Stephen Yeager (May 10 2021 at 18:28): Stephen Yeager (May 10 2021 at 18:28):
Stephen Yeager (May 10 2021 at 18:28): Stephen Yeager (May 10 2021 at 18:28):I'm trying to read in ocean temperature and salinity data from CMIP6 OMIP runs using intake-esm, as follows:
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cmip6.json' col = intake.open_esm_datastore(catalog_file) cat = col.search( experiment_id=['omip1', 'omip2','omip1-spunup','omip2-spunup'], variable_id=['thetao', 'so'], table_id='Omon' ) dset_dict = cat.to_dataset_dict()
This generates the following AggregationError: "Failed to merge multiple datasets in group with key=OMIP.CNRM-CERFACS.CNRM-CM6-1.omip1.Omon.gn into a single xarray Dataset as variables." I'd appreciate any help on this.
Matt Long (May 10 2021 at 18:59):@Stephen Yeager, I think there is a mismatch in the length of the time axis for so and thetaso. If you load these seperately for the CNRM-CM6-1 model, I think it will work (i.e., add source_id='CNRM-CM6-1' to your search and variable_id=['so'] then variable_id=['thetao'] separately).
You can use the information in cat.df, which is a pandas.DataFrame to inspect the underlying files. I think there is probably a chunk of time missing.
Deepak Cherian (May 10 2021 at 19:50):I think debugging this particular problem would be an interesting blog post. Or entry in the intake-esm documentation
Matt Long (May 10 2021 at 20:01):agreed!
Matt Long (May 10 2021 at 21:58):Anderson's talk today reminded me of the aggregate=False keyword argument to to_dataset_dict. That could be useful here too.
Daniel Marsh (Jun 16 2021 at 15:27):Hi all,
I'm trying to familiarize myself with intake-esm and accessing CMIP6 atmospheric data. I have code that reads in atmospheric variables to calculate equilibrium climate sensitivity.
It starts with reading the catalog:
#catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cmip6.json'
catalog_file = 'https://storage.googleapis.com/cmip6/pangeo-cmip6.json'
col = intake.open_esm_datastore(catalog_file)
selecting the glade catalog leads to an error when using to_dataset_dict() but does not create an error with the google catalog
It might be that it has to do google files being zarr but glade not. I tried removing the zarr_kwargs argument but that did not help. I looks like it's related to the arguments passed to xarray.open_dataset().
Ideally I would be able to access the local files and create another catalog from development runs to allow simple comparisons.
error:
OSError:
Failed to open netCDF/HDF dataset.
*** Arguments passed to xarray.open_dataset() ***:
- filename_or_obj: /glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc
- kwargs: {'chunks': {}}
*** fsspec options used ***:
- root: /glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc
- protocol: None
The file exists on glade. I have isolated the error in the following test notebook:
/glade/u/home/marsh/projects/cmip6-temperature-demo/notebooks/intake_test.ipynb
Any suggestions? Thanks,
Dan
Anderson Banihirwe (Jun 16 2021 at 15:53):@Daniel Marsh, I am looking into this... Will get back to you shortly
Michael Levy (Jun 16 2021 at 16:17):@Anderson Banihirwe it looks like the file being flagged is a softlink to a relative path:
$ ls -lh /glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc lrwxrwxrwx 1 cmip6 stdd0003 76 Sep 27 2019 /glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc -> ../files/d20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc
is it possible that intake is looking for ../files/d20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc from the working directory rather than relative to /glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/? it would be interesting to see if changing the softlink to an absolute path makes any difference
Anderson Banihirwe (Jun 16 2021 at 16:42):@Michael Levy, it's my understanding that netcdf4-python/xarray are able to open a symlink as long as the target exists....
In [1]: import xarray as xr In [2]: ds = xr.open_dataset('/glade/collections/cmip/CMIP6/CMIP/NCAR/CESM2/abrupt-4xCO2/r1i1p1f1/Amon/rsut/gn/v20190927/rsut_Amon_CESM2_abrupt-4xCO2_r1i1p1f1_gn_085001-089912.nc', chunks={}) /glade/work/abanihi/opt/miniconda/envs/playground/lib/python3.8/site-packages/xarray/conventions.py:512: SerializationWarning: variable 'rsut' has multiple fill values {1e+20, 1e+20}, decoding all values to NaN. new_vars[k] = decode_cf_variable(
My current speculation is that the issue has to with dask/intake-esm. I haven't found the exact culprit, but I have a working/temporary solution. @Daniel Marsh, I was able to read the data without a problem while using the distributed dask scheduler.
In [4]: from distributed import Client In [5]: client = Client()
If you want to use dask-jobqueue, you could replace this with the following
from ncar_jobqueue import NCARCluster from distributed import Client cluster = NCARCluter() cluster.scale(njobs=2) client = Client(cluster)
Load the catalog, and search for datasets of interest (Using the same code in /glade/u/home/marsh/projects/cmip6-temperature-demo/notebooks/intake_test.ipynb)
Load the found datasets
In [11]: dset_dict_tas = cat_tas.to_dataset_dict(preprocess = drop_time_bounds, cdf_kwargs={'chunks': {}}) In [12]: dset_dict_rad = cat_rad.to_dataset_dict(preprocess = drop_time_bounds, cdf_kwargs={'chunks': {}})
In [13]: dset_dict_rad.keys() Out[13]: dict_keys(['CMIP.NCAR.CESM2-FV2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM-FV2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM.piControl.Amon.gn', 'CMIP.NCAR.CESM2-FV2.piControl.Amon.gn', 'CMIP.NCAR.CESM2-WACCM-FV2.piControl.Amon.gn', 'CMIP.NCAR.CESM2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2.piControl.Amon.gn']) In [14]: dset_dict_tas.keys() Out[14]: dict_keys(['CMIP.NCAR.CESM2-WACCM-FV2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM.piControl.Amon.gn', 'CMIP.NCAR.CESM2-FV2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2.piControl.Amon.gn', 'CMIP.NCAR.CESM2.abrupt-4xCO2.Amon.gn', 'CMIP.NCAR.CESM2-WACCM-FV2.piControl.Amon.gn', 'CMIP.NCAR.CESM2-FV2.piControl.Amon.gn'])
Anderson Banihirwe (Jun 16 2021 at 16:44):My current speculation is that the issue has to with dask/intake-esm. I haven't found the exact culprit, but I have a working/temporary solution.
I will do a full investigation of the issue in the coming days....
Daniel Marsh (Jun 16 2021 at 17:10):Thanks - that works! Since I was planning on using dask anyway this is good.
NCAR CMIP6 CESM ECS calculation here: /glade/u/home/marsh/projects/cmip6-temperature-demo/notebooks/CESM_ECS.ipynb
Daniel Marsh (Jun 23 2021 at 18:53):All, I cannot seem to get plot to work with CESM " (time) object 0210-02-01 00:00:00 ... 0210-01-01 00:00:00" as the x-axis when reading in datasets via intake-esm. Even with installing nc-time-axis, I get the error:
TypeError: float() argument must be a string or a number, not 'cftime._cftime.datetime'
Opening the file using xr.open_datset will plot the same data without issue.
A notebook to extract zonal wind in the tropical stratosphere and make a simple plot is here and re-creates the error:
/glade/u/home/marsh/WACCM/waccm_1deg_MA/read_catalog.ipynb
In the same directory is the notebook that created the catalog from WACCM timeseries data (WACCM/waccm_1deg_MA/create_intake_catalog.ipynb)
Fearing it was a set up issue, yesterday I deleted my whole miniconda3 install and reinstalled, added Max's latest ecgtools and udpated matplotlib and xarray. It still does not work.
Matt Long (Jun 23 2021 at 23:22):@Daniel Marsh, I was not able to reproduce this error in your notebook using xarray verion 0.17.0.
Daniel Marsh (Jun 24 2021 at 01:02):@Matt Long Thanks for trying. Max reported something similar. Well, I was able to get it to work, but I am not sure why you were able to make it work without modifications. The change I had to make was adding 'decode_times': False to cdf_kwargs
dsets = cat.to_dataset_dict(cdf_kwargs={'chunks': {'time': 8}, 'decode_times': False})
then I added decode_cf and sortby
k = 'atm.cam.h0.b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918'
ds = dsets[k]
ds = xr.decode_cf(ds)
ds = ds.sortby('time')
This seemed to work. It was a bit of surprise that when extracting a timeseries from dsets that the data were not sorted in time - this is a long historical pre-industrial run which spanned 011001 to 026212 compositing 4 separate netcdf files. Without sorting the first entry was year 0210-02-01 00:00:00 (the first entry in the 3rd file). After sorting it was 0110-02-01 00:00:00. A potential gotcha if you take the values before sorting.
Anderson Banihirwe (Jun 24 2021 at 16:28):This seemed to work. It was a bit of surprise that when extracting a timeseries from dsets that the data were not sorted in time
This is a bug in intake-esm: https://github.com/intake/intake-esm/issues/343. I will look into it next week
Daniel Marsh (Jul 14 2021 at 20:56):All, I am trying to make a catalog that includes multiple cases of a particular model configuration of CESM (WACCM with middle atmosphere chemistry at 1 degree). The data are all under /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/
The runs are a PI control (BWma1850), 4xCO2 (BWmaCO2x4), an ensemble of 3 historical simulations (BWmaHIST) and an SSP245 (BWSSP245).
I am interested only the timeseries atmospheric data at 1- and 5-day and monthly resolution, so had to include a lengthy exclude pattern:
depth=5,
exclude_patterns=["*/cpl/*", "*/esp/*", "*/glc/*", "*/ice/*", "*/lnd/*", "*/logs/*", "*/ocn/*", "*/rest/*", "*/rof/*", "*/wav/*", "*/atm/h6/*", "*/atm/hist/*", "*/atm/proc/h*", "*/atm/proc/*_RESTOM.nc"],
Unfortunately, the catalog I create only lists one case:
dict_keys(['atm.cam.h0.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001', 'atm.cam.h6.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001', 'atm.cam.h7.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001'])
here h0 is monthly, h6 is daily and h7 is 5-day output for just the 4xCO2 case.
I can create a case by case catalog by specifying the full path (e.g., b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918/atm/proc/tseries/month_1/) and depth = 1, but I'd prefer to have all the cases in one catalog so I can compute, for example, climate sensitivity (requires PI control and 4xCO2)
Any suggestions as to what I am doing wrong?
I've put my full notebooks on github here: https://github.com/dan800/intake-esm.git
thanks,
Dan
Anderson Banihirwe (Jul 14 2021 at 22:01):@Daniel Marsh,
Can you confirm that you have access to all directories under /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg? I am asking because when I try accessing a file under the b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001 case, I get a permission denied error:
$ ncdump -h /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/day_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h1.ACTNL.20150101-20241231.nc ncdump: /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/day_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h1.ACTNL.20150101-20241231.nc: /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/day_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h1.ACTNL.20150101-20241231.nc: Permission denied
Daniel Marsh (Jul 14 2021 at 22:08):@Anderson Banihirwe ,
It looks like I do:
ncdump -h /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/day_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h1.ACTNL.20150101-20241231.nc
netcdf b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h1.ACTNL.20150101-20241231 {
dimensions:
lat = 192 ;
zlon = 1 ;
nbnd = 2 ;
lon = 288 ;
time = UNLIMITED ; // (3650 currently)
chars = 8 ;
lev = 70 ;
ilev = 71 ;
Anderson Banihirwe (Jul 14 2021 at 22:15):Okay... It looks like it's just me who lacks read permissions :frown:
Daniel Marsh (Jul 14 2021 at 22:21):That is frustrating - I have no idea why read permissions are group restricted. I can try to get that opened up. Do you see any problems with how I have tried to create my catalog?
Anderson Banihirwe (Jul 14 2021 at 22:25):Do you see any problems with how I have tried to create my catalog?
Everything looks good (which is why I wanted to see what's going on with the files themselves)..
Which version of ecgtools are you using?
import ecgtools print(ecgtools.__version__)
Daniel Marsh (Jul 14 2021 at 22:28):I am using: 0.0.post44
Daniel Marsh (Jul 14 2021 at 22:52):Possibly (probably) a dumb question, but do all directories have to have the same output? What happens if, for example, daily U is not in all the atm/proc/tseries/day_1 directories?
Anderson Banihirwe (Jul 15 2021 at 00:18):Aha! That could be the problem... Try the unreleased version from the main branch
python -m pip install git+https://github.com/NCAR/ecgtools.git
And then run the following test to see if you get valid output
In [1]: from ecgtools.parsers.cesm import parse_cesm_timeseries In [2]: path = "/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/month_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h0.ACTREL.206501-209912.nc" In [3]: parse_cesm_timeseries(path)
Anderson Banihirwe (Jul 15 2021 at 00:24):but do all directories have to have the same output?
They don't have to... For CESM output, the metadata information for each file comes from two places
(1) attributes such as stream, case, variable come from the filename e.g. (b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h0.ACTREL.206501-209912.nc
(2) attributes such as frequency are harvested from global attributes within the netCDF file
Daniel Marsh (Jul 15 2021 at 15:15):@Anderson Banihirwe
Apologies for the long reply below!
Okay, I installed the unrealeased version. That didn't seem to fix the issue. I still only get 3 streams for one case:
dict_keys(['atm.cam.h0.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001', 'atm.cam.h6.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001', 'atm.cam.h7.b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001'])
@Mike Mills added read permissions to the following directories (thanks Mike!):
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918/',
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWmaHIST.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.003/',
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWmaCO2x4.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/',
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWmaHIST.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.002/',
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWmaHIST.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/',
The SSP case is owned by someone else but perhaps you could exclude that in your test?
'/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/'
I did notice that when I isolate just a few of these files (e.g., /glade/u/home/marsh/scratch/WACCM6-MA-1deg/) the parser doesn't like the c20200918 in the case name and gives invalid assets - I guess it's expecting 001, 002, etc. However, it does produce a catalog with multiple cases and streams if I do this:
esm_dir = "/glade/u/home/marsh/scratch/WACCM6-MA-1deg/"
b = Builder(
# Directory with the output
esm_dir,
# Depth of 1 since we are sending it to the case output directory
depth=3,
exclude_patterns=["*/b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918/*"],
njobs=1
)
Perhaps @Mike Mills can comment on if this is a one-off case name or a new naming convention?
So, I think it's working but not when I point to the large set of files on campaign. I could try writing a script to create a directory filled with symbolic links of only the timeseries files for all these cases and point the Builder() to that. This might be better since I don't think we need to have all the 315 variables held in separate monthly timeseries files in the catalog (it does slow things down a lot). The object for me is to create a catalog I can point a diagnostic analysis package to, containing multiple cases and key fields (U,V,T,O3,TOA fluxes) at various temporal frequencies. It might be nice to have an include_only_patterns argument to Builder() so I don't have to exclude some many directories and files.
Anderson Banihirwe (Jul 15 2021 at 15:53):@Daniel Marsh, it sounds like the issue resides in parse_cesm_timeseries function (this function doesn't cover all edge cases :frown:)
Could you run the following code snippet on one of files that aren't appearing in the catalog:
In [1]: from ecgtools.parsers.cesm import parse_cesm_timeseries In [2]: path = "/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/month_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h0.ACTREL.206501-209912.nc" In [3]: parse_cesm_timeseries(path)
The output of this function may have some hints on what's not working when parsing some of the files...
It might be nice to have an include_only_patterns argument to Builder() so I don't have to exclude some many directories and files.It might be nice to have an include_only_patterns argument to Builder() so I don't have to exclude some many directories and files.
:+1: Yeah this would be a great addition. I'll look into it
Max Grover (Jul 15 2021 at 16:37):Ahh another problem here might be that we are using the parse_cesm_timeseries parser when we should use the parse_cesm_history. Although these files have multiple times, there are multiple variables (the timeseries within ecgools refers to files that have one variable, with multiple times, output from the various timeseries generation tools). Also, within the filename, the timeseries parser is looking for the start and end time. I ran the revised version from the PR on ecgtools, and it works for those files you mentioned @Daniel Marsh
Daniel Marsh (Jul 15 2021 at 16:52):@Max Grover I am only trying to point to single variable timeseries files in the tseries/month_1, day_5 and day_1 directories. I don't think any of them have multiple variables. Elsewhere, there's a lot of other stuff (h0s with many vars) in these case directories that I have done my best to exclude them.
Daniel Marsh (Jul 15 2021 at 16:54):@Anderson Banihirwe
That code segment worked fine:
{'component': 'atm',
'stream': 'cam.h0',
'case': 'b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001',
'member_id': 1,
'variable': 'ACTREL',
'start_time': '2065-01',
'end_time': '2099-12',
'time_range': '206501-209912',
'long_name': 'Average Cloud Top droplet effective radius',
'units': 'Micron',
'vertical_levels': 1,
'frequency': 'month_1',
'path': '/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001/atm/proc/tseries/month_1/b.e21.BWSSP245.f09_g17.release-cesm2.1.3.WACCM-MA-1deg.001.cam.h0.ACTREL.206501-209912.nc'}
Max Grover (Jul 15 2021 at 16:58):@Daniel Marsh sounds good- it looks like this file does have multiple variables and multiple times /glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918/atm/h6/b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918.cam.h6.0208-01-01-00000.nc, which was one of the files which required the history parser... the 3D variables (time, lat, lon) include:
THzm - zonal mean potential temperatureUVzm - Meridonal Flux of Zonal MomentumUWzm - Vertical Flux of Zonal MomentumUzm - Zonal Mean Zonal WindVTHzm - Meridional heat fluxVzm - Zonal mean meridional windWzm- Zonal mean vertical wind Daniel Marsh (Jul 15 2021 at 17:02):@Max Grover "*/atm/h6/*" is in my exclude patterns so that's odd. Does * not begin below the the data dir which is the first argument to Builder?
Max Grover (Jul 15 2021 at 17:17):Ohhh good point. Sorry! I tried testing this on the first directory I saw it the atmosphere component.
Max Grover (Jul 15 2021 at 18:18):@Daniel Marsh changing the depth from 5 to 4 seemed to solve the problem. Using this block for setting up the builder works
# esm_dir = "/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/b.e21.BWma1850.f09_g17.release-cesm2.1.3.c20200918/atm/proc/tseries/month_1/" esm_dir = "/glade/campaign/cesm/development/wawg/WACCM6-MA-1deg/" b = Builder( # Directory with the output esm_dir, # Depth of 1 since we are sending it to the case output directory depth=4, # Exclude the other components, hist, and restart directories # and pick out the proc timeseries for 1- and 5-day and monthly data exclude_patterns=["*/cpl/*", "*/esp/*", "*/glc/*", "*/ice/*", "*/lnd/*", "*/logs/*", "*/ocn/*", "*/rest/*", "*/rof/*", "*/wav/*", "*/atm/h6/*", "*/atm/hist/*", "*/atm/proc/h*", "*/atm/proc/*_RESTOM.nc", "*/archive/*"], # Number of jobs to execute - should be equal to # threads you are using njobs=-1 )
Anderson Banihirwe (Jul 15 2021 at 18:20):@Daniel Marsh changing the depth from 5 to 4 seemed to solve the problem. Using this block for setting up the builder works
something strange is going on with how depth is used to crawl list of directories... (most likely an ecgtools bug)
Max Grover (Jul 15 2021 at 18:25):@Daniel Marsh could you install from the main branch? We merged the PR that fixes the issues you raised
Daniel Marsh (Jul 15 2021 at 20:44):@Max Grover and @Anderson Banihirwe
I made the change and updated to 2021.6.21.post2 and all looks good! Thanks very much. Now onto using it!
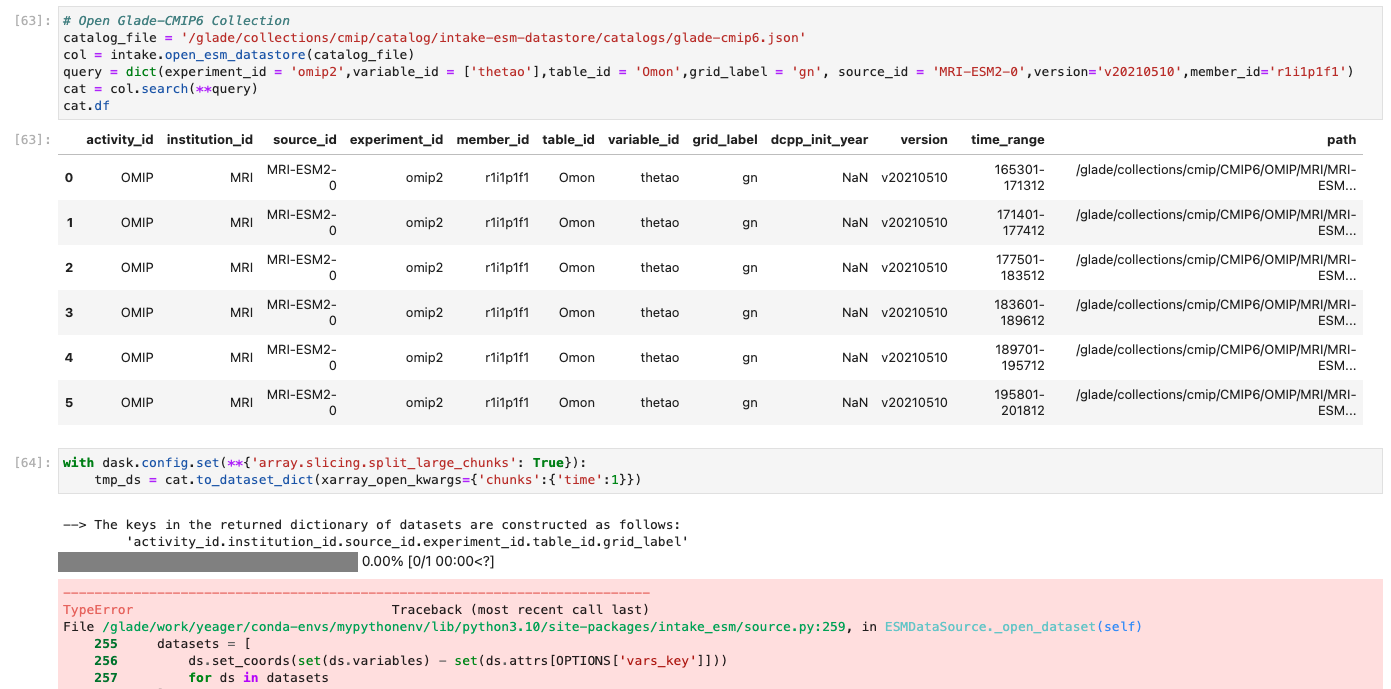
Stephen Yeager (Dec 10 2023 at 16:22):I'm having trouble using intake v0.7.0 to access data from the CMIP6 catalog on glade. The catalog appears to include the OMIP2 data I'm interested in, but the call to to_dataset_dict fails with error Failed to load dataset with key='OMIP.MRI.MRI-ESM2-0.omip2.Omon.gn'. The data files are sitting on glade here: /glade/collections/cmip/CMIP6/OMIP/MRI/MRI-ESM2-0/omip2/r1i1p1f1/Omon/thetao/gn/v20210510/thetao/, so I don't know why intake is failing.
Screenshot-2023-12-10-at-9.08.02-AM.png
Stephen Yeager (Dec 12 2023 at 18:34):@Michael Levy Hi Mike, I think there might be issues with the json file I'm reading using intake. Do you have any recommendations for how to debug an issue with to_dataset_dict?
Michael Levy (Dec 12 2023 at 18:35):Did /glade/collections get moved to campaign?
Michael Levy (Dec 12 2023 at 18:35):I see /glade/campaign/collections/cmip/CMIP6/ but not OMIP in that subdirectory
Michael Levy (Dec 12 2023 at 18:38):oh, sorry... for some reason /glade/collections/ is available from casper but not derecho. Let me look into this a little bit
Michael Levy (Dec 12 2023 at 18:50):It looks like you need an additional xarray_open_kwargs key: I was able to open the data but updating your last line to the following
with dask.config.set(**{'array.slicing.split_large_chunks': True}):
ds = cat.to_dataset_dict(xarray_open_kwargs={'chunks':{'time':1}, 'use_cftime': True})
I tracked this down because the full error message included
TypeError: Cannot combine along dimension 'time' with mixed types. Found: DatetimeProlepticGregorian, Timestamp. If importing data directly from a file then setting `use_cftime=True` may fix this issue.
The above exception was the direct cause of the following exception:
I wonder if maybe a default changed somewhere in xarray and so this wasn't necessary before but is now?
Stephen Yeager (Dec 13 2023 at 19:48)::+1: Thanks. The additional xarray_open_kwargs argument solved this issue.
Last updated: May 16 2025 at 17:14 UTC