True, concat_dim=concat_dim[model], chunks=chunks) ds[field] = tmp[field] if component == 'lnd': ds['landarea'] = ds['area']*ds['landfrac'] ds['landarea'].name = 'landarea' ds['landarea'].attrs['units'] = 'km2' nmonths = len(ds.time) yr0 = ds['time.year'][0].values ds['time'] =xr.cftime_range(str(yr0),periods=nmonths,freq='MS') ix = ds['time.year']>=firstyear with dask.config.set(**{'array.slicing.split_large_chunks': False}): return ds.isel(time=ix)
Anderson Banihirwe (Feb 05 2021 at 17:47):Notice the chunks={'time': 500} in the function signature. I propagate this chunking scheme to all existing xr.open_mfdataset() invocations by passing chunks=chunks...
Anderson Banihirwe (Feb 05 2021 at 17:49):I hope this helps. When you get a moment, please give it a try and let me know how it goes
Deepak Cherian (Feb 05 2021 at 23:40):ix = ds['time.year']>=firstyear with dask.config.set(**{'array.slicing.split_large_chunks': False}): return ds.isel(time=ix)
Can this be replaced by ds.sel(time=slice(str(firstyear), None))
Will Wieder (Feb 08 2021 at 16:20):This is working great!
I have one additional question. Currently I'm just doing the calculations on a single grid cell to accelerate development of this code, (see cells 34-35)
https://github.com/wwieder/cesm-lens/blob/main/notebooks/lens2_FireRisk.ipynb
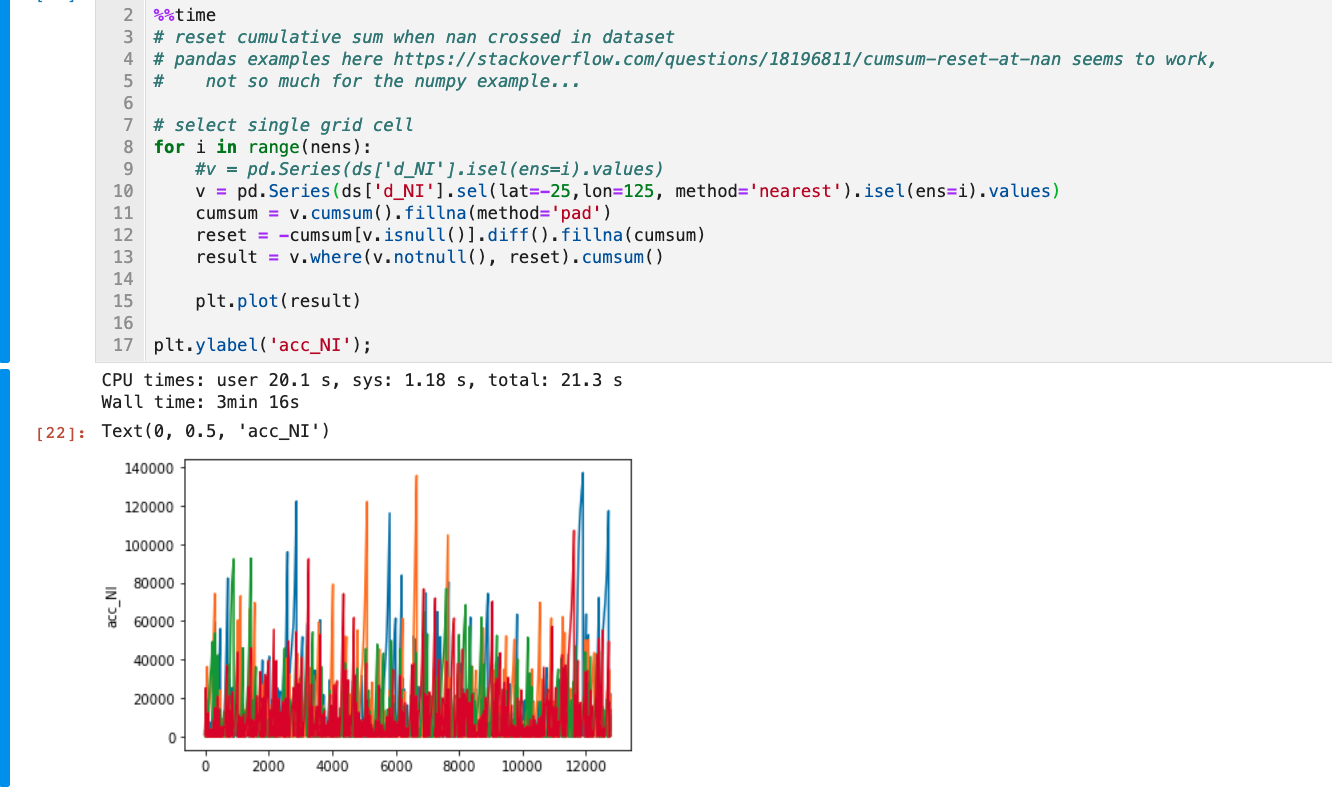
I know there should be a better way to use the pandas functions in cell 35 to calculate a running accumulator (that resets when precipitation > 3 mm).
Can you suggest an efficient way to do this (using apply_ufunc)?
Anderson Banihirwe (Feb 08 2021 at 21:55):Since the data are chunked across the ens dimension, I think xr.map_blocks() is a good candidate (in my opinion, it's clearer than xr.apply_ufunc) for what you are trying to achieve.
I'm curious... what was the motivation for using pandas in
v = pd.Series(ds['d_NI'].sel(lat=-25,lon=125, method='nearest').isel(ens=i).values) cumsum = v.cumsum().fillna(method='pad') reset = -cumsum[v.isnull()].diff().fillna(cumsum) result = v.where(v.notnull(), reset).cumsum()
I'm asking because if you choose to go with xr.map_blocks(), you may have to re-write this so as to consume xarray objects.
@Deepak Cherian , what's the equivalent of .fillna(method='pad') in xarray? From the documentation, xarray's .fillna() doesn't have the method argument and accepts a value only.
Deepak Cherian (Feb 08 2021 at 21:56):.interpolate_na(method="nearest")?
Deepak Cherian (Feb 08 2021 at 21:58):running accumulator (that resets when precipitation > 3 mm)
I would use numba + apply_ufunc for something like this.
Last updated: May 16 2025 at 17:14 UTC