ESDS Update October 2021#
October has been an active month! There were a variety of talks, a variety of answered Python questions during office hours, and a Python tutorial!
Check out the following ESDS update for the month of October 2021.
Xdev Updates#
Xdev has made some important advances on Intake-ESM, which is a data catalog utility comprising an API to data assets. Essentially, intake-esm “abstracts away” the file system, enabling data search and discovery, automated queries and dataset construction, and portability across cloud and HPC platforms. We’re now working on a set of ideas we’re calling Funnel; this extends the data catalog with “analysis recipes”, providing an effective strategy for modularization and extensibility of workflows.
We also held our first discussion on xwrf, which is a new package meant to bring Weather Research and Forecasting (WRF) data into the Pangeo Ecosystem! Using this tool, users can read WRF output directly into Xarray, enabling the use of Dask and hvPlot. If you are interested in following along with that development, be sure to check out the xwrf repository.
ESDS Forum#
Python Package Overviews#
A Jupyter Based Diagnostics Prototype (4 October 2021) - Max Grover (CGD)
General Discussion#
An Overview of Xdev and Analysis Pain Points (18 October 2021) - Kevin Paul (CISL)
ESDS Blog Posts#
Data Computation#
End to End Workflow#
Office Hour Questions#
During the month of October 2021, our team answered a total of 14 questions at our weekly Xdev Office Hours.
Below is a summary of the most common questions brought up during office hours!
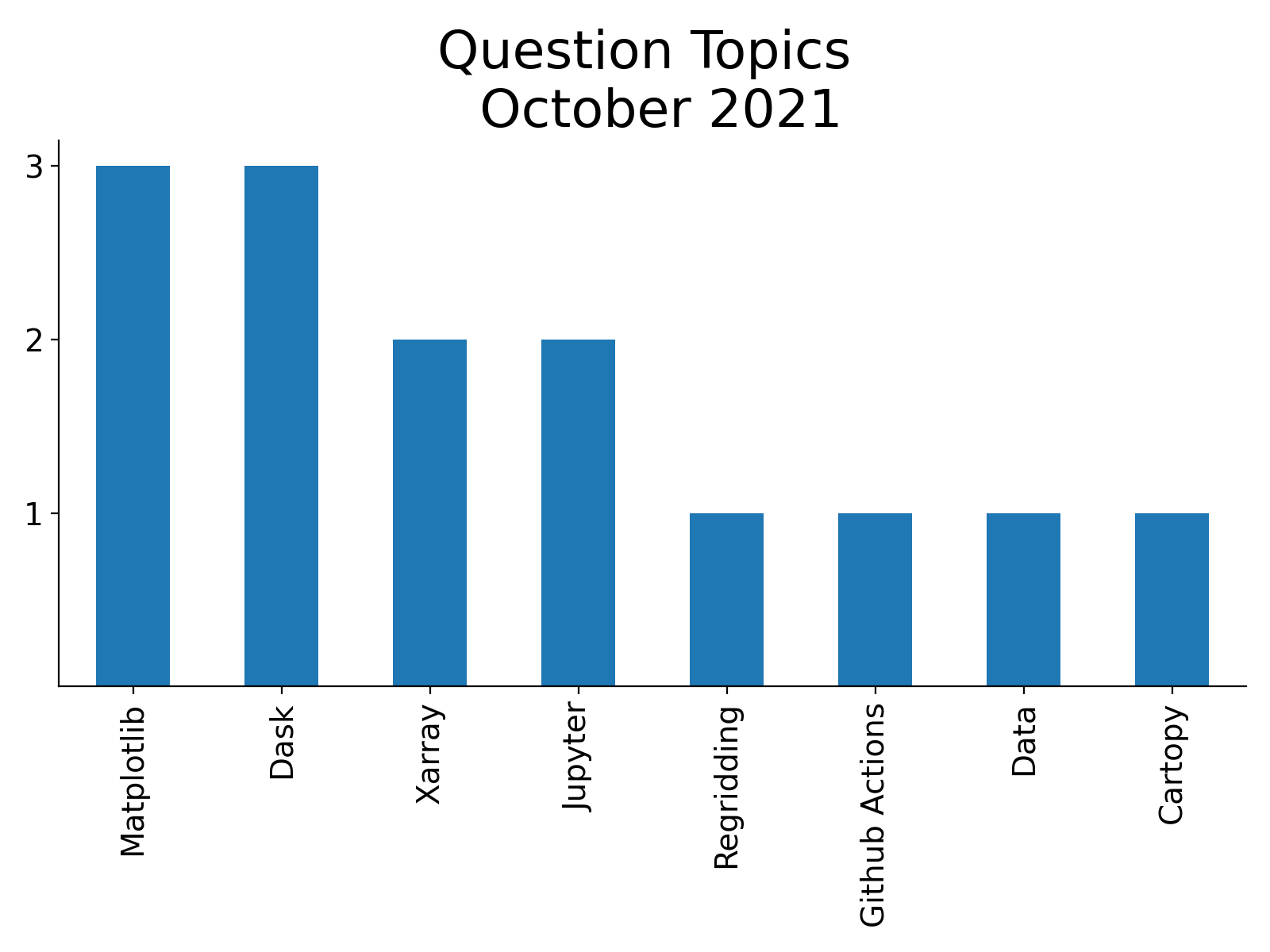
Matplotlib Questions#
How do you adjust the colorbar size, spacing?
Suggested adding to the
padargument
How to plot a basic map using matplotlib?
Suggested checking out the Cartopy Content on the Pythia Foundations Page
How do you adjust the colorbar?
Pointed to matplotlib colorbar documentation
Dask Questions#
How do you get dask to work with stacking CESM2-LE data?
Worked on an example subsetting the data, developing pipeline
How to submit jobs with different schedulers?
Suggested checking out Dask jobqueue options
What is the most efficient way to compute annual means from a bunch of Earth System Prediction (ESP) data?
For some cases, makes sense using the preprocess function when the files are big enough (ex. ESP Decadal Prediction datasets)
Good case for preprocess - calculating annual means with files ~10s of GB in size
Bad case for preprocess - working with many smaller files, which leads to a large number of tasks and a slower process
Xarray Questions#
How do you optimize file read in with ESP data?
Make sure to know when to use the preprocess function with computations
How to use one dataset to mask another with different dims?
Needed to create a loop and create new dimensions for the datasets