Alice DuVivier (Aug 16 2021 at 18:41): Alice DuVivier (Aug 16 2021 at 18:41):
Alice DuVivier (Aug 16 2021 at 18:41): Alice DuVivier (Aug 16 2021 at 18:41):I've been trying to follow Max's write up on importing the CESM2-LE using intake (see here: https://ncar.github.io/esds/posts/intake-cesm2-le-glade-example/). I am getting an error with open_esm_datastore. I don't know if this is related to somehow not loading "intake" properly at the start of the notebook, but I did not get an error there. The error I'm getting is:
KeyError Traceback (most recent call last)
/glade/work/duvivier/miniconda3/envs/antarctica_som_env/lib/python3.7/site-packages/intake/__init__.py in __getattr__(attr)
60 try:
---> 61 return gl[attr]
62 except KeyError:
KeyError: 'open_esm_datastore'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
<ipython-input-6-deb999ed649e> in <module>
----> 1 cat = intake.open_esm_datastore('/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json')
/glade/work/duvivier/miniconda3/envs/antarctica_som_env/lib/python3.7/site-packages/intake/__init__.py in __getattr__(attr)
61 return gl[attr]
62 except KeyError:
---> 63 raise AttributeError(attr)
64
65
AttributeError: open_esm_datastore
Any advice? Hopefully this is just something about setting up my environment?
Max Grover (Aug 16 2021 at 18:45):Did you install intake-esm using the following?
conda install -c conda-forge intake-esm
Max Grover said:
Did you install intake-esm using the following?
conda install -c conda-forge intake-esm
I'm giving that a try now. It seems to have worked. I'm sure more questions will come up before official office hours. Thanks for helping me get on my way now though. :)
Alice DuVivier (Aug 16 2021 at 21:27):Here is my environment path:
antarctica_som_env * /glade/work/duvivier/miniconda3/envs/antarctica_som_env
Here is the error:
AttributeError Traceback (most recent call last)
<ipython-input-7-7054c1bae29b> in <module>
----> 1 cat.search(variable='aice')
/glade/work/duvivier/miniconda3/envs/antarctica_som_env/lib/python3.7/site-packages/intake_esm/core.py in search(self, require_all_on, **query)
644 """
645
--> 646 results = search(self.df, require_all_on=require_all_on, **query)
647 ret = esm_datastore.from_df(
648 results,
/glade/work/duvivier/miniconda3/envs/antarctica_som_env/lib/python3.7/site-packages/intake_esm/search.py in search(df, require_all_on, **query)
50 condition_i = np.zeros(len(df), dtype=bool)
51 column_is_stringtype = isinstance(
---> 52 df[key].dtype, (np.object, pd.core.arrays.string_.StringDtype)
53 )
54 for val_i in val:
AttributeError: module 'pandas.core.arrays' has no attribute 'string_'
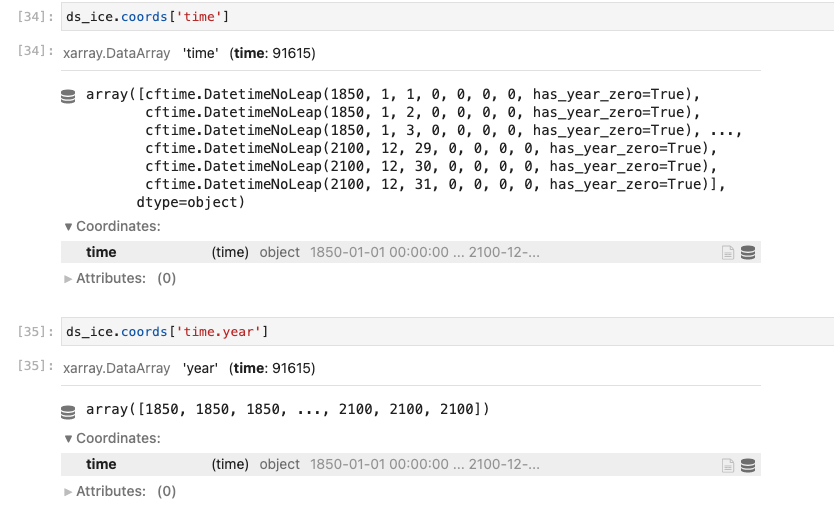
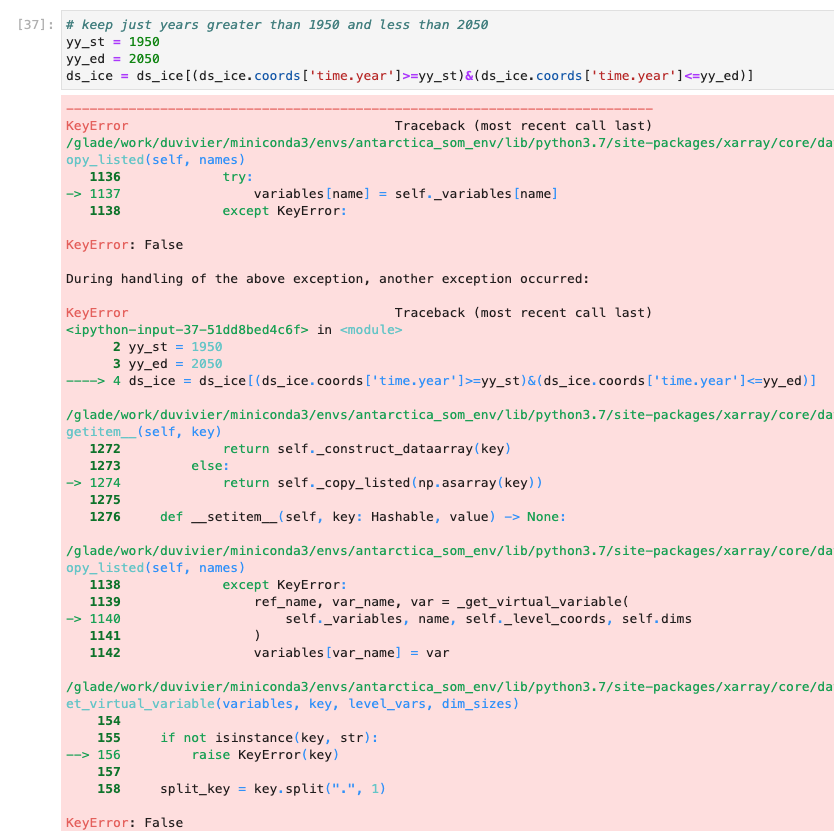
Alice DuVivier (Aug 24 2021 at 19:44):I have been able to load the CESM2-LE data, but am running into a hitch when it comes to subsetting the data by year. I've followed the blog post to load the data (historical and future) but when I try to subset the dataset by a limited range of years I get the following errors. I'd done this method of subsetting before on a single ensemble member, so I'm not sure why it's failing now.
Screen-Shot-2021-08-24-at-1.43.21-PM.png
Screen-Shot-2021-08-24-at-1.43.31-PM.png
Deepak Cherian (Aug 24 2021 at 19:48):Try ds_ice.sel(time=slice("1950", "2050")) [see https://xarray.pydata.org/en/stable/user-guide/time-series.html#datetime-indexing]
Alice DuVivier (Aug 24 2021 at 21:32):Thanks, Deepak! That was great for years. Max and I worked further on subsetting months too since it wasn't quite so simple, but it looks like I got that working too.
Alice DuVivier (Sep 10 2021 at 19:04):@Max Grover I have been trying to use the intake-esm function with some atmospheric data from the CESM2-LE. I was able to load the data successfully, but it looks like not all the data are consistent. When I try to concatenate all the historical or future members I get an error because not all the members have the same variables. Here's the error:
ValueError: 'zlon_bnds' is not present in all datasets.
I've tried a number of options with xr.concat to ignore the variable that's not in all of the ensembles, but I haven't been able to figure out a way to ignore that when concatenating. Any thoughts? Also, is this inconsistency in different members something to be concerned about?
Thanks!!
Notebook location:
/glade/p/cgd/ppc/duvivier/cesm2_arctic_cyclones/DATA/regional_timeseries/cesm2_le_regional_atmospheric_avgs.ipynb
Max Grover (Sep 10 2021 at 19:26):Using the following settings seemed to have worked (and removed the errors saying there are very large chunks)
with dask.config.set(**{'array.slicing.split_large_chunks': False}):
historical_ds = xr.concat(historicals, dim='member_id', data_vars="minimal", coords="minimal", compat="override")
future_ds = xr.concat(futures, dim='member_id', data_vars="minimal", coords="minimal", compat="override")
I used some of the suggestions from this part of the ESDS FAQ page:
https://ncar.github.io/esds/faq/#xarray-and-dask
Hope this helps!
Alice DuVivier (Sep 10 2021 at 19:41):It worked! Thanks! :)
Max Grover said:
Using the following settings seemed to have worked (and removed the errors saying there are very large chunks)
with dask.config.set(**{'array.slicing.split_large_chunks': False}): historical_ds = xr.concat(historicals, dim='member_id', data_vars="minimal", coords="minimal", compat="override") future_ds = xr.concat(futures, dim='member_id', data_vars="minimal", coords="minimal", compat="override")I used some of the suggestions from this part of the ESDS FAQ page:
https://ncar.github.io/esds/faq/#xarray-and-dask
Hope this helps!
Yakelyn R. Jauregui (Oct 12 2021 at 20:06):Hello @Max Grover , I wonder the 3-hourly data, especially precip (precc + precl) and TS can be added to this catalog (/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json) . I only found cam.h0, cam.h1, and cam.h2, but I know the 3-hourly data is available here: /glade/campaign/cgd/cesm/CESM2-LE/timeseries/atm/proc/tseries/hour_3/ . Thanks, I appreciate any help.
Max Grover (Oct 12 2021 at 20:07):Sure - I can add that to the catalog!
Max Grover (Oct 12 2021 at 23:09):It should be updated by tomorrow! I rebuilt it today!
Max Grover (Oct 15 2021 at 20:43):The catalog has been updated!! You can use the path /glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json
Stephen Yeager (Dec 01 2021 at 20:01):I'm finding that the cesm2-le catalog has gaps. This is dangerous because such gaps are silently filled when aggregating using intake-esm, resulting in analysis errors that are not obvious. For example:
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json'
col = intake.open_esm_datastore(catalog_file)
data = col.search(component='ocn', variable=['SHF'], frequency='month_1', experiment=['historical','ssp370'])
dsets = data.to_dataset_dict()
returns a dataset dictionary that is missing many 10-year chunks, even though the corresponding datafiles exist on glade. A few examples are (cesm_member_id:time_range):
1231.002:186001-186912
1231.004:186001-186912
1011.001:201501-210012
The catalog needs to be updated and quality-checked to avoid such gaps.
Max Grover (Dec 01 2021 at 20:08):There was a problem with some of that data originally - here is the note from Gary in late September.
"There are some decades from some runs that aren't yet at NCAR due to a problem on the IBS side:
1850-1859 b.e21.BHISTsmbb.f09_g17.LE2-1251.018
1860-1869 b.e21.BHISTcmip6.f09_g17.LE2-1231.002
b.e21.BHISTcmip6.f09_g17.LE2-1231.004
b.e21.BHISTcmip6.f09_g17.LE2-1231.005
b.e21.BHISTcmip6.f09_g17.LE2-1231.006
b.e21.BHISTcmip6.f09_g17.LE2-1231.007
1890-1899 b.e21.BHISTsmbb.f09_g17.LE2-1251.017
1900-1909 b.e21.BHISTsmbb.f09_g17.LE2-1231.020
b.e21.BHISTsmbb.f09_g17.LE2-1251.011
b.e21.BHISTsmbb.f09_g17.LE2-1251.012
b.e21.BHISTsmbb.f09_g17.LE2-1251.016
b.e21.BHISTsmbb.f09_g17.LE2-1251.013
1910-1919 b.e21.BHISTsmbb.f09_g17.LE2-1251.013
b.e21.BHISTsmbb.f09_g17.LE2-1231.019
1980-1989 b.e21.BHISTsmbb.f09_g17.LE2-1301.017
These are being filled in as the IBS folks get to them."
I have been updating it periodically, so I can go head and update it again if there are more files there.
Stephen Yeager (Dec 01 2021 at 20:15):Could you post a notification when you've updated it? Thank you!
Deepak Cherian (Dec 01 2021 at 20:31):This is dangerous because such gaps are silently filled when aggregating using intake-esm,
Can you clarify what you mean by "silently filling"? Is it adding NaNs?
Stephen Yeager (Dec 01 2021 at 20:32):Yes.
Max Grover (Dec 02 2021 at 22:32):The catalog is corrected - I tested it across those cases.
Deepak Cherian (Dec 02 2021 at 23:25):Steve, are you concatenating those datasets later? is that when the filling occurs?
Stephen Yeager (Dec 03 2021 at 14:44):@Deepak Cherian Yes, I am concatenating 'historical' with 'ssp370', but that's not the problem. The problem is that there is an aggregation over 'member_id', but some members are missing time blocks (at least, they were in the old catalog). So loading a multimember dataset results in gaps filled with Nan for some members.
Alice DuVivier (Dec 13 2021 at 23:14):This may be related to @Stephen Yeager 's question, but I'm getting a failure using the CESM2-LE catalog and I think it's related to missing files from the 1860's and possibly a name update.
The piece of code I'm running is here:
%%time
#load the data we selected into a dataset
with dask.config.set(**{'array.slicing.split_large_chunks': True}):
dsets = subset.to_dataset_dict(cdf_kwargs={'chunks': {'time':240}, 'decode_times': True})
Here's the error:
OSError:
Failed to open netCDF/HDF dataset.
*** Arguments passed to xarray.open_dataset() ***:
- filename_or_obj: /glade/campaign/cgd/cesm/CESM2-LE/timeseries/ice/proc/tseries/day_1/aice_d/b.e21.BHISTcmip6.f09_g17.LE2-1231.007.cice.h1.aice_d.18600101-18691231.nc
- kwargs: {'chunks': {'time': 240}, 'decode_times': True}
*** fsspec options used ***:
- root: /glade/campaign/cgd/cesm/CESM2-LE/timeseries/ice/proc/tseries/day_1/aice_d/b.e21.BHISTcmip6.f09_g17.LE2-1231.007.cice.h1.aice_d.18600101-18691231.nc
- protocol: None
********************************************
This looks like it's not finding the file for 1860-1869. However, when I look in the directory, it looks like the following file is present, but maybe has been renamed?
/glade/campaign/cgd/cesm/CESM2-LE/timeseries/ice/proc/tseries/day_1/aice_d/b.e21.BHISTcmip6.f09_g17.LE2-1231.007.cice.h1.aice_d.18600102-18700101.nc
Honestly, I'm not totally clear what's happened because I've used this piece of code in the past without problems and the only thing I can think has changed is the addition of the new 1860's files.
Max Grover (Dec 16 2021 at 16:50):@Alice DuVivier @Stephen Yeager - the CESM2-LE GLADE catalog has been updated, with fixes for both of the gaps/bugs that you mentioned.
Alice DuVivier (Dec 16 2021 at 16:53):Thanks @Max Grover
Stephen Yeager (Jan 11 2022 at 20:01):I'm encountering another issue with intake and cesm2-le. The following collection returns a dataframe with time out of order:
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json'
col = intake.open_esm_datastore(catalog_file)
cesm2data = col.search(component='ocn',
variable=['IFRAC'],
frequency='month_1',
experiment=['historical','ssp370'],
forcing_variant='smbb')
When I look at ssp370 files using
cesm2data.df[cesm2data.df.experiment == 'ssp370']
it appears to return a list that looks complete, but cesm2data.to_dataset_dict() does not aggregate properly across timestamps (because the dataframe file list is out of order?). Similar error for the 'historical' data.
Anderson Banihirwe (Jan 11 2022 at 20:15):I believe this is related to this issue https://github.com/intake/intake-esm/issues/343 and it should/will be fixed in the upcoming version of intake-esm. A temporary workaround is to sort the dataframe yourself before loading the data:
cesm2data.df = cesm2data.df.sort_values(by=['time_range'])
or just sort the entire catalog after reading it in
col.df = col.df.sort_values(by=['time_range'])
I'm encountering a new issue in a notebook that used to work to process CESM2-LE using intake (v0.6.3). The following collection query:
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json'
col = intake.open_esm_datastore(catalog_file)
oceandata = col.search(component='ocn',
variable=['TEMP'],
frequency='month_1',
experiment=['historical','ssp370'])
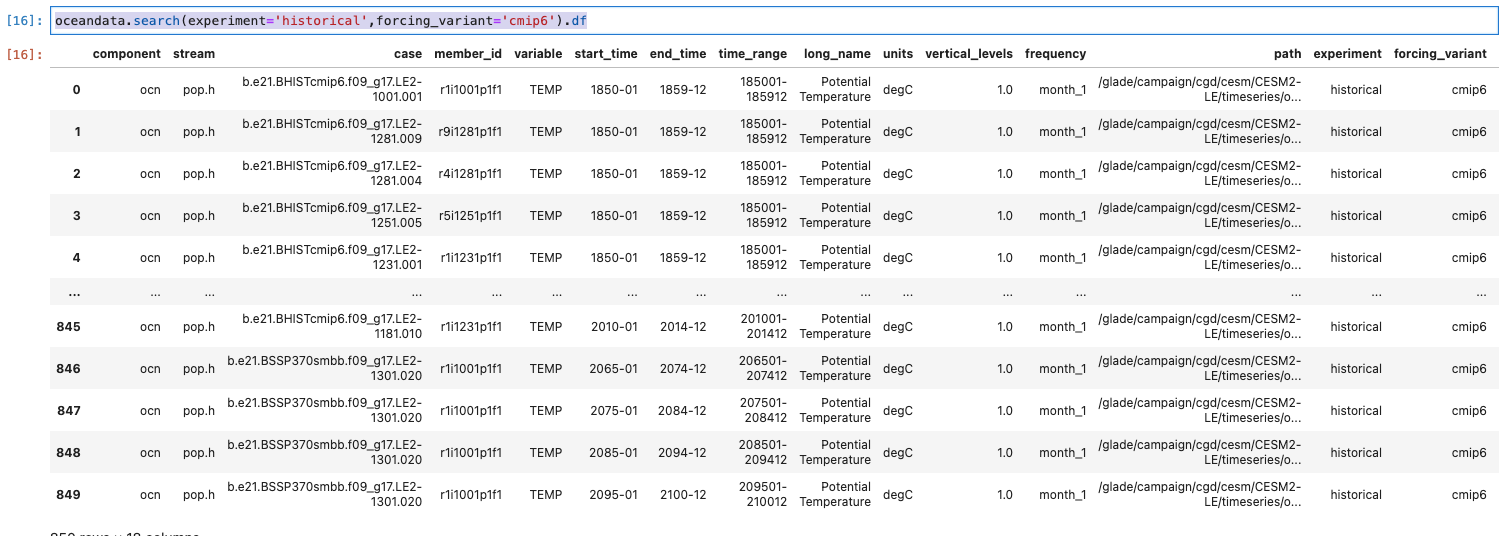
returns incorrect 'experiment' entries. Attached is a snapshot of the output from
oceandata.search(experiment='historical',forcing_variant='cmip6').df
Note that some 'BSSP370' cases are labelled as 'historical'. Similarly, some 'BHIST' cases are labelled as 'ssp370'. These errors mess up the aggregation into a dataset dictionary. Screen-Shot-2022-01-14-at-3.46.45-PM.png
Anderson Banihirwe (Jan 15 2022 at 00:51):I believe this is a bug in the scripts used to build the catalog... Cc @Max Grover, could you please look into this when you have time?
Max Grover (Jan 18 2022 at 21:52):taking a look at this this afternoon
Max Grover (Jan 19 2022 at 17:55):Currently submitting a PR to intake-esm-datastore... should be good to go later today!
Alice DuVivier (Jul 17 2023 at 19:36):Hi all,
I am working with a visiting graduate student on loading in some of the CESM2-LE using the intake functions with the CESM2-LE catalog. We've used the following commands and can see the files listed in the subset list we create, but then we are getting an error when it tries to actually read the dataset with dask. I think the error is related to maybe missing files?
catalog_file = '/glade/collections/cmip/catalog/intake-esm-datastore/catalogs/glade-cesm2-le.json'
cat = intake.open_esm_datastore(catalog_file)
var_in = 'PSL'
forcing = 'smbb'
freq = 'hour_6'
subset = cat.search(variable=var_in, forcing_variant=forcing, frequency=freq)
#actually load the data we selected into a dataset
with dask.config.set(**{'array.slicing.split_large_chunks': True}):
dsets = subset.to_dataset_dict(cdf_kwargs={'chunks': {'time':240}, 'decode_times': True})
The error it returns at this step is:
"FileNotFoundError"
(lots of other messages)
"ESMDataSourceError: Failed to load dataset with key='atm.ssp370.cam.h2.cmip6.PSL'
You can use cat['atm.ssp370.camp.h2.smbb.PSL].df` to inspect the assets/files for this key.
When I use the cat command it shows me the list of the files that are ready to be read in, but they look fine to me. So... I'm not sure how to check which are missing and would appreciate some guidance.
Deepak Cherian (Jul 18 2023 at 02:16):The files as listed in the catalog don't exist. They have been renamed:
df = cat['atm.historical.cam.h2.smbb.PSL'].df
import os
missing = [path for path in df["path"] if not os.path.exists(path)]
print(f"{len(missing)} / {len(df)} are missing!")
The catalog has b.e21.BHISTsmbb.f09_g17.LE2-1011.001.cam.h2.PSL.1850010100-1860010100.nc for example but the actual file is b.e21.BHISTsmbb.f09_g17.LE2-1011.001.cam.h2.PSL.1850010100-1859123100.nc
Alice DuVivier (Jul 18 2023 at 02:41):Ah, okay, thanks. So... do I need to generate a new catalog? Or... how is this done? I believe in the past someone in ESDS (Max?) had generated the catalogs referenced by intake so I'm not familiar with that process. I did see this documentation:
https://ncar.github.io/esds/posts/2021/ecgtools-history-files-example/?highlight=catalog
But I'm not sure that's going to work here given I've been referencing a communal catalog.
Alice DuVivier (Jul 18 2023 at 14:58):@Deepak Cherian thanks for looking into this and checking how to keep these updated regularly. :)
Deepak Cherian (Jul 20 2023 at 23:01):@Alice DuVivier You can try "/glade/scratch/dcherian/intake-esm-datastore/catalogs/glade-cesm2-le.json". I edited the paths manually.
THere's still something wrong with cat["atm.ssp370.cam.h2.smbb.PSL"] though. One file may be bad but hard to figure out which
Last updated: May 16 2025 at 17:14 UTC