Michael Levy (Dec 08 2020 at 19:47): Michael Levy (Dec 08 2020 at 19:47):
Michael Levy (Dec 08 2020 at 19:47): Michael Levy (Dec 08 2020 at 19:47):I submitted the first run in our ensemble; it is running 1990 - 2005 using the 1990 restart files from 001 (and I switched to the prescribed_volcaero_file that omits the Pinatubo eruption).
Caseroot: /glade/work/mlevy/codes/pinatubo-LE/cases/b.e11.B20TRC5CNBDRD.f09_g16.001
Rundir: /glade/scratch/mlevy/b.e11.B20TRC5CNBDRD.f09_g16.001/run
It's set up to run 1990 - 1997, which should take ~11 hours, and then resubmit the job and 1998-2005 (another ~11 hours). Once the current job finishes, it would be useful to have someone look over the output. I think the two important things to verify are
volcaero file is identical until 1991)Once we can confirm that this run setup is what we want, I'll move on to the following:
Matt Long (Dec 08 2020 at 19:48):cc @Galen McKinley, @Amanda Fay
Michael Levy (Dec 08 2020 at 20:04):And I already misconfigured something... switching to the right compset (B20TRLENS) instead of the one I thought was used based on case name (B20TRC5CNBDRD). It looks like I actually created the latter compset myself, and it might be identical to the other but better safe than sorry
Amanda Fay (Dec 08 2020 at 21:57):I will take a look at it later this week. Thanks for getting this set up @Michael Levy
Michael Levy (Dec 10 2020 at 15:11):@Amanda Fay After talking with Matt, I've updated the name of the case to include the phrase no_pinatubo. The directories I mentioned previously still exist, but I would recommend looking at the following instead:
Caseroot: /glade/work/mlevy/codes/pinatubo-LE/cases/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.00
1
Rundir: /glade/scratch/mlevy/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001/run
Archive dir (netcdf gets copied here when run finishes): /glade/scratch/mlevy/archive/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001
The first 8 years of this run have completed and been archived; the second 8-year portion just started running and should finish in around 8:30pm Eastern (you're in NY, right?). My plan is to remove the b.e11.B20TRC5CNBDRD.f09_g16.001 directories once the b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001 runs finish.
Amanda Fay (Dec 10 2020 at 19:19):@Michael Levy Thanks for the update. Taking a look at the files this afternoon to be sure that the atm co2 signature looks as we would expect without pinatubo (shouldnt need more than the 8yrs completed to confirm this).
I am actually located in MT so Mountain time zone like you. I work in the evening often to make up for missed hours due to child care limitations so I can check on these runs tonight when they finish.
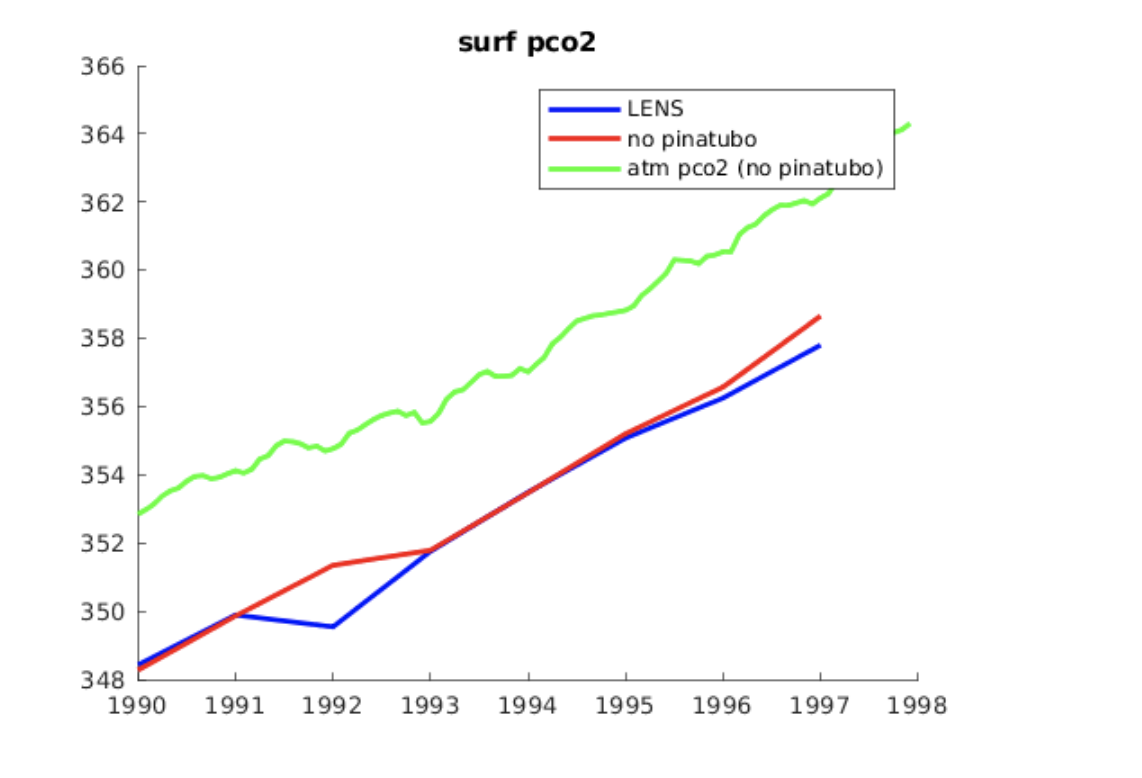
Amanda Fay (Dec 14 2020 at 03:06):Test run looks good! The ocean is responding as we would expect without a big eruption. CESM_nopinatubo_testrun.png
I did want to pick someones brain to understand how dpCO2 is calculated by the model. When I try to do the calculation myself Im getting a different value and wondering if it's the timestep resolution perhaps causing that (Im looking at monthly values). Not time sensitive but just want to understand.
Matt Long (Dec 14 2020 at 15:53):@Amanda Fay, DpCO2 is computed at every ocean timestep and averaged. The ATM_CO2 forcing is annual (I think), and it is interpolated and passed to the ocean for each coupling timestep (daily). I'd have to check the settings to be sure, but I would guess this is done using linear interpolation in time.
Michael Levy (Dec 14 2020 at 23:18):Thanks for looking at 001, @Amanda Fay! I have a script for running the RCP8.5 portion of each run, and should have 2006-2010 from 001 available late tonight. We'll eventually have 2006 - 2025, but I'm only running the first five years to make sure this portion of the run is set up correctly as well. Tomorrow morning I'll verify that the run finished, and then post a link to the location on glade -- if someone could look at that portion as well, I'd appreciate it. I believe there was some subtlety to account for in making sure I started the RCP run at the right time to recreate a bug in the forcing dataset and I just want to make sure I don't inadvertently introduce discrepancies with the yellowstone run at the seam between the two forcing periods.
Amanda Fay (Dec 15 2020 at 02:26):@Michael Levy I'll have time tomorrow to take a look at the rcp 8.5 years. The bug that we want to recreate is that the atm co2 remains constant for jan 2005- dec 2005 and then jumps for jan 2006 as opposed to the linear interpolation that matt referred to. So it's actually in the yr 2005 that we see this issue. I honestly didnt look at post 2000 in the previous files you sent because I was focused on the pinatubo effect but I will take a look at that all tomorrow as well.
Michael Levy (Dec 15 2020 at 15:24):The RCP run died toward the end of Dec 2006 [sometime during Dec 14, 2006, to be precise]. The error I'm seeing is coming from CAM:
ENDRUN: not able to increment file name from filenames_list file: oxid_1.9x2.5_L26_clim_list.c090805.txt
It looks like this is part of &chem_inparm and maybe isn't set quite right by the compset?
$ grep tracer_cnst atm_in tracer_cnst_datapath = '/glade/p/cesmdata/cseg/inputdata/atm/cam/chem/trop_mozart_aero/oxid' tracer_cnst_file = 'oxid_rcp85_v1_1.9x2.5_L26_1995-2105_c100202.nc' tracer_cnst_filelist = 'oxid_1.9x2.5_L26_clim_list.c090805.txt' tracer_cnst_specifier = 'O3','OH','NO3','HO2' tracer_cnst_type = 'INTERP_MISSING_MONTHS'
I'm a little confused because tracer_cnst_file looks like an RCP file but tracer_cnst_filelist doesn't:
$ cat /glade/p/cesmdata/cseg/inputdata/atm/cam/chem/trop_mozart_aero/oxid/oxid_1.9x2.5_L26_clim_list.c090805.txt oxid_1.9x2.5_L26_1850clim.c090805.nc oxid_1.9x2.5_L26_1850-1859clim.c090804.nc oxid_1.9x2.5_L26_1860-1869clim.c090804.nc oxid_1.9x2.5_L26_1870-1879clim.c090804.nc oxid_1.9x2.5_L26_1880-1889clim.c090804.nc oxid_1.9x2.5_L26_1890-1899clim.c090804.nc oxid_1.9x2.5_L26_1900-1909clim.c090804.nc oxid_1.9x2.5_L26_1910-1919clim.c090804.nc oxid_1.9x2.5_L26_1920-1929clim.c090804.nc oxid_1.9x2.5_L26_1930-1939clim.c090804.nc oxid_1.9x2.5_L26_1940-1949clim.c090804.nc oxid_1.9x2.5_L26_1950-1959clim.c090804.nc oxid_1.9x2.5_L26_1960-1969clim.c090804.nc oxid_1.9x2.5_L26_1970-1979clim.c090804.nc oxid_1.9x2.5_L26_1980-1989clim.c090804.nc oxid_1.9x2.5_L26_1990-1999clim.c090804.nc oxid_1.9x2.5_L26_2000-2009clim.c090804.nc
Even still, that last file looks like it should contain data for 2006. Anyone have any ideas? (@Nan Rosenbloom? @Keith Lindsay?)
Michael Levy (Dec 15 2020 at 15:25):CASEROOT: /glade/work/mlevy/codes/pinatubo-LE/cases/b.e11.BRCP85LENS_no_pinatubo.f09_g16.001
RUNDIR: /glade/scratch/mlevy/b.e11.BRCP85LENS_no_pinatubo.f09_g16.001/run
The case was generated via /glade/work/mlevy/codes/pinatubo-LE/case_gen_scripts/RCP_portion
Nan Rosenbloom (Dec 15 2020 at 16:31):Hi Mike - I think the problem is that you are starting your RCP run as a branch. Try starting it as a hybrid, and then I think it should work.
Michael Levy (Dec 15 2020 at 16:34):Thanks Nan! If I start as a hybrid, do I need to do anything special to make sure all the components start up correctly? I had originally set up by 20C run as a hybrid, but even with OCN_TIGHT_COUPLING=TRUE the hybrid wasn't bit-for-bit with the branch / restart options. (One benefit of starting the run in a kludgy way is that I had a baseline for comparison to make sure the improved set-up was bit-for-bit :)
Michael Levy (Dec 15 2020 at 16:38):I guess the important part is that my setup matches how the original LENS runs made the switch from 20thC -> RCP, but I haven't been able to find that sort of documentation anywhere (presumably because I'm not looking in the right place)
Michael Levy (Dec 15 2020 at 16:55):Looking at /glade/campaign/cesm/collections/cesmLE/CESM-CAM5-BGC-LE/ocn/proc/tseries/monthly/TEMP/b.e11.BRCP85C5CNBDRD.f09_g16.001.pop.h.TEMP.200601-208012.nc, the first time stamp is 17-Jan-2006 00:29:60 and the 13th is 16-Jan-2007 12:00:00 so I think we actually want OCN_TIGHT_COUPLING=FALSE and the hybrid start-up. Thanks @Nan Rosenbloom!
Also, I updated the casename I'm creating to b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001 to be consistent with the original files
Nan Rosenbloom (Dec 15 2020 at 18:20):Hi Mike. I don't think the hybrid start will ever be B4B with a branch restart because of the way the atm is initialized. One uses the restart file, the other uses the cam.i file. But I think that's expected behavior.
Michael Levy (Dec 15 2020 at 18:52):Hi Mike. I don't think the hybrid start will ever be B4B with a branch restart because of the way the atm is initialized. One uses the restart file, the other uses the cam.i file. But I think that's expected behavior.
That makes sense -- for this experiment, we wanted to start with something that would be bit-for-bit the same with the 1990-2005 portion of the run but change answers by swapping out the volcanic forcing... so that used a branch run. For the 2006-2025 portion of the run, we just want to mimic what the original LENS did and it sounds like hybrid is the answer. So I think everything is configured correctly now, and hopefully in ~6 hours we'll have five years of output in the short-term archive to look at
Nan Rosenbloom (Dec 15 2020 at 22:08):Sounds like it's configured the way you want! Good luck!
Michael Levy (Dec 16 2020 at 01:13):The first 5 years of the RCP extension (2006 - 2010) are available in /glade/scratch/mlevy/archive/b.e11.BRCP85C5CNBDRD_no_pinatubo.f09_g16.001. @Amanda Fay, is there anything in particular you want to check before I continue the 2011 - 2025 portion of the run, or should I just get that going ASAP? I can also start the 1990 - 2005 portion of a few more ensemble members, but I'd like to figure out the data post-processing step (time series, compression, and dumping onto glade) before I really ramp up those runs. It looks like the uncompressed output is going to be ~5 TB per ensemble member and I'd like to have a process in place before filling up my scratch space :)
Amanda Fay (Dec 16 2020 at 15:12):@Michael Levy I'd like to just look at the 2005-2006 atm blip before starting more members. I'll get on that first thing this morning and let you know when im done.
Michael Levy (Dec 16 2020 at 15:17):Michael Levy I'd like to just look at the 2005-2006 atm blip before starting more members. I'll get on that first thing this morning and let you know when im done.
I started 002 and 003 already, but was not planning on starting the RCP portion of those runs until hearing back from you. Those two runs finished '90 - '97 over night and started the 1998 - 2005 portion in the last hour... if we need to rerun the 20thC portion to get 2005 - 2006 correct, though, we have plenty of cpu-hrs.
Amanda Fay (Dec 16 2020 at 16:58):great. I confirmed that the 2005-2006 blip from CESM LENS is replicated so all should be good. Looking forward to seeing these additional ensemble members as they finish running.
Michael Levy (Dec 16 2020 at 17:06):Thanks for the verification! I'll get 2011 - 2025 going for 001, and should be able to start 2006 - 2025 for 002 and 003 tonight.
Michael Levy (Dec 17 2020 at 14:30):Okay, I botched the 2011 - 2025 period of 001 (I forgot to set CONTINUE_RUN=TRUE so I ran 2006-2020 but initialized 2006 with the 2011 restarts). Blew away all the data, and resubmitted the case itself now. Argh.
Michael Levy (Dec 18 2020 at 22:36):001 and 002 have run through 2025; 009 is through 2010 and still chugging along. History files are in
/glade/scratch/mlevy/archive/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001 /glade/scratch/mlevy/archive/b.e11.BRCP85C5CNBDRD_no_pinatubo.f09_g16.001 /glade/scratch/mlevy/archive/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.002 /glade/scratch/mlevy/archive/b.e11.BRCP85C5CNBDRD_no_pinatubo.f09_g16.002 /glade/scratch/mlevy/archive/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.009 /glade/scratch/mlevy/archive/b.e11.BRCP85C5CNBDRD_no_pinatubo.f09_g16.009
I hope to have the scripts to convert everything to time series done early next month, then I'll point to a directory in campaign storage for the output. In the meantime, I think I have enough scratch space to get another 3 members done so I'll start running 010, 011, and 012 but the rest of the runs will need to wait until I can dump output onto campaign.
Michael Levy (Dec 24 2020 at 22:36):There are 6 completed ensemble members in /glade/scratch/mlevy/archive/ if anyone wants to look at history output: 001, 002, 009, 010, 011, and 012; each ensemble member has b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.### (1990 - 2005) and b.e11.BRCP85C5CNBDRD_no_pinatubo.f09_g16.### (2006-2025). Looking at the time series generation now, then I'll get more members running.
Michael Levy (Dec 28 2020 at 23:35):I'm converting history files to time series, and it looks like the default output in the cesm1_1_2_LENS_n21 tag doesn't match what is available from the original LENS experiment. Below I list the streams I am converting to time series, as well as the number of variables in each stream:
cam.h1: 51 cam.h0: 136 cice.h1: 12 cice.h: 117 clm2.h1: 10 clm2.h0: 297 pop.h.ecosys.nyear1: 45 pop.*.nday1: 27 pop.h: 249 rtm.h1: 2 rtm.h0: 5
There are also ~25 variables in a 6-hourly CAM stream that have not been converted to time series yet. If I look in campaign and count the number of b.e11.B20TRC5CNBDRD.f09_g16.001 time series files produced, the numbers don't really add up:
atm/proc/tseries/daily: 41 atm/proc/tseries/hourly1: 0 atm/proc/tseries/hourly6: 25 atm/proc/tseries/monthly: 243 ice/proc/tseries/daily: 12 ice/proc/tseries/hourly6: 21 ice/proc/tseries/monthly: 115 lnd/proc/tseries/daily: 6 lnd/proc/tseries/monthly: 297 ocn/proc/tseries/annual: 45 ocn/proc/tseries/daily: 27 ocn/proc/tseries/monthly: 273 rof/proc/tseries/daily: 2 rof/proc/tseries/monthly: 5
The only difference with the RCP85 case is that there are only 250 monthly POP variables instead of 273.
I'll just summarize the differences between my time series and LENS. Except where noted, I haven't looked into which fields differ between the two runs.
CAM
ncl_a2_logm where the ncl_ prefix makes me wonder if some values were computed in post-processing)CICE
CLM
POP
I imagine the fields I include by default that were omitted in the original LENS are fine, but before continuing I'd like to verify that the fields we are interested in comparing between the two runs are available. @Matt Long or @Amanda Fay -- could one (or both) of you look at the output in /glade/scratch/mlevy/reshaper/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001 and make sure all the variables of interest are available? That directory is sorted by POP stream name, and the output for each stream directory is in proc/COMPLETED. E.g. monthly CAM output is in /glade/scratch/mlevy/reshaper/b.e11.B20TRC5CNBDRD_no_pinatubo.f09_g16.001/cam.h0/proc/COMPLETED. I'll work on converting the 6-hourly data as well, then I'll wait for a greenlight before continuing any more runs.
Michael Levy (Dec 29 2020 at 21:27):I've started to put together a spreadsheet to track differences in output between LENS and our experiments: https://docs.google.com/spreadsheets/d/1FwTDM4zk3VlEkviuy6ezG486dfHUFle0FfN4V9fODjQ/edit?usp=sharing
It looks like the only difference in POP is that SST is included in LENS (I believe it's just the top level of TEMP); the 23 variables dropped from 20th C to RCP are the 23 CFC variables. So the two questions I have about output are
Once I have converted the 6-hourly data to time series, I'll check back in with final storage requirements... but I think we'll have plenty of space to store the daily, monthly, and annual fields but will need to pare down the output if we want the 6-hourly output as well
(spreadsheet is still a work in progress, with the pop daily / annual fields still to do... I hope to finish those tonight)
Michael Levy (Dec 30 2020 at 00:56):Okay, the spreadsheet is done (please let me know if you have trouble accessing it, but I believe the link above should give you permission to comment on the file). Also, the time series conversion for 6-hourly data finished so I can give some updated storage numbers:
/glade/campaign/univ/udeo0005/glade/campaign/cesm/collections since it is the original LENS restart but AFAIK Gary hasn't moved those files off HPSS yet)Keeping all the restarts, annual, monthly, and daily output we have plus the 1990-2005 6-hourly data from CAM would require ~48 TB... barely sneaking in under our 50 TB limit but ignoring the fact that these runs don't have the high-frequency CICE output that LENS produced (from 1990 - 2005). I could probably save some disk space by splitting the CICE output into northern hemisphere and southern hemisphere files that ignore the ice-free portions of the grid; the original LENS output is broken into a 320x104 dataset (northern hemisphere) and a 320x76 dataset (southern hemisphere) rather than a single 320x384 dataset... though the monthly and daily CICE output is <20 GB per ensemble member as it stands so there isn't much to gain.
Matt Long (Jan 04 2021 at 16:27):Thanks @Michael Levy (and Happy New Year!).
This looks great. I am not familiar with many of the omitted CAM variables.
Regarding storage, what's the bottom line? Are we ok with the 50TB limit?
Michael Levy (Jan 04 2021 at 16:33):@Matt Long
Regarding storage, what's the bottom line? Are we ok with the 50TB limit?
We're okay if we keep the current output. If we want the 6-hourly CICE output from 1990 - 2005 I think we'll still be okay, but I need to rerun a section with that output to be sure
Michael Levy (Jan 04 2021 at 16:35):I think my two big questions are both CICE related:
nh and sh files so they are in the same format as the LENS output? This isn't a high priority if we want to use something like intake to read the data, but if we're going to be calling netcdf directly it might make it easier to use the same scripts on both the old and new datasets Amanda Fay (Jan 04 2021 at 16:40):yes, Thanks @Michael Levy ! This looks great. I found this document that gives a "long name" for these CAM variables (https://www.cesm.ucar.edu/models/cesm1.0/cam/docs/ug5_0/hist_flds_fv_cam5.html)- we are not concerned with any of these omitted CAM variables so all good from our side. But let's check with @Yassir Eddebbar as well.
Could someone direct me to where I could find the original LENS output on Cheyenne? I only have a few variables from previous analyses that were shared with me so would like to get additional files for the comparison.
Michael Levy (Jan 04 2021 at 16:42):@Amanda Fay
Could someone direct me to where I could find the original LENS output on Cheyenne? I only have a few variables from previous analyses that were shared with me so would like to get additional files for the comparison.
It's on campaign storage, so it's not mounted on Cheyenne. If you log in to Casper instead, it's /glade/campaign/cesm/collections/cesmLE/CESM-CAM5-BGC-LE
Matt Long (Jan 04 2021 at 16:44):@Marika Holland and @Laura Landrum: we have a suite of integrations of the CESM-LE without the Mt Pinatubo forcing. Do you have any interest in looking at sea ice dynamics in these runs?
We are also interested to know how much effort we should make to preserve 6-hr CICE timeseries data.
Yassir Eddebbar (Jan 04 2021 at 19:23):yes, Thanks Michael Levy ! This looks great. I found this document that gives a "long name" for these CAM variables (https://www.cesm.ucar.edu/models/cesm1.0/cam/docs/ug5_0/hist_flds_fv_cam5.html)- we are not concerned with any of these omitted CAM variables so all good from our side. But let's check with Yassir Eddebbar as well.
This looks awesome @Michael Levy , Looks good to me too @Amanda Fay , haven't used and unfamiliar with those fields as well.
Marika Holland (Jan 07 2021 at 20:08):@Matt Long We would like to look at the sea ice conditions in these runs. I don't think that the 6-hourly data are very highly utilized though and so it would be ok to remove some of the fields or move them to daily averages if you need to save space.
Matt Long (Jan 07 2021 at 21:04):Thanks @Marika Holland! Much appreciated.
@Michael Levy, note that we can remove the 6-hr data.
Michael Levy (Jan 07 2021 at 21:14):We would like to look at the sea ice conditions in these runs. I don't think that the 6-hourly data are very highly utilized though and so it would be ok to remove some of the fields or move them to daily averages if you need to save space.
@Marika Holland I just checked, and it looks like the 21 fields in the 6-hourly stream of LENS are all duplicates of fields in the monthly stream but I don't see any of them in the daily stream. Is that sufficient? I'm happy to add fields to the daily stream if you'd like more frequent output. I posted this link above, but I created a spreadsheet that lists variables in LENS, our run, or both. It is organized by stream, so the cice.h2 sheet in that link will list the 6-hourly fields available in the original LENS if you want to use that as a starting point for determining what variables should be added to daily. I think we have enough disk space from this proposal to even write these fields every 6 hours, they were just turned off by default and I didn't notice until I started comparing to the original output.
Michael Levy (Jan 07 2021 at 21:15):Thanks Marika Holland! Much appreciated.
Also, this ^^
Marika Holland (Jan 07 2021 at 22:26):@Michael Levy I added a comment to the spreadsheet under the daily stream. It'd be fine to remove the 6-hourly fields but then to add some of them to the daily fields (as requested in the comment). Thanks so much!!
Michael Levy (Jan 07 2021 at 23:10):@Marika Holland I can definitely add those fields to daily. One last question -- the 6-hourly output from the original LENS runs is only available for the 1990-2005 portion of our run; should I limit the daily streams to that time period or would it be useful to have daily output from 2006-2025 as well even without high frequency output from LENS to compare with?
Marika Holland (Jan 07 2021 at 23:14):@Michael Levy If you could add the daily fields for the entire run length, that would be great. Thanks!
Michael Levy (Jan 12 2021 at 18:41):Okay, I've run member 013 with 8 additional daily CICE fields. I've also copied all the time series from 013 and 001 (which is missing those 8 fields) to campaign storage (/glade/campaign/univ/udeo0005/cesmLE_no_pinatubo/) and verified the file count for each stream matches what the spreadsheet tells us to expect. In addition to the time series files, I've also copied all of the log files and the restart files from 2006-01-01 and 2026-01-01. I have not copied the pop.d files yet. Besides those files, am I missing anything else? Do other components have similar output files to hold on to?
One thing to note: it looks like I'm on track to need ~70 TB of disk because my scripts copied all the 6-hourly CAM output rather than just the 20thC portion. I was initially thinking we only want to keep output that the original LENS produced as well, and that run did not have 6-hourly CAM output from 2006-2025. If the 6-hourly output from the RCP run is useful even though it can't be compared with the original datasets, then we'll need to find a place to keep it. This will need to be addressed once we have 20 completed ensemble members, but we have some time to figure it out.
Michael Levy (Jul 12 2021 at 18:26):Two updates worth mentioning here:
/glade/campaign/univ/udeo0005/cesmLE_cheyenne; besides only doing the 20th Century portion of the run, I also did not compute zonal averages (though that's trivial if it would be useful to look at them)It looks like neither Nikki nor Shana have accounts here; I'll try to invite them. I think it would be great to see Shana's slides from last week updated to include more ensemble members, and also to see how the _cheyenne members compare to the original runs from yellowstone in those metrics.
Nikki Lovenduski (Jul 13 2021 at 13:00):Thanks, @Michael Levy , I'm on your Zulip now! So glad that the no-pinatubo runs are coming along -- also that you have 5 runs of the control from cheyenne. Unfortunately, shana won't be able to incorporate these additional output in to her figures, but we will use them moving forward in the project. [she's got issues with internet connectivity at her house in Arizona and only a few weeks left in her internship...]
Michael Levy (Oct 06 2021 at 16:04):@Amanda Fay @Holly Olivarez I've finished running members 27, 28, and 29 with the original forcing on cheyenne; output is on campaign and the intake catalog has been updated
Michael Levy (Oct 06 2021 at 16:17):I've also started 030 and 031, so by middle of next week we should have 50 total runs -- 25 without pinatubo, and 25 with the original forcing. At that point, we'll have enough compute time for the final eight runs but only enough disk space for one of them
Holly Olivarez (Oct 06 2021 at 16:28):Michael Levy said:
I've also started 030 and 031, so by middle of next week we should have 50 total runs -- 25 without pinatubo, and 25 with the original forcing. At that point, we'll have enough compute time for the final eight runs but only enough disk space for one of them
Oh yay! This is amazing news! Thanks, Mike!
Amanda Fay (Oct 06 2021 at 16:31):Michael Levy said:
I've also started 030 and 031, so by middle of next week we should have 50 total runs -- 25 without pinatubo, and 25 with the original forcing. At that point, we'll have enough compute time for the final eight runs but only enough disk space for one of them
maybe we can chat with the larger group about how to handle that issue of disk space. Seems like worth figuring out how to store them so we can access all 29 runs from each.
Michael Levy (Oct 12 2021 at 15:20):Michael Levy said:
I've also started 030 and 031, so by middle of next week we should have 50 total runs -- 25 without pinatubo, and 25 with the original forcing. At that point, we'll have enough compute time for the final eight runs but only enough disk space for one of them
Just to follow-up on this: all the time series is on campaign, and I've updated the intake catalog (/glade/campaign/univ/udeo0005/catalog/pinatubo_exp.json). I've submitted jobs to create zonal averages as well, so by 10:00 today that data should be available. Zonal averages still aren't available via the catalog, though
Michael Levy (Oct 12 2021 at 15:21):I wasn't going to launch any of the 8 remaining cases, though - I'd like to figure out where the output is going first.
Amanda Fay (Oct 12 2021 at 15:29):Michael Levy said:
Michael Levy said:
I've also started 030 and 031, so by middle of next week we should have 50 total runs -- 25 without pinatubo, and 25 with the original forcing. At that point, we'll have enough compute time for the final eight runs but only enough disk space for one of them
Just to follow-up on this: all the time series is on campaign, and I've updated the intake catalog (
/glade/campaign/univ/udeo0005/catalog/pinatubo_exp.json). I've submitted jobs to create zonal averages as well, so by 10:00 today that data should be available. Zonal averages still aren't available via the catalog, though
saw 30 and 31 were on campaign this morning and updating my figures now with 25 members in each ensemble. thanks mike!
Michael Levy (Oct 13 2021 at 16:34):With a lot of help from @Max Grover , I created a catalog for the zonal averages: /glade/campaign/univ/udeo0005/catalog/pinatubo_zonal_avgs.json It has zonal averages for all completed runs, and the script that updates the pinatubo_exp.json catalog after new runs will update this one as well
Michael Levy (Nov 06 2021 at 17:41):@Amanda Fay @Holly Olivarez 032 and 033 have finished running, and the catalogs in /glade/campaign/univ/udeo0005/catalog (pinatubo_exp.json and pinatubo_zonal_avgs.json) have those ensemble members in them. 034 and 035 are underway
Michael Levy (Nov 09 2021 at 18:07):@Amanda Fay @Holly Olivarez 034 and 035 are done. Woohoo!
There's a chance that the annual averages of ocean BGC diagnostics in ocn/proc/tseries/annual for member 034 (of both the no_pinatubo and LENS rerun ensembles) is a little funny; I didn't catch it at the time, but there was a history restart file for the pop.h.ecosys.nyear1 stream (b.e11.B20TRC5CNBDRD.f09_g16.034.pop.rh.ecosys.nyear1.1989-12-01-00000.nc) included in the restarts that I copied over from HPSS, so the 1990 averages from that stream may somehow include some 1989 values in them? It definitely won't impact most of the output we look at (the pop.h stream), but if we start looking closely at the annual output then I can rerun 1990 -- we have just enough compute time to run two or three more years and I'm only concerned about the output from 1990... this type of error won't propagate throughout the run
Yassir Eddebbar (Jan 07 2022 at 23:38):@Michael Levy would it be possible to get permission for the cesm_le_cheyenne netcdf files? ensembles 16-35 are blocked for me, but can access all other ensembles and other runs....
Yassir Eddebbar (Jan 07 2022 at 23:43):And ensembles 32-35 for the no_pinatubo case as well! :pray:
Michael Levy (Jan 07 2022 at 23:44):I'm running chmod -R on cesmLE_cheyenne/ as we speak -- looks like more recent ensembles are 640 instead of 644 for some reason... will do the same to the no_pinatubo next
Michael Levy (Jan 07 2022 at 23:46):you should be able to read all the ensemble members in both directories now, sorry about that!
Yassir Eddebbar (Jan 07 2022 at 23:50):Up and running! thanks @Michael Levy !
Amanda Fay (Jan 10 2022 at 16:22):thanks for getting that done @Michael Levy
Michael Levy (Jan 10 2022 at 16:24):my pleasure, let me know if there's anything else I can do :) @Yassir Eddebbar, if you're working on the interpolation to ispycnals we should make sure you have write access to those directories as well
Yassir Eddebbar (Jan 11 2022 at 00:08):@Michael Levy that would be great, so far, I'm working off my scratch...
Michael Levy (Jan 11 2022 at 23:17):@Yassir Eddebbar sorry to sit on this most of the day, but I just filed a ticket and CISL is on it:
User yeddebba has been added to the project on Cheyenne and Casper. The update may take a couple of hours to fully propagate.
Michael Levy (Jan 11 2022 at 23:18):in an hour or two, you should be in the udeo0005 group
Yassir Eddebbar (Jan 11 2022 at 23:37):Awesome! Thanks @Michael Levy !
Last updated: May 16 2025 at 17:14 UTC