Alice DuVivier (Aug 26 2021 at 22:30): Alice DuVivier (Aug 26 2021 at 22:30):
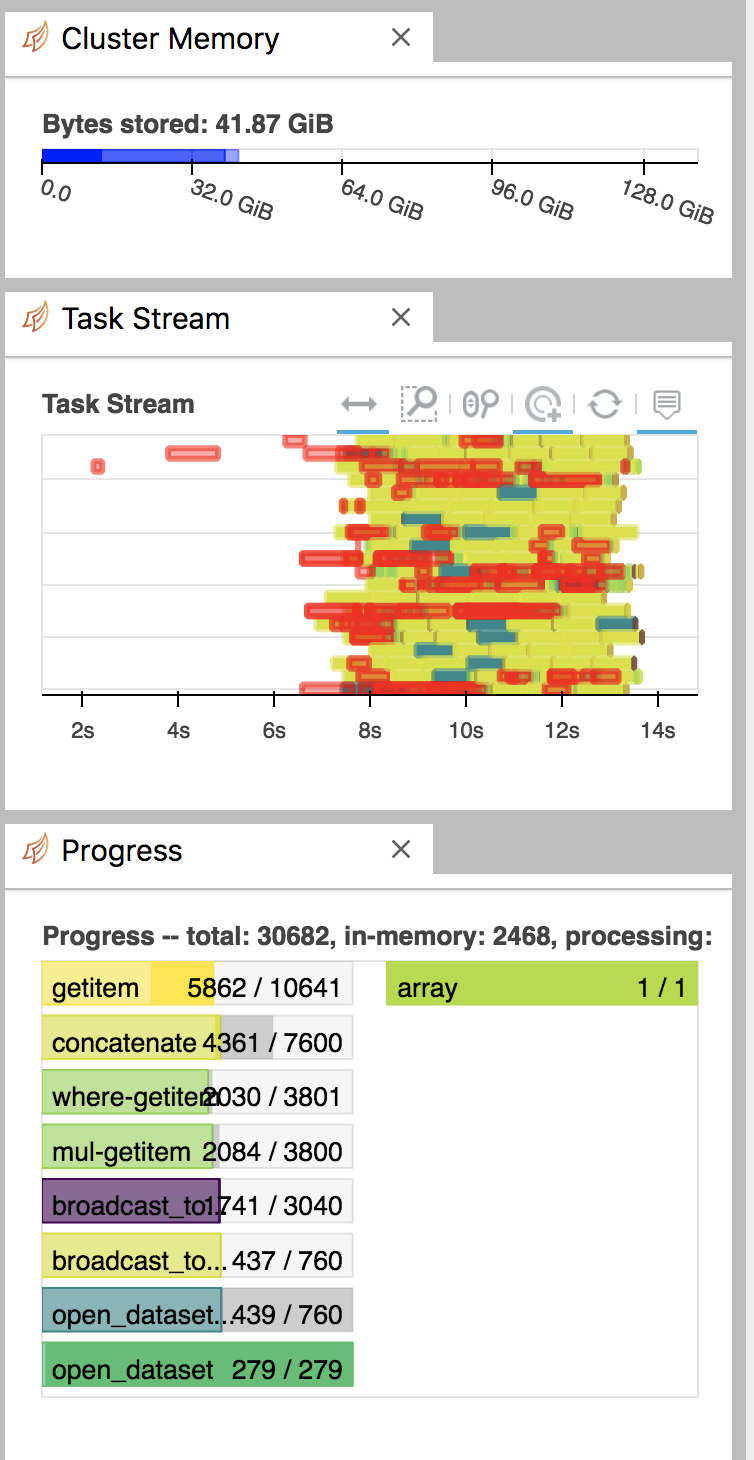
Alice DuVivier (Aug 26 2021 at 22:30): Alice DuVivier (Aug 26 2021 at 22:30):@Maria Molina and I are working on a notebook to extract data from the CESM2-LE for self organizing maps. We're using the intake-esm example and therefore dask. We keep getting an error about killed workers in DASK. (see below for error). We're unsure the solution. We've tried doing some of the calculations earlier (e.g. a .persist earlier in the notebook) but maybe the solution is we need more workers or memory or cores. Is there any guidance for how to navigate this sort of error in DASK? @Max Grover @Anderson Banihirwe , you may have some DASK specific guidance as well and I've worked with both of you on aspects of this notebook already.
KilledWorker: ('open_dataset-10b51ac878a730e7158c2de0c868d102coast_mask-dc1e9cae81941bac9542c4296cdde25b', <WorkerState 'tcp://10.12.206.8:43462', name: PBSCluster-9, memory: 0, processing: 44>)
Max Grover (Aug 27 2021 at 14:47):Unfortunately, there typically is not an easy answer to that... you can try allocating more memory/workers, checking the size of your chunks, and breaking the computation into smaller portions. We put together some documentation on this on the ESDS FAQ page, but this may not completely solve your problem. I encourage you stop by our office hours on Monday, we can try taking a look at the Dask dashboard to see if we can diagnose the problem if that works?
Alice DuVivier (Aug 27 2021 at 15:27):Okay, I'll see how far I can get today with the FAQ, but otherwise I'll see you again at office hours next week. Thanks! :)
Deepak Cherian (Sep 01 2021 at 03:09):congratulations! you have found an xarray bug =)
When you stack member_id and time. into a new dimension it consolidated that into one giant 8GB chunk, which causes all the trouble. Good news is that if you subset in latitude early enough (since most of the domain is useless for what you want to do) everything works perfectly fine on my end.
Here's the notebook with some notes and suggestions: soms_antarctica-gettingdata.ipynb
Maria Molina (Sep 01 2021 at 04:04):Awesome!! Thanks @Deepak Cherian !
Alice DuVivier (Sep 01 2021 at 21:50):Thanks! I will give that a try. :)
Alice DuVivier (Sep 02 2021 at 17:42):@Deepak Cherian I downloaded the notebook that appears to be attached to your message, but I looked through and don't see the notes or suggestions (I also diffed it with the notebook I sent you and the diff came back with no changes). Am I missing something obvious here?
Deepak Cherian (Sep 02 2021 at 18:51):ouch it didn't save in that case (the notebook was open read-only in your directory, i assumed that it would add my changes when I clicked download).
IIRC the main suggestion was to use ds.isel(time=ds.time.dt.month.isin([10, 11, 12])) to pick out OND months.
I also added compat="override" in various open_mfdataset / concat lines to prevent constructing giant 5D TAREA arrays though I don't think that affected the final computation
Alice DuVivier (Sep 10 2021 at 19:34):@Deepak Cherian I just got a chance to try your suggestions, but just adding the ds.isel(time=ds.time.dt.mont.isin([4,5,6,7,8,9,10])) wasn't enough to prevent all the killed workers. Would you mind coming to office hours on Monday so you and I can talk about it again? Or if that time doesn't work for you, maybe we could find another time?
Deepak Cherian (Sep 10 2021 at 21:04):For the killed workers, you should subset in latitude early (before stacking) since most of the domain is useless for what you were trying.
Alice DuVivier (Sep 10 2021 at 22:31):Update: I added a .persist() right before I did the big calculation and it hasn't died (yet). I'm keeping my fingers crossed...
I tried dropping the unused horizontal values a lot sooner and then subsetting time, all before stacking, and I still ended up with the Killed Worker error. Were you able to get it to work in your testing? If so, I wonder if I'm still missing some crucial piece.
Deepak Cherian said:
For the killed workers, you should subset in latitude early (before stacking) since most of the domain is useless for what you were trying.
Deepak Cherian (Sep 13 2021 at 15:40):Just before section 4, I executed ds_ice_winter.load() (I chose to do this because that array is now only 1GB) and it works fine with 10 workers and 15GB memory each.
image.png
I did skip this cell which seems useless? It doesn't seem to drop anything.
ds_ice_masked_subset = ds_ice_masked_subset.where(ds_ice_masked_subset!=-999.999, drop=True)
I recommend updating dask and distributed (i'm running 2021.7.2). There've been a lot of updates recently that apparently help with reducing memory usage. Maybe one of those improvements has drastically improved this sequence of operations.
numpy : 1.21.1
distributed: 2021.7.2
cartopy : 0.19.0.post1
matplotlib : 3.4.2
intake : 0.6.2
xarray : 0.19.0
pandas : 1.3.1
cftime : 1.5.0
dask : 2021.7.2
Ok, I was able to load the data this way and not kill all the dask workers. So that's a success. However, when I move on to the next step I remembered the reason I'd originally gone in the order of operations that created the Dask problem. There is an issue with xarray with dropping nans - basically it doesn't work. And the SOM algorithm can't have nans, so we have to figure out a way to drop them.
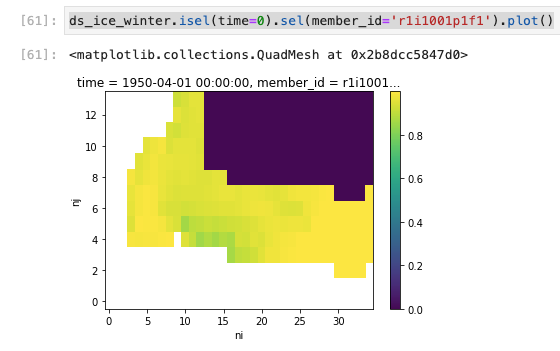
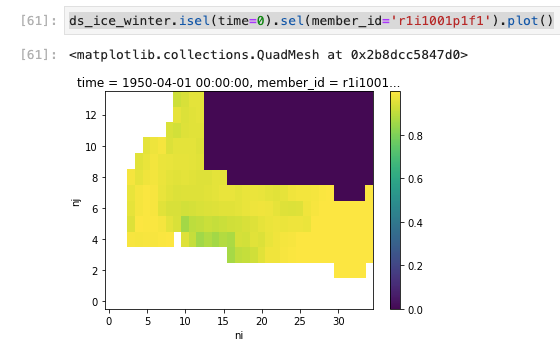
As it stands now, I have an array ds_ice_winter with shape (25 -members, 21614 - time, 14 - nj, 35 - ni) that is significantly reduced in 2D size from the global data. Here's the first timestep, basically all the purple is a nan currently and this is invariant in time. All those values should be dropped so the SOM doesn't train with them.
Screen-Shot-2021-09-14-at-3.43.24-PM.png
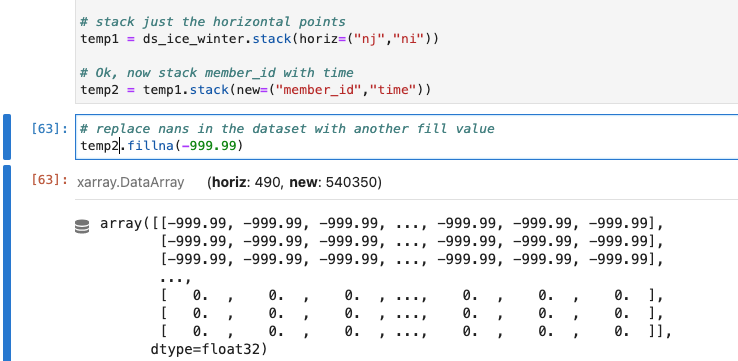
So I stack the horizontal points and then the members and replace all the nans with a fill number. This seems to work. I can see that for temp2 there are -999.99 values but I have checked and not all the values are the missing.
Screen-Shot-2021-09-14-at-3.48.37-PM.png
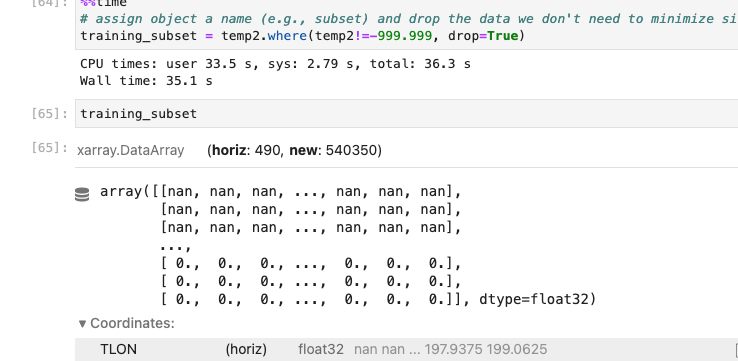
However, when I try to drop the values that are equal to -999.99, it doesn't seem to work and just returns an array with all the nans back.
Screen-Shot-2021-09-14-at-3.48.47-PM.png
@Maria Molina and I have both worked on this and can't figure out a way to replace the nans in a way that they will be dropped by xarray. Xarray seems to remember from way back with the masking by the location that these are missing and won't let them go.
Any suggestions? We're stumped.
Anderson Banihirwe (Sep 14 2021 at 23:57):@Alice DuVivier,
However, when I try to drop the values that are equal to -999.99, it doesn't seem to work and just returns an array with all the nans back.
Consider this array
In [57]: array = xr.DataArray([[1., 1., 0.], [0., 1., 0.]], dims=['x','y'], coords={'x':np.arange(2)})
In [58]: array
Out[58]:
<xarray.DataArray (x: 2, y: 3)>
array([[1., 1., 0.],
[0., 1., 0.]])
Coordinates:
* x (x) int64 0 1
Dimensions without coordinates: y
Masking zeros results in this array...
In [59]: array.where(array != 0)
Out[59]:
<xarray.DataArray (x: 2, y: 3)>
array([[ 1., 1., nan],
[nan, 1., nan]])
Coordinates:
* x (x) int64 0 1
Dimensions without coordinates: y
Notice the location of the NaNs. Assuming we want to preserve the dimensionality of our original array, dropping all NaNs in this 2D array would leave us with an awkward array. To drop everything we would have to collapse the result to a 1D array. Because xr.where(.... drop=True) preserves the dimensionality of the array, it drops as many values as possible while setting data values to NaN where necessary.
In [60]: array.where(array != 0, drop=True)
Out[60]:
<xarray.DataArray (x: 2, y: 2)>
array([[ 1., 1.],
[nan, 1.]])
Coordinates:
* x (x) int64 0 1
Dimensions without coordinates: y
I hope this helps explain why you are getting some NaNs when using drop=True...
Anderson Banihirwe (Sep 15 2021 at 00:07):If you don't mind collapsing your results to a 1D array + losing coordinate/dimension information, you can use NumPy's where() in conjunction with slicing:
In [79]: slice_mask = np.where(array.data != 0)
In [80]: array.data[slice_mask]
Out[80]: array([1., 1., 1.])
@Anderson Banihirwe Okay, I see your point, however in this case it would be okay to drop the nan locations because they should be the same for every time entry because they correspond to a time-invariant spatial mask.
Consider the image below - it's sea ice concentration in a very specific region. We want to train a self organizing map (SOM) on these values. In the figure all the purple points, which are the nans, will remain purple points for the full 100+ years of data we are looking at. The purple points correspond to areas we don't want to consider for training. The SOM uses a 1D vector array for each timestep we provide, and we provide many timesteps to train with. Thus, we've flattened (or stacked) the xy data so that there's just a single array of values corresponding to the yellow and purple areas.
image.png
However the SOM doesn't really need the time invariant points to train, so being able to reduce the size of the array passed to the SOM would be optimal. Thus, the desire to just drop the NaN points rather than keeping track of them. From that quick figure above you can see that probably 1/3-1/2 the domain is nans, so that's a lot of nans we want to drop to make the SOM process more efficient. Also, the SOM algorithm doesn't accept a "NaN" value, so at worst we could set the NaNs to something non-physical like -999 to be able to identify them but not break the algorithm.
The equivalent might be like the following array:
([[1.0, 0.8, 1.0, nan, nan, 0.5, nan, 1.0],
[0.9, 0.8, 0.9, nan, nan, 0.6, nan, 1.0],
[0.9, 0.9, 0.8, nan, nan, 0.5, nan, 0.9],
..... (many more times here)])
imagine this array.shape = [8, 10,000]
For each training time the nan stays in the same location for the vector. Thus, it would be more efficient to pass the following data to the SOM to train the following ideal array. In this case for each of the 10,000 time vectors there are only 5 values to train on rather than 8.
([[1.0, 0.8, 1.0, 0.5, 1.0],
[0.9, 0.8, 0.9, 0.6, 1.0],
[0.9, 0.9, 0.8, 0.5, 0.9],
..... (many more times here)])
imagine this array.shape = [5, 10,000]
Does this make sense what I'm trying to do better and why I just want to drop those values?
I see the comment that maybe the np.where could be used. However, I do not want to end up with the following by losing dimensionality:
[1.0, 0.8, 1.0, 0.5, 1.0, 0.9, 0.8, 0.9, 0.6, 1.0, 0.9, 0.9, 0.8, 0.5, 0.9, ....]
I could maybe loop through all the times and apply it to each time individually, but that seems inefficient. But maybe that's the way to do it? As I said, @Maria Molina and I have been trying to get around this and are stumped.
Deepak Cherian (Sep 15 2021 at 03:51):@Alice DuVivier Anderson's point is that there's a data model problem
This example array (which I think looks like your end goal)
[[1, 2],
[1, 2, 3]]
is not a regular array. It is "ragged" or "awkward" since the rows are of different lengths. These arrays cannot be represented by numpy arrays so xarray cannot represent them either. I think your choices are to flatten again to a 1D array then drop NaNs; or use a sentinel value like -999 and preserve the 2 dimensions.
Deepak Cherian (Sep 15 2021 at 04:04):oh :face_palm: this figure is misleading. Ignore my last comment
I think you want to experiment with
mask_stacked = mask.stack(horizontal=("nj", "ni"))
data.stack(horizontal=("nj", "ni")).where(mask_stacked, drop=True)
basically stack the data and mask the same way to flatten the horizontal dimension; then drop.
Alice DuVivier (Sep 15 2021 at 17:45):@Deepak Cherian Yes! It worked to stack the mask and the data and then drop that way rather than try to use the 2d mask with the data. Thanks so much! I know this took a lot of time for a lot of people. :)
Deepak Cherian (Sep 15 2021 at 18:47):Nice! Would you mind writing a very short summary of the lessons learned from this debugging discussion? I think we could make that a nice FAQ entry.
Alice DuVivier (Sep 21 2021 at 17:49):Yes, sure. I was out at the end of last week so just saw this, but I can work on it. :)
Alice DuVivier (Oct 01 2021 at 15:12):I'm trying to load some CESM2-LE members using the same intake-esm process I've used in the past. When I get to the point of doing ds.load() on the actual data I get this error:
distributed.scheduler - ERROR - Couldn't gather keys {"('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 12, 18, 0, 0)": ['tcp://10.12.206.32:33999'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 20, 6, 0, 0)": ['tcp://10.12.206.35:40111'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 36, 1, 0, 0)": ['tcp://10.12.206.35:40111'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 47, 10, 0, 0)": ['tcp://10.12.206.37:40422'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 14, 14, 0, 0)": ['tcp://10.12.206.56:44976'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 36, 10, 0, 0)": ['tcp://10.12.206.37:40422'], ... (lots more)
Any idea if this is a dask issue, a casper issue, or something else that might cause this error?
Alice DuVivier (Oct 01 2021 at 19:43):Alice DuVivier said:
I'm trying to load some CESM2-LE members using the same intake-esm process I've used in the past. When I get to the point of doing ds.load() on the actual data I get this error:
distributed.scheduler - ERROR - Couldn't gather keys {"('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 12, 18, 0, 0)": ['tcp://10.12.206.32:33999'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 20, 6, 0, 0)": ['tcp://10.12.206.35:40111'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 36, 1, 0, 0)": ['tcp://10.12.206.35:40111'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 47, 10, 0, 0)": ['tcp://10.12.206.37:40422'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 14, 14, 0, 0)": ['tcp://10.12.206.56:44976'], "('concatenate-04c2be37fdc22c875ee22a7ba14c10e9', 36, 10, 0, 0)": ['tcp://10.12.206.37:40422'], ... (lots more)Any idea if this is a dask issue, a casper issue, or something else that might cause this error?
It looks like it's related to killed dask workers, so I'll follow on that and see if I can sort it out.
Alice DuVivier (Oct 01 2021 at 20:24):Alice DuVivier said:
It looks like it's related to killed dask workers, so I'll follow on that and see if I can sort it out.
And just to round this out, I was able to get around the problem by using a .persist() instead of a .load() where I had been trying to load the data, and it seems to have worked fine and got past the problem. So issue has been solved (for now)!
Alice DuVivier (Oct 06 2021 at 19:13):@Max Grover I have been working with more CESM2-LE data and am a bit confused about how DASK breaks up chunks. I am loading some 3D, 5-day average data using intake-esm. Unsurprisingly the 3D fields and high temporal frequency mean I'm dealing with a lot of data here.
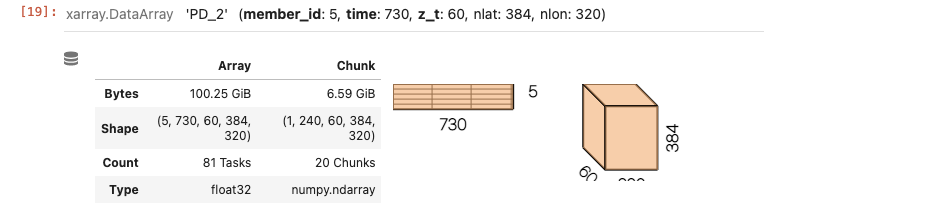
Initially I had been trying to load all possible data and it looked like the chunk size was relatively reasonable (140MB): Screen-Shot-2021-10-06-at-1.07.02-PM.png
However, when I actually try to load the data I get the killed worker error message.
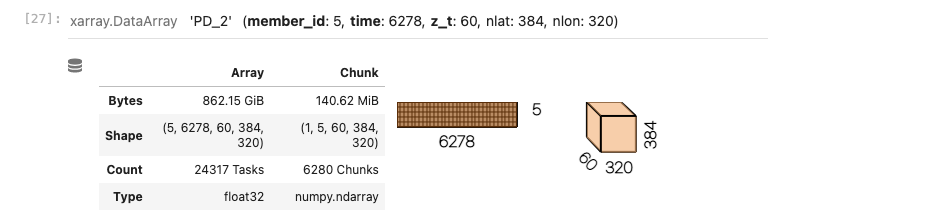
So I tried reducing the files I loaded in using intake esm to just use start_time for the period I'm interested in. I thought this might reduce the chunk size since I really only want 10 years, not the full 2015-2100 record. However, this has resulted in an even larger chunk size (6GB) with many fewer chunks. Screen-Shot-2021-10-06-at-1.06.26-PM.png
I guess my question is how to get around this. I thought using intake-esm to load a minimum number of files would be helpful, but since it wasn't maybe I need to manually adjust chunk size and/or number of chunks? I've also tried using .load() or .persist() in different spots in the code, but the result is still the killed worker situation. Advice would be welcome.
Max Grover (Oct 06 2021 at 19:19):Did you specify the chunksize when you read in the dataset? For example, if you want 5 times each chunk, you could specify this using the following:
dsets = catalog.to_dataset_dict(cdf_kwargs={'chunks': {'time': 5}})
The chunks dictionary is used in xarray when using open_mfdataset. I would manually set this to make sure xarray does not try to assume anything...
Alice DuVivier (Oct 06 2021 at 20:00):That was successful. Thanks, I'd forgotten about that little switch you can take. :)
Alice DuVivier (Mar 15 2022 at 19:21):I am having more issues with Dask and Killed Workers error messages. I am trying to load CESM2-LE 3D U and V data from CAM to calculate wind speed. It appears that the data load fails on the np.sqrt step when I look at the Dask Status page to track tasks, but I'm not sure that's really where the problem is.
I have tried reducing the chunksize (as Max had suggested back in October when I had similar issues) and that has not worked. I am at a bit of a loss of what to try next. @Anderson Banihirwe @Deepak Cherian , it seems like you're both Dask whisperers, any thoughts?
PS. I seem to be the only one here with Dask issues - hah!
Anderson Banihirwe (Mar 15 2022 at 20:22):@Alice DuVivier, Can you point me to the notebook you are using? I'm happy to look into this
Alice DuVivier (Mar 15 2022 at 20:56):@Anderson Banihirwe Yes, thanks!
| /glade/p/cgd/ppc/duvivier/cesm2_arctic_cyclones/rufmod_analysis/version_3/wind_response/wind_trends_vertical.ipynb
Partway down you'll see my note STOP right after I try loading things because that's where I was getting stuck. Please let me know if you have other questions. I really appreciate the help. :)
Anderson Banihirwe (Mar 15 2022 at 21:31):Thank you, @Alice DuVivier! I am unable to run the notebook because It appears that files under /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/ are not publicly readable
$ ls -ltrh /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/
ls: cannot access /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/: Permission denied
I just changed the permissions. Sorry about that. I thought they were changed before, but I guess not.
Anderson Banihirwe said:
Thank you, Alice DuVivier! I am unable to run the notebook because It appears that files under
/glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/are not publicly readable$ ls -ltrh /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/ ls: cannot access /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/: Permission denied
Anderson Banihirwe (Mar 15 2022 at 21:43):Something may have gone wrong during the permission update.... I'm getting
ls -ltrh /glade/campaign/cesm/development/pcwg/duvivier/
ls: cannot access /glade/campaign/cesm/development/pcwg/duvivier/mosaic: Permission denied
ls: cannot access /glade/campaign/cesm/development/pcwg/duvivier/VarRes_Greenland: Permission denied
ls: cannot access /glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones: Permission denied
total 0
d????????? ? ? ? ? ? VarRes_Greenland
d????????? ? ? ? ? ? mosaic
d????????? ? ? ? ? ? arctic_cyclones
@Anderson Banihirwe Hum, when I look at all the files and directories they show they're readable and executable for everyone.
Are you able to ls this file:
|/glade/campaign/cesm/development/pcwg/duvivier/arctic_cyclones/b.e21.BSSP370.f09_g17.rufmod.001/atm/proc/tseries/month_1/b.e21.BSSP370.f09_g17.rufmod.001.cam.h0.U.201501-206412.nc
Anderson Banihirwe (Mar 15 2022 at 22:02):It's working now
Anderson Banihirwe (Mar 15 2022 at 22:14):@Alice DuVivier, I was able to run the notebook successfully up to the cell marked STOP. I don't know why you are getting the distributed.scheduler - ERROR - Workers don't have promised key errors... When you get a chance, can you post here the output of dask.config.get('jobqueue.pbs.log-directory')? We may be able to find some answers in the dask workers' logs
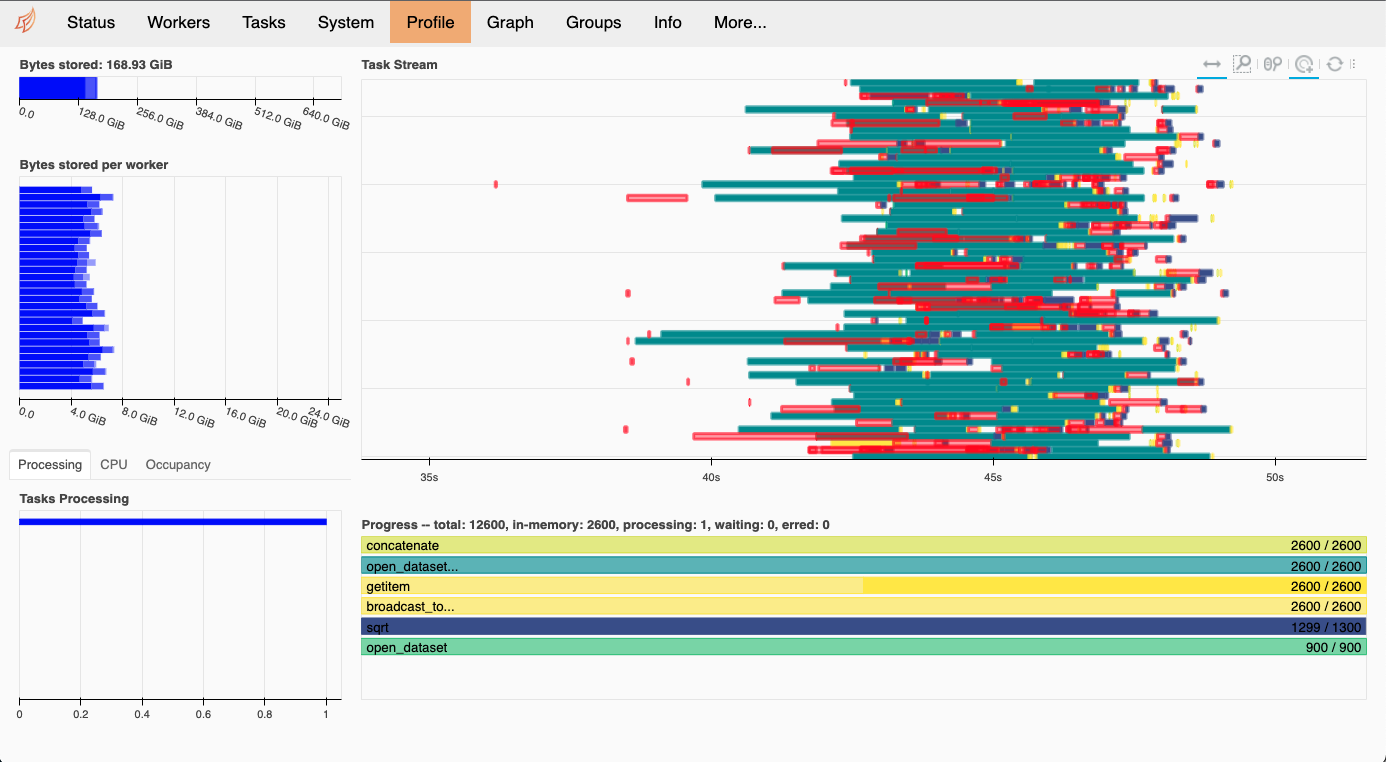
Alice DuVivier (Mar 15 2022 at 22:50):Hum... I'm on PBS Casper with 20GB memory. When I look at the DASK dashboard it just shows that all processes are complete except one for the sqrt (blue) status bar at the bottom and it just hangs there for a long time. Screen-Shot-2022-03-15-at-4.41.44-PM.png
Then the error that comes up in my notebook now is the following.
CommClosedError: in <TCP (closed) ConnectionPool.gather local=tcp://10.12.206.51:45898 remote=tcp://10.12.206.51:35757>: ConnectionResetError: [Errno 104] Connection reset by peer
I've been trying various things here and earlier I had a longer message that had the following types of examples:
distributed.scheduler - ERROR - Couldn't gather keys {"('getitem-70c66b0a352ae06959a0335384d383c8', 24, 2, 0, 0, 0)": ['tcp://10.12.206.59:41792'], "('getitem-70c66b0a352ae06959a0335384d383c8', 32, 5, 0, 0, 0)": ['tcp://10.12.206.59:45689'], "('getitem-70c66b0a352ae06959a0335384d383c8', 26, 7, 0, 0, 0)":
NoneType: None
distributed.scheduler - ERROR - Workers don't have promised key: ['tcp://10.12.206.59:41792'], ('getitem-70c66b0a352ae06959a0335384d383c8', 24, 2, 0, 0, 0)
Killed Worker...
Alice DuVivier (Mar 15 2022 at 22:52):I'm not sure I know how to get the info from the dask.config.get('jobqueue.pbs.log-directory') command.
Alice DuVivier (Mar 15 2022 at 23:06):Follow up. I poked more through the dask tabs and maybe the workers weren't all killed now that I reduced the chunksize? The error before that reduction was the 'Killed Worker' one. That being said, I'm not sure what the CommClosedError message is about and if it's a show stopper.
Anderson Banihirwe (Mar 15 2022 at 23:09):Alice DuVivier said:
I'm not sure I know how to get the info from the
dask.config.get('jobqueue.pbs.log-directory')command.
import dask
print(dask.config.get('jobqueue.pbs.log-directory'))
should tell us where on /glade Dask is persisting worker logs...
Alice DuVivier (Mar 15 2022 at 23:13):Got it! Thanks.
/glade/scratch/duvivier/dask/casper-dav/logs
Anderson Banihirwe (Mar 15 2022 at 23:14):Thanks...
Alice DuVivier (Mar 15 2022 at 23:14):I'm sorry this is such a PITA
Anderson Banihirwe (Mar 15 2022 at 23:16):No problem at all... When was your latest attempt/run? It appears that some of your workers are being killed by PBS
Here's one:
$ cat /glade/scratch/duvivier/dask/casper-dav/logs/2290461.casper-pbs.ER
distributed.worker - INFO - Waiting to connect to: tcp://10.12.206.18:33959
=>> PBS: job killed: walltime 14401 exceeded limit 14400
distributed.dask_worker - INFO - Exiting on signal 15
distributed.nanny - INFO - Closing Nanny at 'tcp://10.12.206.32:42650'
/glade/work/duvivier/miniconda3/envs/analysis2/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
distributed.nanny - INFO - Worker process 162031 was killed by signal 15
distributed.dask_worker - INFO - End worker
This may (partially) explain the CommClosedError
Alice DuVivier (Mar 15 2022 at 23:18):I just tried within the last 30 min. That's when those last error logs will be from. And I think my latest PBS session request would end around 6:30. So I don't think it should be shutting down yet.
Alice DuVivier (Mar 15 2022 at 23:18):I wonder if I should just start a new session or something? And maybe more memory? Does that seem like a reasonable first step?
Anderson Banihirwe (Mar 15 2022 at 23:26):Alice DuVivier said:
I wonder if I should just start a new session or something? And maybe more memory? Does that seem like a reasonable first step?
That might help... I should point I used the following configuration when I last ran the notebook successfully
processes = 8
cores = 16
memory = '100GB'
cluster = PBSCluster(cores=cores, processes=processes,
resource_spec=f'select=1:ncpus={processes}:mem={memory}',
walltime='01:00:00', interface='ib0')
cluster.scale(jobs=4)
Also, in this cell, did you mean to assign member_id to coords?
# set member_id values
futures_1.member_id.values
futures_2.member_id.values
# assign member_id as coordinate array
futures_1.assign_coords({"member_id": futures_1.member_id.values})
futures_2.assign_coords({"member_id": futures_2.member_id.values})
if so, the last two lines should be
# assign member_id as coordinate array
futures_1 = futures_1.assign_coords({"member_id": futures_1.member_id.values})
futures_2 = futures_2.assign_coords({"member_id": futures_2.member_id.values})
Otherwise, the .assign_coords() won't do what you what since it doesn't happen inplace
Alice DuVivier (Mar 15 2022 at 23:29):I will try those options. I have to do kid-care things, but I'll follow up later tonight or early tomorrow. thanks so much!! :)
Anderson Banihirwe (Mar 15 2022 at 23:30):You're welcome!... Keep me posted
Deepak Cherian (Mar 16 2022 at 03:44):Anderson Banihirwe said:
Alice DuVivier said:
I'm not sure I know how to get the info from the
dask.config.get('jobqueue.pbs.log-directory')command.import dask print(dask.config.get('jobqueue.pbs.log-directory'))should tell us where on
/gladeDask is persisting worker logs...
This would be useful to put in the FAQ
Alice DuVivier (Mar 16 2022 at 15:49):@Anderson Banihirwe It looks like it worked today with the configuration you suggested. Hooray! It took a long time (35min according to the time output), but it didn't die and I think I'm going to call that a win for now. Thanks!
Anderson Banihirwe (Mar 16 2022 at 16:37):Glad to hear it!
Alice DuVivier said:
Hum... I'm on PBS Casper with 20GB memory. When I look at the DASK dashboard it just shows that all processes are complete except one for the sqrt (blue) status bar at the bottom and it just hangs there for a long time. Screen-Shot-2022-03-15-at-4.41.44-PM.png
It's still unclear to me why Dask was getting stuck at that one sqrt task
Anderson Banihirwe (Mar 16 2022 at 16:38):Hooray! It took a long time (35min according to the time output)
Not sure if this has to do with your cluster size. Were all your workers available or did you have some jobs pending in the queue?
Alice DuVivier (Mar 17 2022 at 13:13):@Anderson Banihirwe things were running really slowly after this step with the vertical interpolation yesterday. I didn't finish up that analysis and code and I'm going to be out of the office for a few days. But I'll check back in when I'm back!
Notification Bot (Mar 17 2022 at 13:23):This topic was moved here from #ESDS > Dask: KilledWorker Error by Anderson Banihirwe
Last updated: May 16 2025 at 17:14 UTC