Isla Simpson (Feb 19 2021 at 21:48): Isla Simpson (Feb 19 2021 at 21:48):
Isla Simpson (Feb 19 2021 at 21:48): Isla Simpson (Feb 19 2021 at 21:48):Hello, I'm not sure if this is a dask question. I'm trying to run a script on ERA5 data from the RDA. Before I ran almost exactly the same script on the 2m Temperature data and it worked fine. Now I'm trying to output the 850hPa level temperature. So, pretty much the only difference from my 2m temperature script is a ".sel(level=850, method="nearest")" appended to my open_mfdataset call. My script is failing on the write out to netcdf of my processed data and there isn't an error that I can comprehend. The bottom line of it is...
KilledWorker: ("('broadcast_to-mean_agg-aggregate-mean_chunk-regrid_array-regrid_array_0-transpose-concatenate-c524a83c21d7433475bf36--384', 320, 0, 0)", <Worker 'tcp://10.12.205.23:36825', name: 0-28, memory: 0, processing: 9>)
The netcdf file actually seems to have all the data in it except for the last day which is all nans. So, it seems to be failing at the end of the write out to netcdf. My script is here... /glade/u/home/islas/python/sortera5/grabera5t850.ipynb. I'd be glad to hear if anyone has any suggestions as to how to diagnose this problem further. Thanks!
Deepak Cherian (Feb 19 2021 at 22:25):Hi Isla.
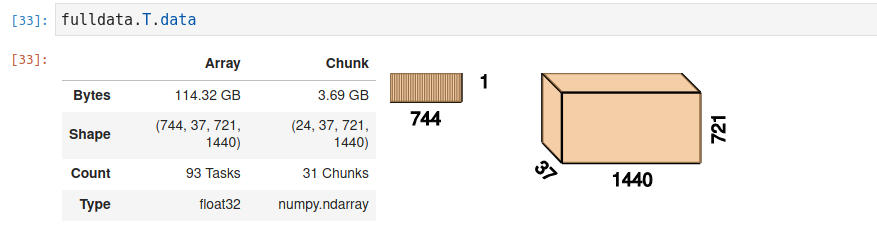
I split your open_mfdataset call in to two steps.
fulldata = xr.open_mfdataset(..., chunks={"time": 24}) data = fulldata.sel(level=850, method="nearest")
Then I looked at fulldata:
pasted image
The chunk size is large (3GB). You want this to usually be ≈100-200 MB range.
I would try with chunks={"time": 48, "level": 1} then the chunk size is 100MB. Your 2m code is reading from a surface file which has one level (i assume) so that's probably why it worked
Deepak Cherian (Feb 19 2021 at 22:27):More generally, I'm curious as to why you're looping over months instead of having open_mfdataset do it for you? Something like xr.open_mfdataset("/gpfs/fs1/collections/rda/data/ds633.0/e5.oper.an.pl//1979*/*_t.*.nc")
Isla Simpson (Feb 19 2021 at 23:33):Hi Deepak,
Thanks a lot. Yeah, I don't really know what I'm doing when it comes to the chunks, so this is good advice for how to debug issues like this. I had no clue. Indeed, that is working now. The reason I had divided it up and looped over months was because I was worried about memory. I was thinking that I can read in per month and interpolate to the coarser grid and then never have the full years worth of 0.25deg data loaded into memory. But maybe this doesn't make sense. I don't have a good handle on when data is being loaded into memory. I assumed it would be done at the regridding stage, but maybe it's all being don at the end? I'll try it out without looping over months.
Thanks for your help!
Deepak Cherian (Feb 20 2021 at 00:13):It's all being done at the end so the loop isn't adding anything.
Isla Simpson (Feb 20 2021 at 00:18):oh ok. good to know! thank you.
Last updated: May 16 2025 at 17:14 UTC