Intent
This document was created in September 2018 in an attempt to flesh out design criteria and options for a shared definition for capturing all raw sampled data. This was implemented in October and the core data format was quickly integrated into the codebase. This remains mostly as historical element of what choice was made and why.
Preface
As ACS is reaching a more stable and useable state, I have been pondering the total lifecycle of how one would interacts with AVAPS from sonde to Model ingest, how best to handle data flow. Basically, what should our end data pipelines be? We have a diverse set of end users, and some of those end users are not really showing up at the end of the data pipe line, but really close to the beginning. Diagrams are helpful for explaining stuff - my thoughts have been to do something like the following:

This is roughly what we have been using (replace AVAPS ACS with AVAPS Drop), but I want to formalize how this should work and produce contracts as the interface between ACS and ASPEN. Right now these interfaces are defacto standards, but I would like to make stronger promises so that we can be clearer on what each process does, its primary concerns, its affects on the data, and behaviors each should engaged it. Essentially I want to establish clear boundaries to allow for separation of concern, if not for external users, but for ourselves.
The Pipeline
We often refer to data indiscriminately, and although we attempt to use words such as “raw” and “qc’d” data, that really isn’t ever precise enough. This gets usually gets messy, often requiring someone making (multiple) diagrams of the data, the state of the data, and lots of arbitrary documents to describe the process. Although I don’t see an end to this, but what I would like to do is formalize the AVAPS data pipeline: the process of handling, moving, altering and working with dataflow.
Proposal
I woud like to propose we start using the following data flow for AVAPS Data.
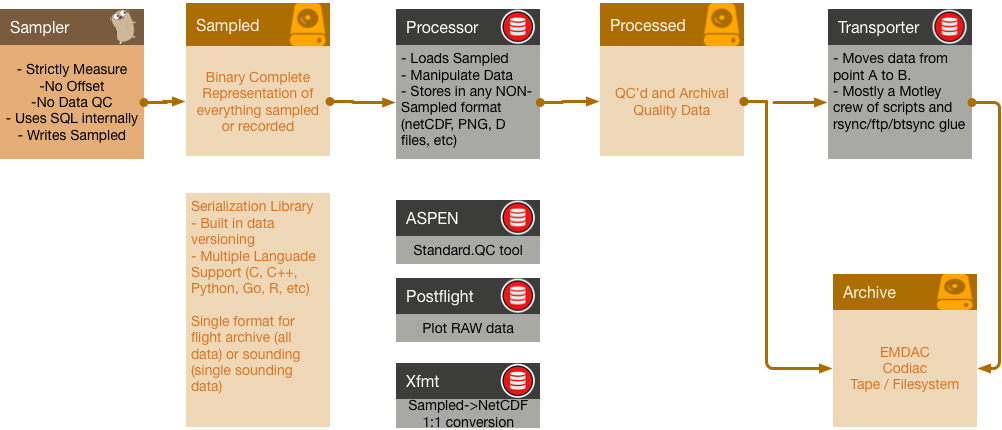
I want to step through each of the catagories of Sampler, Sampled, Processor, and Processed in a bit of detail to explain what I mean by the concepts. The last item (Archive) is an archive facility that ISF has no control over, other than to use, and will not be discussed here.
Sampler
A Sampler is something that does the work of gathering raw instrument data (with metadata) from AVAPS hardware (sonde, chassis, launcher, etc) at the time of sampling. Its main concern is assuring the best set of collected data that is possible, including the interaction with operators to assure working insturments. A Sampler works with the operator to record data from sondes In terms of AVAPS equipment, the following software packages are samplers:
- AVAPS Drop
- ACS
- AGS
You may rightly question why AGS is included in this list, but because it, at the time of operation, gathers information from the operator, it too is a Sampler.
A Sampler writes out Sampled data structures where needed as either files, network streams, or other.
Sampled
Sampled is a file format that is capable of being modified over time without breaking tools, that contains every sampled bit from the system. This includes log messages, metadata, raw sounding data, and any other sort of potentially useful bit of information. A Sampled file need to have the following properties:
- Never Modified:
- Strictly Written Once
- Read many times by interested parties
- Same structure for All soundings, or a single sounding
- Contains ALL the data temporally coincident with a sounding, or all data from a flight, or project,
- Structure must be able to handle changes over time:
- Using an old tool with new data should not cause tool breakage, perhaps loss of fidelity
- New Tools should be able to read old data formats
- Format must be able to readable my multiple software packages to allow for as much reuse as possible.
Initial thoughts on how to fulfil these requirements has me thinking of using a serialization library to describe all the recorded data. There already exists tooling for code generation as well as benefits of multiple language software packages. Additionally, the format is declarative, and can be easily published.
A Sampled should most be archived.
Processor
A Processor reads a Sampled structure, does something with the data, and may save data out as any format except a Sampled. Examples of a Processor are:
- Aspen / BatchAspen
- Postflight Plot Evaluation Generation
- Report Objects that generate text reports based on the data
Processed
Processed is any sort of output data from a Processor, be it a netCDF, Alphabet soup, PNG plots, KML tracks, EOL outputs, or any other sort of processed data. These most likely should be archived, or may be fed to transports
Transporter
A Transporter takes the Sampled’s or Processed data and move them point A to B by whatever means necessary to fulfull data requirements on a per-project basis. These are usually real-time processes that moved output, ala rsync, lftp, btsync or whatnot.
Sampled Format
I am a bit conflicted on what to do here, and I am open to suggestions, critiques, and other ideas. The primary idea is I want to move towards a single, published, backwards compatable standard that allows for us to obsolete fields, add additional ones, and be as self-descriptive as possible for historical reasons. Code generators are also a huge plus. With that said, here are some general ideas:
Compressed text/CSV/JSON/YAML/TOML
Entirely possible. A great case of using a screwdriver as a crowbar.
Pros
- Extremely easy to document, or alter
- Some code generation available
Cons
- WAY to easily edited.
- Do you really want to parse 10s of MB of a file where a single missing comma kills the data?
- Alphabet soup is bad because it is a custom text format. We want to move away from custom text formats entirely.
netCDF
Use a single netCDF container for all the data.
Pros
- Well known / understood format
- Single File
- Capable of holding all the data
- Archive container
Cons
- Well known format that people can edit with some ease
- Does not have great support for any language outside C/C++, or Java, and some basic bindings in Python and R.
- Does not handle
[]byteslices elegantly.NC_STRINGwas only added in v4, and even then, I don’t want to store a string, but a set of raw unprocessed data. - Is unable, outside lots of custom boiler-plate, to handle changing data formats over time. Reading an old netCDF files with new code requires all sorts of sanity checks in order to not crash/panic/work.
- Is MUCH harder to work with at an API level: are we still directly worried about handling ‘unlimited’ dimensions?
- We have to know how many data points we are going to write before we write then.
- No code generation. 100% hand written code
SQLite3
Use a single SQLite3 database as a container
Pros
- Really well supported in a large varaity of languages
- ACS already uses a tabular format
- Basically the same structure used within ACS
Cons
- Readily and easily editable.
- Does not have support for changing formats over time.
- Limited code generation. Lots of hand coded boilerplate.
Use a Serialization Library
Publish and use protocol buffers v3, Cap’n Proto, flatbuffers, or similar as the line encoding. The structure is codified in a file and then a specialized tool (eg, protoc for protocol buffers, capnp compile for Cap’n Proto, and flatc) file and the protoc tool is used to generate C, C++, python, Go, R, etc. There are differences between each Serialization Libraries (eg, Cap’n Proto and Flatbuffers both mmap()’s files, etc.
See this for some Golang benchmarks between serializers
Pros
- Boiler plate reduced
- One of the key things the libraries handle is format versions. Evolution is possible (and encouraged?)
- Render complex structures into
[]byte, which are easily written to disk, socket, etc - Allows NCAR to publish definitions for consumption.
- Just about every common language is supported
- Supports a large selection of OS/endienness/ordering
Cons
- Requires writing parsers and adds a library depency
- A ‘new’ format to manage, but the positive is that there are tools to handle the low level bytes and bits.
Overall views:
- Not interested in maintaining another text format.
- I am not excited about using netCDF because of its downsides
- SQLite3 isn’t much better than netCDF. Too many ways to easily edit
- Im leaning heavily towards a serialization library, but which one is still up for debate.
End Goal
If this is the proposal followed through, then the work on ACS daemon can come to a conclusion much sooner than later, and work on Aspen and work on other support utilities can begin much sooner. This also means that outside of UI tweaking, the ACS project would mostly be wrapped up, and the QC project begin with a clear goal.
Data Volume
I do not have an exact number for the size of the volume generated by AVAPS. It isn’t RADAR data, but it also isn’t extremely compact. As a source of consideration of serialization protocols, we might be memory limited, especially for very large or long flight conversions - this might place huge memory restrictions on what is possible, or available. A quick estimation:
KB per Min = 55 + N*50, for N channels
| Source | kB/sec generated | Formula |
|---|---|---|
| Sonde | 46k/min | 120 frames/min * ( 120 bytes + 50 double sized (8 byte) parameters) |
| Channel | 3.5k/min | ~1sps @ 5 double sized parameters + 20 bytes payload |
| Chassis Health | ~2.5k/min | ~1sps @ 3 double sized parameters + 20 byte payload |
| Speca | 30k/min | 10 samples @ 301 power msmt at 8 bytes/sample + 606 bytes raw message |
| Lancher State | 23.4k/min | ~1sps @ 35 double sized parameters + 120byte payload |
| GPS | ?? | I don’t have a good sense for the rate. A wild guess is 240-500bytes/sec |
| IWGADTS | ?? | 1sps, of ~30 items |
Typical Sounding
A typical soundings lasts from 20 to 40 minutes, sometimes a lot more. Using 40 as a nominal upper limit, a sounding, in rough estimates, takes up ~4-5MB on disk
40min * 55kb/min + 40 mins * 50kb/min
Typical flight
A typical flight lasts around 8 hours, with around 25-40 (upper bound) sondes. Using the above rates, a typical flights data is something like 84M
8 hours * 60 mins/hour * 55kb/min + 40 mins * 30 soundings * 50kb/min
Whole Project Archive
This gets even more loose, but suppose 20 flights (which is on the high end), and ~650 sondes gets us in the 1785MB range for data.
20 flight * 8 hours/flight * 60 mins/hour * 55k/min + 40 mins * 650 soundings * 50kb/min
Comparison of Serialization Libraries
As for serialization libraries, I am inclined to go with one that has been around for a while, and will be supported for a while longer. This rules out lots of smaller highly custom format. Feel free to add more concepts here. Items are ranked in order of most preferential to least interested.
- PBv3
- Pros
- Superb documentation
- Google uses PB internally everywhere, so its not going away anytime soon
- Of note, Golang’s
gobis based off PB, but is a little faster. - Fundamental core of
grpc- will come in handy for QC-cloud concepts. - Large list of well documented APIs for common languages
- Cons
- Not ideal for large data blocks. Reads and parses on the fly - so there is some overhead associated with huge (>10MB) files. This might require some testing to see how much of a problem this is. link.
- PBv3 does not ‘keep’ unknown parameters during a unpack->pack operation. PBv2 used to, but this was removed. I’m not sure this matters for our purposes, our pattern is more 1 writer, multi readers without passthrough middleware inspectors.
- Does not use
mmap(), so it parses the file every time. This may be annoying for dealing with large data files.
- Pros
- flatbuffers github
- Pros
- Allows for
mmap()‘d files which should be faster for parsing mmap()ing makes it a bit unwieldy to edit on disk, but is possible. Creating should be straightforward.- Used in the android gaming community, and directly supported by Google
- Used by facebook
- Allows for
- Cons:
- Much smaller support team
Action is mostly in C++ since that is what we use, other languages are mostly external contributions.See this
- Pros
- Cap’n Proto
- Pro:
- Lots of languages supported
- Same developer that created Protocol Buffers v2
mmap()‘d files- Pretty good documentation
- Cons:
- Requires sequentially numbered fields. Maybe more annoying than a con.
- Not as widely used
- Output structure size is the same, even with missing fields.
- Pro:
- msgpack
- Pro:
- Lots of languages supported
- Cons:
- Doesnt like large bystrings link
- So many implementations of the spec - its not clear which implementation we should choose
- Pro:
- Thrift
- Pro:
- Multi Language
- comes with RPC backend
- Cons:
- Really java centered
- Pretty heavy import chain to get serialization. Comes with RPC server and cannot easily separate.
- Pro: