Mira Berdahl (Mar 29 2022 at 22:56): Mira Berdahl (Mar 29 2022 at 22:56):
Mira Berdahl (Mar 29 2022 at 22:56): Mira Berdahl (Mar 29 2022 at 22:56):Hi,
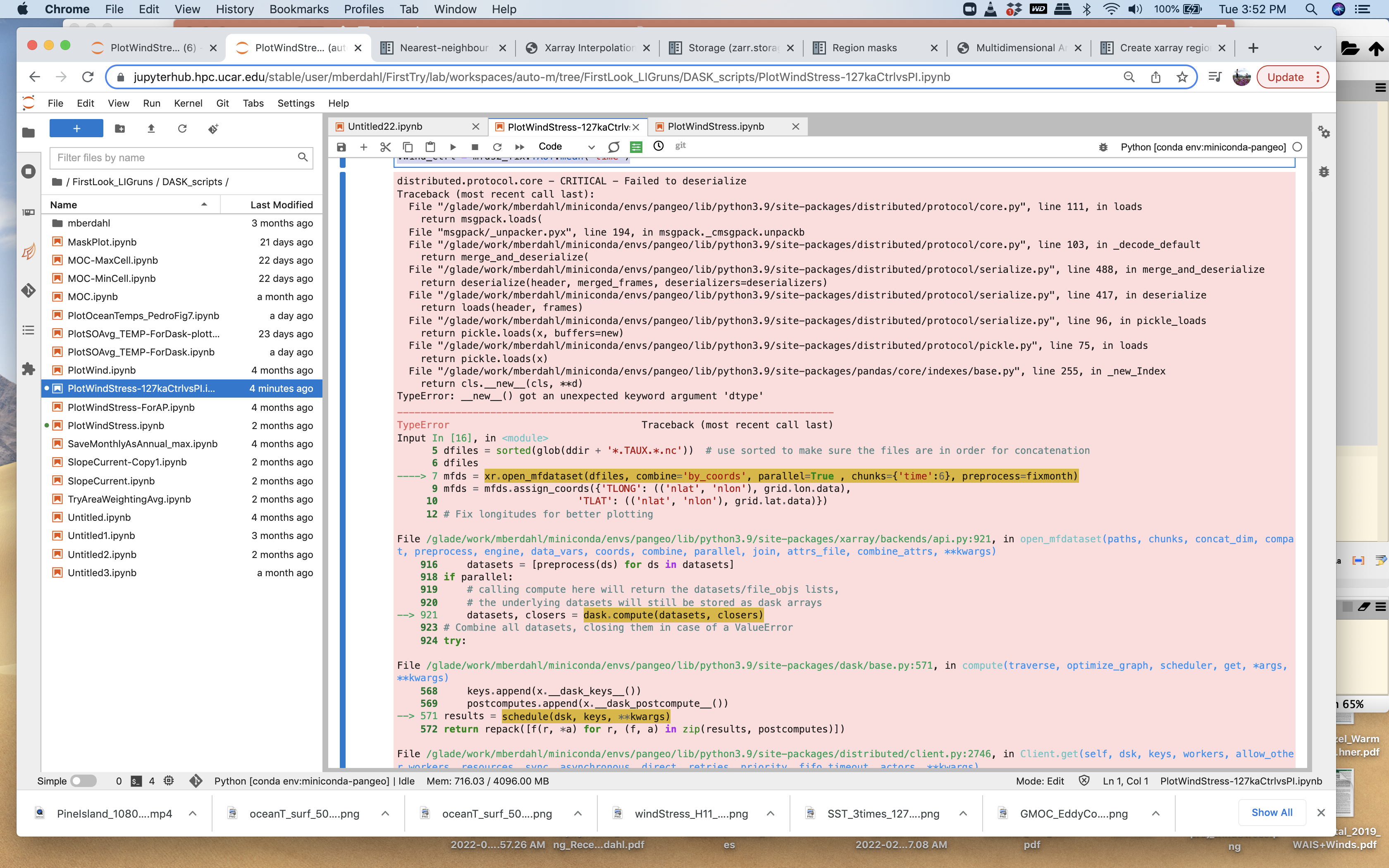
I'm loading in data with a script that previously worked (maybe a month or two ago). However, now I am getting an error that says Failed to deserialize, screenshot attached of the error.
Screen-Shot-2022-03-29-at-3.52.45-PM.png
The line of code that it does not seem to like is the first time I call:
mfds = xr.open_mfdataset(dfiles, combine='by_coords', parallel=True , chunks={'time':6}, preprocess=fixmonth)
The cell is copied below in full:
from glob import glob
##### READ U Control ####
ddir = '/glade/scratch/mberdahl/127kaControl/WIND/STRESS/'
dfiles = sorted(glob(ddir + '*.TAUX.*.nc')) # use sorted to make sure the files are in order for concatenation
dfiles
mfds = xr.open_mfdataset(dfiles, combine='by_coords', parallel=True , chunks={'time':6}, preprocess=fixmonth)
mfds = mfds.assign_coords({'TLONG': (('nlat', 'nlon'), grid.lon.data),
'TLAT': (('nlat', 'nlon'), grid.lat.data)})
# Fix longitudes for better plotting
mfds_fix = pop_add_cyclic(mfds)
#ds127kactrl_fix = pop_add_cyclic(ds_127kactrl)
#ds_127kactrl_CLIM = pop_add_cyclic(ds_127kactrl_CLIM)
uwnd_ctrl = mfds_fix.TAUX
uwind_ctrl = mfds_fix.TAUX.mean('time')
#### READ V Control ####
ddir = '/glade/scratch/mberdahl/127kaControl/WIND/STRESS/'
dfiles = sorted(glob(ddir + '*.TAUY.*.nc')) # use sorted to make sure the files are in order for concatenation
dfiles
mfds2 = xr.open_mfdataset(dfiles, combine='by_coords', parallel=True , chunks={'time':6}, preprocess=fixmonth)
mfds2
mfds2 = mfds2.assign_coords({'TLONG': (('nlat', 'nlon'), grid.lon.data),
'TLAT': (('nlat', 'nlon'), grid.lat.data)})
mfds2_fix = pop_add_cyclic(mfds2)
vwnd_ctrl = mfds2_fix.TAUY
vwind_ctrl = mfds2_fix.TAUY.mean('time')
Any thoughts on how to proceed are appreciated!
Deepak Cherian (Mar 31 2022 at 16:10):This looks like a dask issue. Can you print out dask.__version__ The latest one is 2022.3.0 I think
Mira Berdahl (Mar 31 2022 at 16:18):It doesn't seem to even recognize dask, I get:
NameError Traceback (most recent call last)
Input In [25], in <module>
----> 1 dask.__version__
NameError: name 'dask' is not defined
Deepak Cherian (Mar 31 2022 at 16:23):That means you haven't explicitly imported dask in your notebook. Use import dask first
Mira Berdahl (Mar 31 2022 at 16:32):Ok, thanks. It looks like my version is
'2022.01.0'
Do I need to update this?
In general, do I always have to explicitly import dask into my notebook? It seems I am using dask arrays im some of my other scripts, even without importing dask.
Deepak Cherian (Mar 31 2022 at 16:36):I think it would be good to update.
do I always have to explicitly import dask into my notebook?
Only if you want to do explicitly something with it, like checking the version. Xarray will import and use as necessary for example.
Mira Berdahl (Mar 31 2022 at 16:50):OK, that makes sense, thanks.
Do you recommend I use mamba for the update?
Deepak Cherian (Mar 31 2022 at 16:54):yes!
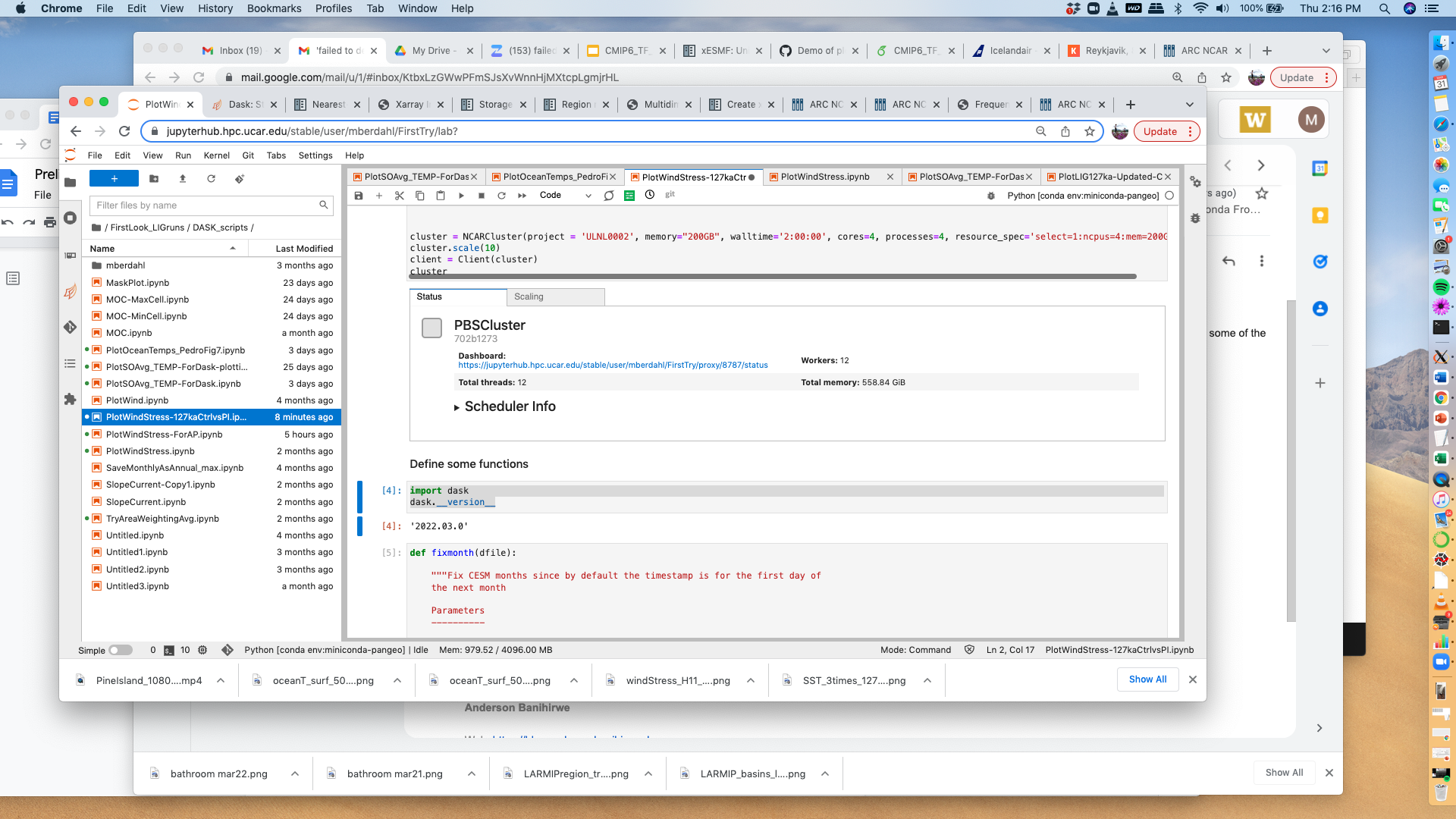
Mira Berdahl (Mar 31 2022 at 21:18):Hi Deepak,
Looks like the same problem persists despite the updated dask package...
Screenshot shows the updated version is being used:
Screen-Shot-2022-03-31-at-2.16.33-PM-2.png
Any other thoughts?
Thanks.
Deepak Cherian (Mar 31 2022 at 21:34):Oops sorry. I have seen this before (https://github.com/pydata/xarray/issues/6226). The issue was with cftime and/or pandas. Can you upgrade those two and try again.
Mira Berdahl (Mar 31 2022 at 22:35):Unfortunately the issue persists despite updating pandas and cftime...
Anderson Banihirwe (Mar 31 2022 at 23:01):@Mira Berdahl, which version of pandas are you running?
Mira Berdahl (Mar 31 2022 at 23:06):@Anderson Banihirwe Looks like it is '1.4.1'
Anderson Banihirwe (Mar 31 2022 at 23:07):try downgrading to version earlier than v1.4.0 to see if your issue goes away
mamba install 'pandas<1.4.0'
edit: i meant to write version earlier than v1.4.0
Mira Berdahl (Mar 31 2022 at 23:22):That did the trick! Thanks @Anderson Banihirwe
Anderson Banihirwe (Mar 31 2022 at 23:23):glad to hear it and thank you for your patience!
Last updated: May 16 2025 at 17:14 UTC