Max Grover (Mar 19 2021 at 20:10): Max Grover (Mar 19 2021 at 20:10):
Max Grover (Mar 19 2021 at 20:10): Max Grover (Mar 19 2021 at 20:10):@all I worked with @Anderson Banihirwe and @Michael Levy to put together an example of an interactive dashboard workflow as the first post. Looking forward to collaborating with more people throughout CGD/more generally NCAR to put relevant content together. https://ncar.github.io/esds/posts/Interactive_Dashboard/
Max Grover (Mar 26 2021 at 21:15):@all last week's discussion at the town hall has now been summarized/posted on the ESDS blog, removing names and condensing into more defined topics https://ncar.github.io/esds/posts/esds-blog/. Be sure to take a look! Also, this a reminder that we will hold a work-in-progress meeting Monday afternoon, where there will be more open discussion/small presentations.
Matt Long (Mar 30 2021 at 23:31):Idea for a post based on a conversation with @Keith Lindsay:
What is the best approach for developing new functionality in a Python package (e.g., pop-tools) in the context of developing an application of that functionality?
Kevin Paul (Mar 31 2021 at 00:30):What do you mean?
Max Grover (Mar 31 2021 at 15:17):Could you expand on this?
Michael Levy (Mar 31 2021 at 15:28):I wasn't part of the conversation yesterday, but I have had similar conversations... say I want to add a feature to pop-tools to use in the high-res analysis tools. There are several possible ways to do this, but here are just two examples:
pip install -e $LOCALDIR/pop-tools, and try to develop directly in pop-tools PRO: when my feature is ready, it's already in the right place to submit a PR to add it to pop-tools; CON: it might takes weeks or months for the full process (develop feature, go through review process, have PR merged, get new release) during which time I'm stuck using an older version of pop-tools; also, it's a lot to ask of users who aren't familiar with the development process for the tool they want to improvepop_tools_future directory and develop directly there. Then, when the feature is complete, start the review / PR / release process in a separate sandbox. PRO: once feature is available in pop-tools, it's just a change from pop_tools_future to pop_tools in your call (and maybe commenting out the import pop_tools_future line). CON: it's pretty kludgy during the development stage; if the new feature depends on other (existing) pop-tools features it might not be as easy as copying directly into the pop-tools sandbox Michael Levy (Mar 31 2021 at 15:32):But I think the main point is that python's modularity at the package level is a new paradigm for most of CGD. The idea that you could be developing an application that depends on a dozen independent (or intertwined) packages, and some of the features in your application are really improvements to those existing packages, is not something we've dealt with in the past and a blog post providing guidance would be very helpful.
Michael Levy (Mar 31 2021 at 15:33):(If that's not what @Matt Long had in mind, then it's an idea for a different post :)
Matt Long (Mar 31 2021 at 15:35):you got it
Kevin Paul (Mar 31 2021 at 15:52):Ok. Thanks, @Michael Levy, for the specification. I was thinking in much more general terms, such as the actual creation of a new package for the purpose of performing a particular scientific analysis (i.e., for a paper). If that is in any way part of the original intent of @Matt Long's post, then there are more philosophical and practical considerations that go beyond just how to contribute to an existing package.
Kevin Paul (Mar 31 2021 at 15:54):...But, @Michael Levy, the things you just wrote up would be great for a blog...but they could/should also be added to the CONTRIBUTING.md document of pop-tools, right?
Michael Levy (Mar 31 2021 at 15:57):...But, Michael Levy, the things you just wrote up would be great for a blog...but they could/should also be added to the
CONTRIBUTING.mddocument ofpop-tools, right?
I'm not sure if it belongs there or not -- from the pop-tools viewpoint, the only way a feature is added to pop-tools is via the fork / branch / PR route... but it doesn't really matter if the origin of the feature was done in situ or if it was originally a function in a notebook that eventually got copied into a branch on a fork and submitted as a PR. On the other hand, it could be useful information so potential developers know where to begin the process
Kevin Paul (Mar 31 2021 at 16:00):Yeah. That's a fair viewpoint. Perhaps you could just include a simple link to the external blog post in the CONTRIBUTING.md document. Anything that helps people get over the barrier to contributing is good.
Max Grover (Mar 31 2021 at 16:01):Maybe something similar to this https://unidata.github.io/MetPy/latest/devel/CONTRIBUTING.html#setting-up-your-development-environment
it explicitly states that at the end of that setup, you can use the functionality
Deepak Cherian (Mar 31 2021 at 16:06):I think (1) is the way to go.
takes weeks or months for the full process (develop feature, go through review process, have PR merged, get new release)
we should fix this.
Michael Levy (Mar 31 2021 at 16:21):I think (1) is the way to go.
takes weeks or months for the full process (develop feature, go through review process, have PR merged, get new release)
we should fix this.
I wasn't very clear about it, but in my experience the majority of that time is spent in the "develop feature" step so I don't think there is much we can do to help. (I'm thinking specifically of https://github.com/marbl-ecosys/HiRes-CESM-analysis/tree/master/notebooks/utils; on my to-do list for this week is to make a concrete list of features in that directory that actually belong elsewhere, and then I can give a more concrete example)
Kevin Paul (Mar 31 2021 at 16:26):Yeah. I think I agree with @Michael Levy on this. At first, I wholeheartedly agreed with you, @Deepak Cherian. This is anathema to agile developers and advocates of the continuous delivery (CD) paradigm.
However, after thinking about it a bit, I think there is a difference between the "scientist first, then developer" mode of work and the "developer first, then scientist" mode of work. With the former I think the priority is the scientific result, and with the later the priority is the published software feature. Unfortunately, the two priorities do not always align perfectly. Prioritizing the scientific result can sometimes require pushing on many simultaneous features at once, leading to a new scientific result but not "ready for release" software features. This is what I think @Michael Levy was implying. On the other hand, prioritizing the development usually means pushing on individual features one at a time (in sequence, if working alone, or in parallel, if working as a team) and continually releasing along the way, but this can lead to significant delays in achieving the scientific result while you wait for all the required pieces to be put in place.
I'm not sure there is a "fix" to this. In the early days of discussion on ESDS (before ESDS was a "thing"), @Matt Long and I talked about "scientists first" folks pushing toward the scientific result while "developers first" folks simultaneously focused on cleaning up, finishing, and releasing the proto-features that the scientists developed. But I've come to see that this approach tends to be very inefficient and doesn't work well in practice.
Deepak Cherian (Mar 31 2021 at 16:42):Thanks for clarifying @Michael Levy .
@Kevin Paul I mostly agree that there is no "fix". I think the real fix is to write modular code rather than one giant function that does everything. That leaves open the possibility of sending it upstream, as well as reusing the function in many projects. Even if you don't have time for a PR you can always put it in an issue for someone else to use / modify. See here for example haha: https://github.com/NCAR/mom6-tools/issues/25 . This function does exactly one thing and is quite useful :slight_smile:
Michael Levy (Mar 31 2021 at 16:45):I think the real fix is to write modular code rather than one giant function that does everything. That leaves open the possibility of sending it upstream, as well as reusing the function in many projects.
I agree 100%. I think the blog post that Matt requested to start this conversation would basically be focused on (a) writing modular code, and (b) moving that modular function to the proper repository when the author is happy with the results
Max Grover (Apr 02 2021 at 22:13):This week's ESDS post is focused around the topic of software citation! Be sure to check it out https://ncar.github.io/esds/posts/software-citation/
Max Grover (Apr 06 2021 at 23:24):@all Here is a post detailing how to get started using Dask with PBSCluster on Casper through the new Jupyterhub which launches tomorrow https://ncar.github.io/esds/posts/casper_pbs_dask/
Matt Long (Apr 06 2021 at 23:25):nice work @Max Grover!
Matt Long (Apr 06 2021 at 23:26):see also https://github.com/NCAR/ncar-jobqueue/issues/40
Max Grover (Apr 09 2021 at 21:55):Interested in learning how to use intake-esm with dask? Check out the newest ESDS blog post! https://ncar.github.io/esds/posts/intake_esm_dask/
Yassir Eddebbar (Apr 13 2021 at 23:17):Does anyone recommend a blog or tutorial on how to create a reproducible workflow for a project (preferably for python-based workflows in the geosciences), e.g. what files/folders (at minimum) should be included in a github repo, how to create an environment.yml file, best practices, etc...
Deepak Cherian (Apr 13 2021 at 23:20):Here's a list:
Yassir Eddebbar (Apr 13 2021 at 23:32):Here's a list:
- https://github.com/jbusecke/cookiecutter-science-project has some docs
- There may be something useful here: https://the-turing-way.netlify.app/welcome.html
This is perfect, thanks @Deepak Cherian !
Max Grover (Apr 16 2021 at 14:58):@_all Here is a post detailing how to get started using Dask with PBSCluster on Casper through the new Jupyterhub which launches tomorrow https://ncar.github.io/esds/posts/casper_pbs_dask/
Interested in how one can use ncar-jobqueue to make this process even easier? Check out this walk through of the difference between ncar-jobqueue and dask-jobqueue, and how to use this in your workflow! https://ncar.github.io/esds/posts/ncar-jobqueue-example/
Thanks @Anderson Banihirwe for the recent updates/all your work on ncar-jobqueue!
Max Grover (Apr 23 2021 at 20:57):Thanks @Stephen Yeager and @Deepak Cherian for contributing to this blog post regarding indexing data on unstructured grids using Xoak https://ncar.github.io/esds/posts/multiple_index_xarray_xoak/
Max Grover (Apr 29 2021 at 15:21):This post isn't from our blog, but it still worth checking out! The team at Coiled put together a post detailing "Distributed Data Science and Oceanography with Dask" with a focus on observational data stored in the cloud! https://coiled.io/blog/distributed-data-science-and-oceanography-with-dask-2/
Max Grover (Apr 30 2021 at 19:52):Interested in performing calculations in xarray, + dask, requiring operations within columns in a 3D field? Check out this post detailing how to use xarray.map_blocks https://ncar.github.io/esds/posts/map_blocks_example/
Yassir Eddebbar (May 04 2021 at 21:17):@Max Grover Per a conversation this morning, @Matt Long suggested adding a case/example for interpolating POP2 variables unto density surfaces using xgcm's transform function, maybe as an ESDS blog or a case for pop-tools?
Here is a simple case plotting O2 on the 26.5 density surface from an ensemble member from the CESM LE archive: https://hub.gke2.mybinder.org/user/eddebbar-zulip_notebooks-etekfion/notebooks/O2_along_Isopycnals.ipynb
Max Grover (May 10 2021 at 13:27):Interested in paired programming? Visual Studio code has some helpful tools for collaborating and remotely accessing Casper/Cheyenne - here is a post detailing this process! https://ncar.github.io/esds/posts/paired_programming_vs/
Max Grover (May 14 2021 at 20:35):Here is a detailed walkthough of debugging and finding a workaround for the issue that @Stephen Yeager brought up earlier this week while working with intake-esm https://ncar.github.io/esds/posts/intake_cmip6_debug/
Max Grover (May 28 2021 at 21:23):We put together some thoughts on discussions from the Dask Distributed Summit - here is a blog post detailing some of the key sessions, along with relevant links to the talks/slides! Also included is how we can tie this back to ESDS and NCAR as a whole.
Anderson Banihirwe (May 28 2021 at 21:26):We put together some thoughts on discussions from the Dask Distributed Summit - here is a blog post detailing some of the key sessions, along with relevant links to the talks/slides! Also included is how we can tie this back to ESDS and NCAR as a whole.
Thank you for putting together such a great summary!
Max Grover (Jun 04 2021 at 20:53):Interested in creating intake-esm catalogs from CESM history files? Check out this week's ESDS blog post! While the package has not been released yet, we hope this is helpful to those working with CESM data! https://ncar.github.io/esds/posts/ecgtools-history-files-example/
Max Grover (Jun 11 2021 at 21:50):Ever wanted to visualize items in data catalog? Check out this post detailing how to use the graphviz library and intake-esm to visualize assets within your catalog (using CESM-LE data as an example)! https://ncar.github.io/esds/posts/graphviz_example/
Max Grover (Jun 18 2021 at 14:12):During the CESM workshop this week, at the Software Engineering Working Group meeting, we had a discussion about diagnostics related to CESM! I put together a blog post summarizing discussions, as well as a word cloud from all the notes from the small group discussions. Check it out! https://ncar.github.io/esds/posts/cesm-workshop-2021-diagnostics/
pasted image
Daniel Marsh (Jun 21 2021 at 14:47):@Max Grover Thanks for the blog on creating intake-esm catalogs from CESM history files. I tried it out on a development run. It worked, but I had to move the parsing_func argument to the b.build() call. Is that correct?
Max Grover (Jun 21 2021 at 14:51):Yes! We recentuly updated the API, and included these changes within the ecgtools documentation and the ESDS ecgtools blog post.. thanks for pointing this out!
Daniel Marsh (Jun 21 2021 at 18:42):@Max Grover , Looking at the documentation, I think you are using "history file" to mean what typically we would put into the h0 history files which hold a single monthly mean. However, history files are not limited to holding one time and most of the other history files (h1, h2, ...) contain multiple time entries.
Max Grover (Jun 21 2021 at 18:45):So the defnition of "history" in this case is a file with several variables at a single time slice; whereas timeseries files are a single variable with multiple time entries. Is there a case where history files (time slice) coming out of the model has mutliple time steps?
Daniel Marsh (Jun 21 2021 at 18:51):History files (at least for the atmosphere) typically contain both multiple variables and time entries. History output here is what is specified in the fincl1, fincl2, ... entries in the namelist. The h0s are the odd case in which it is chosen to have one time entry. The script that creates timeseries pulls apart by variable and concatenates the various history files. For example if the U, V, & T fields are put out on a daily basis they may be found in one of history file outputs (h1, h2, etc.) that might each have 30 time steps.
Sheri Mickelson (Jun 21 2021 at 19:00):@Max Grover if you'd like to see an example of what @Daniel Marsh is referring to, you can look at this file
/glade/work/cmip6/cases/DECK/b.e21.BHIST.f09_g17.CMIP6-historical.011/user_nl_cam
At the top, nhtfrq indicates the time frequency of the the writes for each stream and mfilt indicates how many slices should be in each file for each stream. All of it is configurable and can change based on what the user would like.
Max Grover (Jun 21 2021 at 19:01):Ahh okay - I will take a look at this use case... what would be a better way of differentiating between timeseries and history files?
Daniel Marsh (Jun 21 2021 at 19:05):Ideally the code that creates a catalog and intake-esm would not care if a file had more than one variable or more than one time step. Is that possible? To me, a timeseries file is just a history file that has just one field in it.
Anderson Banihirwe (Jun 21 2021 at 19:16):Ideally the code that creates a catalog and intake-esm would not care if a file had more than one variable or more than one time step. Is that possible?
The short answer is yes :slight_smile:. As long as the catalog records the "variable" column appropriately, everything should work fine i.e. for files with more than one variables, the "variable" column should contain rows with a list of variables. For "time-series" files, this column should contain rows with single entry (string) referring to the variable in the "time-series" file.
Max Grover (Jun 22 2021 at 14:05):@Daniel Marsh coming back to this... would it better to state that "timeseries" files have a single variable for a series of times, whereas history files contain multiple variables in a single file and could have either a single time step or multiple, depending on the stream?
Daniel Marsh (Jun 22 2021 at 17:07):Perhaps someone who creates the timeseries files can comment, but it seems to me that timeseries files are a subset of history files. I could easily specify a history file with one variable and 100's of time entries using the CAM namelist - I think that would be the equivalent of timeseries file.
Kevin Paul (Jun 22 2021 at 18:01):@Daniel Marsh: Yes. That would be the equivalent of a timeseries. I didn't realize that the CAM namelist gave you that option. However, that would mean only outputting 1 variable, right? There is no option to generate multiple timeseries files directly from CAM, right?
Michael Levy (Jun 22 2021 at 18:06):However, that would mean only outputting 1 variable, right? There is no option to generate multiple timeseries files directly from CAM, right?
@Kevin Paul I can't speak for CAM directly, but most of the CESM components have a hard limit on the number of streams a user can write. Raising the cap would require source mods (or possibly just updating a namelist variable in some cases). E.g. POP has a Fortran parameter named max_avail_tavg_streams that is 9 by default
Kevin Paul (Jun 22 2021 at 18:06):@Michael Levy: I see. Thanks for the clarification.
Daniel Marsh (Jun 22 2021 at 18:07):Unfortunately, the number of history files is limited (about a dozen, I think) so it's not practical create all the timeseries this way. Mainly it was a terminology point - history vs timeseries (latter being a special case of the former).
Max Grover (Jun 25 2021 at 20:39):In this week's ESDS blog post , we look into using a Jupyterbook for documenting CESM model output. This builds a bit off of the past few posts, and provides an example of where Jupyterbooks can be helpful for documentation and sharing your work with others!
Julia Kent (Jun 29 2021 at 21:15):With the merge of the ESDS and Xdev blogs, all of the previous links to the Xdev blog are broken. Is there a way to make these addresses automatically forward to the new page location? I am getting lots of concerned messages from tutorial seminar series participants about it.
Max Grover (Jun 29 2021 at 21:26):@Julia Kent where are the links located? Is through email or github repos?
Max Grover (Jun 29 2021 at 21:28):Could you send an email to everyone on the list stating that the previous tutorial content can be found here?
https://ncar.github.io/esds/blog/tag/python-tutorial-series/
Anderson Banihirwe (Jun 29 2021 at 21:38):@Julia Kent,
all of the previous links to the Xdev blog are broken. Is there a way to make these addresses automatically forward to the new page location?
I set up the redirect for the top-level domain. I thought this was enough at the time. I am going to set up redirects for individual posts shortly
Anderson Banihirwe (Jun 29 2021 at 21:57):@Julia Kent, could you try those (old) links that were broken when you get a moment? They should redirect you to the corresponding links on ESDS blog... Let me know if I missed any link
Julia Kent (Jun 30 2021 at 00:02):The links are from past emails, so I can't edit them. Sending a group email is a good idea! Thanks @Max Grover
Julia Kent (Jun 30 2021 at 00:06):@Anderson Banihirwe It works now! Thanks for doing that. I also sent out an email.
Kevin Paul (Jun 30 2021 at 00:21):Thanks, @Anderson Banihirwe!
Max Grover (Jul 02 2021 at 21:34):Hi All! I had an opportunity to attend a "Scaling Python with Dask" class this week and put together a blog post detailing some of the main takeways + information helpful to the NCAR community! Feel free to check it out, and reach out if you have any questions
https://ncar.github.io/esds/posts/scaling-with-dask-class-takeaways/
Max Grover (Jul 30 2021 at 17:15):Happy Friday All!
This week, we have two ESDS blog posts, including one detailing the main takeaways from the Scientific Python (SciPy) conference, and the other a detailed overview of the Project Pythia Portal, which is a fantastic resource for getting started with Python, especially within the geosciences.
Be sure to check out these posts!
Blog Post Links
SciPy Conference 2021 Takeaways
Project Pythia Portal Overview
Also, as a reminder, Xdev will be hosting virtual office hours on Monday from 3-5 PM - details can be found on the ESDS calendar page.
Max Grover (Aug 06 2021 at 22:05):Interested in using the CESM2-Large Ensemble? Check out the latest ESDS blog post detailing how to access that dataset on GLADE using intake-esm
Max Grover (Aug 13 2021 at 21:52):Hi All! Happy Friday! I put together a post using data provided by @Stephen Yeager , using interactive visualization libraries in Python to plot CESM data on an unstructured grid. Check it out! https://ncar.github.io/esds/posts/cesm-datashader/
Max Grover (Aug 20 2021 at 22:30):This week's ESDS blog post details how to use various Python tools to plot interactive CESM diagnostic plots. We walk through everything from data access, setting up your plot, to putting together the final multi-panel visualizations.
https://ncar.github.io/esds/posts/2021/intake-esm-holoviews-diagnostics/
Have a great weekend!
Alice DuVivier (Aug 24 2021 at 15:06):Max Grover said:
Interested in using the CESM2-Large Ensemble? Check out the latest ESDS blog post detailing how to access that dataset on GLADE using intake-esm
I have been following this example and am finding today that at the "import dask" and getting a cluster going the notebook is just hanging. Any suggestions here? I've been waiting about 15 minutes and have tried restarting before that.
Michael Levy (Aug 24 2021 at 15:11):@Alice DuVivier what machine are you on? I'm having trouble running qsub from the command line on casper so I wonder if there's a PBS issue? I'm going to submit a ticket to CISL.
Has anyone else been able to launch a job on casper this morning?
Max Grover (Aug 24 2021 at 15:11):It looks like even accessing a compute node is slow this morning... looks like someone is running a large job using NCL which is using quite a few resources
Max Grover (Aug 24 2021 at 15:13):The queue is pretty full.. there are quite a few more jobs lined up. Dask is interfacing with the compute nodes, so if there are not any resources available, it won't spin up... one option is to use the LocalCluster, but that might have limited resources depending on what you requested when accessing the JupyterHub or if you are on the login node
Kristen Krumhardt (Aug 24 2021 at 15:14):I can't get a get a casper job started on jupyterhub this morning .. just keeps timing out
Michael Levy (Aug 24 2021 at 15:17):I was finally able to get qsub to run, but it took a while. I think Max is right about resources on the log-in nodes being in short supply (and the cluster being in heavy use would also add to the wait times)... I don't think it makes sense to ask CISL-help about it, so I'm not going to email them just yet
Alice DuVivier (Aug 24 2021 at 15:21):I am on casper also.
Max Grover (Aug 24 2021 at 15:35):CISL is aware of the problem
Alice DuVivier (Aug 24 2021 at 15:46):Thanks! So just hold on? My notebook is still just hanging. Should I stop it and restart my kernel or just restart the whole session?
Max Grover (Aug 24 2021 at 15:52):If you restart the whole session you might not be able to get back in... I would wait... I'd imagine they will send out a notification once this issue is resolved.
Max Grover (Aug 24 2021 at 18:43):Not sure if you all saw, but the system is back to normal
Max Grover (Aug 27 2021 at 22:19):Interested in creating a data catalog from observational datasets already on GLADE? Check out this week's blog post walking through building a catalog from the AMWG diagnostic package observational datasets, comparing against the CESM2-Large Ensemble!
https://ncar.github.io/esds/posts/2021/intake-obs-cesm2le-comparison/
Max Grover (Sep 24 2021 at 20:15):Happy Friday!
In this week's ESDS blog post, we detail how to build a model diagnostics package using the Jupyter ecosystem! This workflow produces an interactive webpage which can be shared with others, parametrizable via a configuration file which allows the flexibility to use on a variety of use cases.
Check it out using this link!
Max Grover (Oct 01 2021 at 12:17):Happy Friday!
Interested in what progress has been made related to ESDS over the past few months? We put together a blog post detailing some key highlights, including Work in Progress Talks, Xdev Office Hour statistics, and links to various Python tutorial sessions which have been taught so far!
This is definitely worth a read :grinning_face_with_smiling_eyes:
Matt Long (Oct 01 2021 at 12:21):@Max Grover, thanks for putting this together, it's really great to see!
Max Grover (Oct 08 2021 at 22:27):Happy Friday!
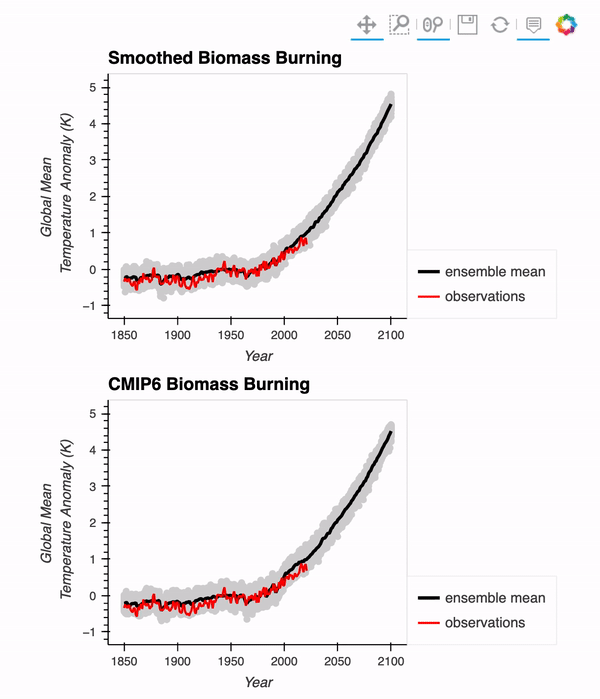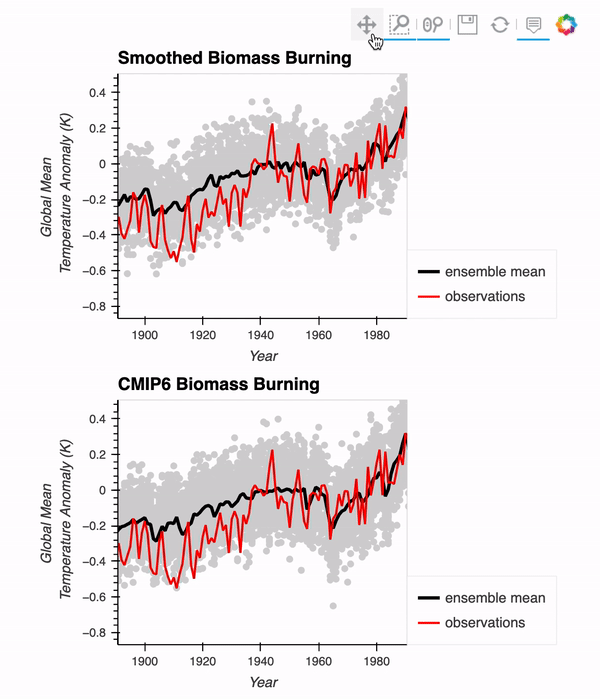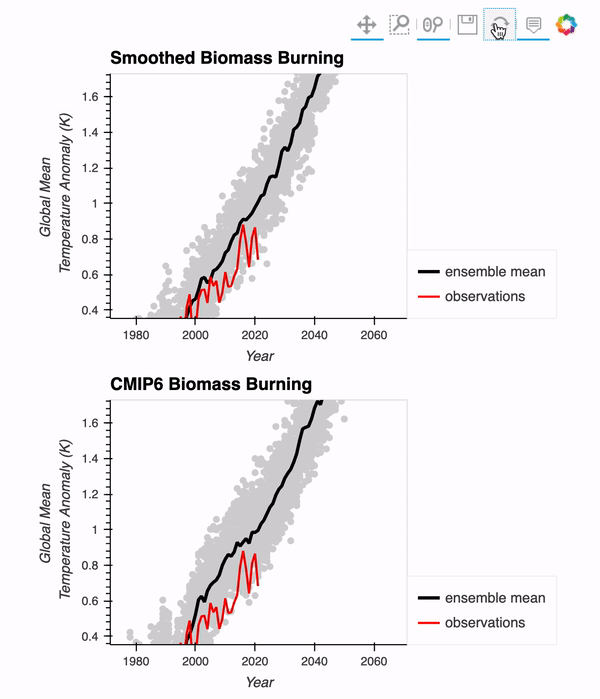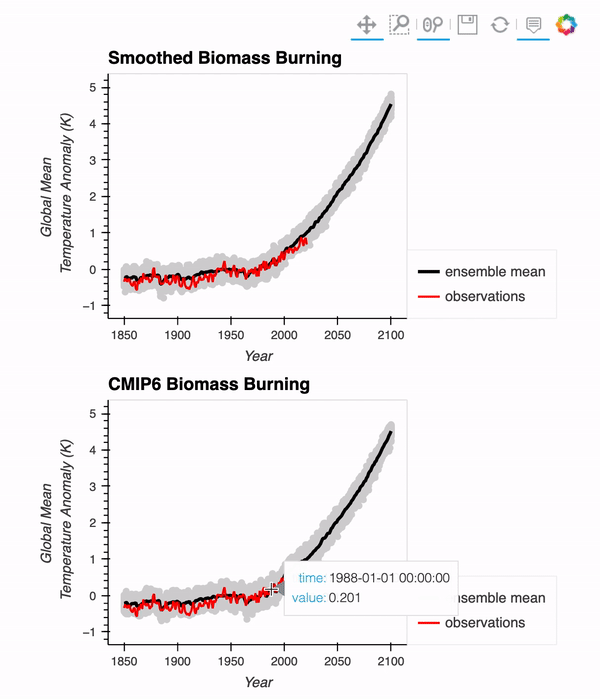
Interested in comparing the CESM2-Large Ensemble with observations? We put together a post reproducing a figure from the original LENS paper (Kay et al. 2015), using data from the CESM2-Large Ensemble! We use Intake-ESM, Dask, and hvPlot to put the final figure together!
Here is a gif of the interactive figure at the end!
kay_et_al_lens2.gif
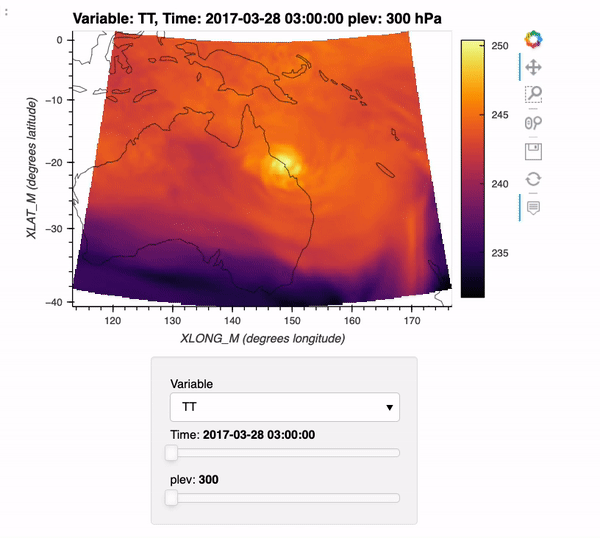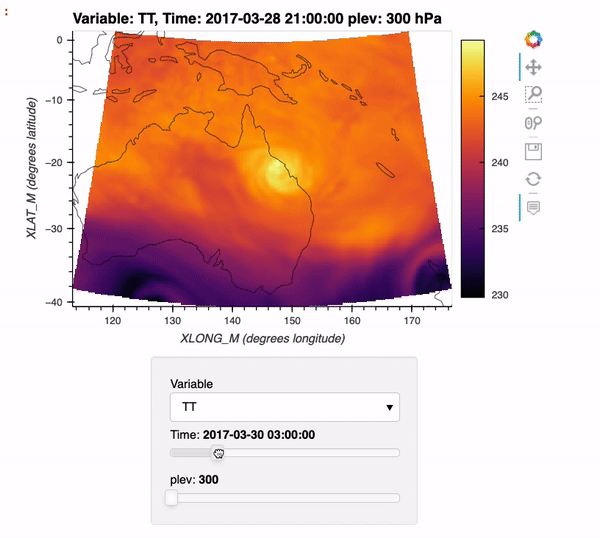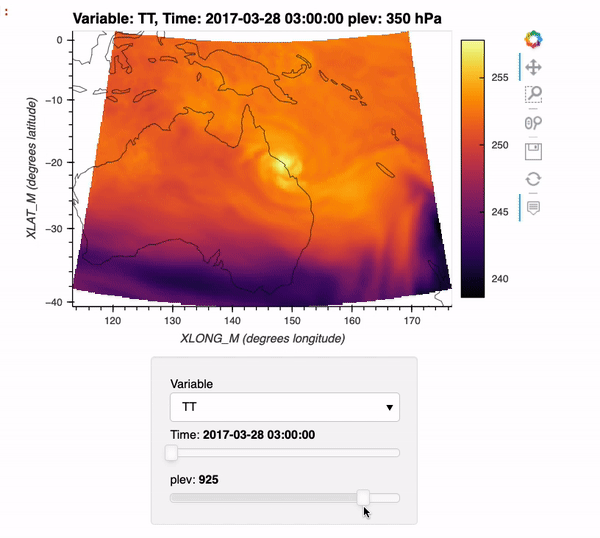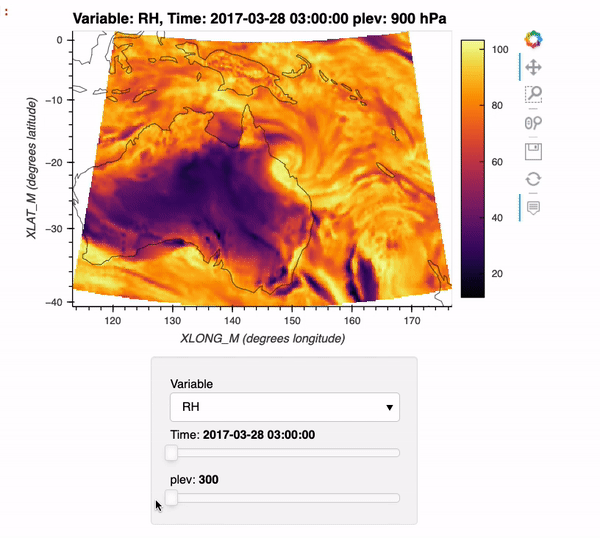
Max Grover (Oct 15 2021 at 20:48):Interested in using Xarray + Dask with WRF data? Check out this week's ESDS blog post where we cover how to use a new xarray backend, xwrf, to read in WRF data and create interactive plots of the data!
Here is a preview of what you can create using this example:
xarray_wrf_blog_post.gif
Max Grover (Oct 22 2021 at 19:06):Interested in extending your data catalog? Check out this week's ESDS blog post detailing how to add derived variables to an Intake-ESM catalog! This enables users to add additional diagnostic variables that may not be in the original dataset.
Matt Long (Oct 22 2021 at 20:04):This is great work by @Anderson Banihirwe and @Max Grover!
Deepak Cherian (Feb 24 2022 at 22:43):New blog post from @Katie Dagon and I!
An experiment with representing sparse arrays (here vegetation types from CLM) with xarray + dask. This was prompted by a Zulip conversation from a few months ago.
Katie Dagon (Feb 24 2022 at 23:07):Thanks @Deepak Cherian ! Python tools for remapping PFT-level output came up in our CLM meeting today, so this is excellent timing.
cc @Danica Lombardozzi @Will Wieder @Daniel Kennedy
Anderson Banihirwe (Feb 24 2022 at 23:08):This was prompted by a Zulip conversation from a few months ago.
Xref the relevant Zulip topic Code examples for plotting CLM Plant Functional Types
Danica Lombardozzi (Feb 24 2022 at 23:25):Thanks @Deepak Cherian and @Katie Dagon ! It's great to see this -- translating from vector to mult-dimensional grids has always been problematic and time consuming! LENS2 has numerous vector files, and I wonder if we can devise a way to handle multiple files at once to make it easier for people to work with those data
Deepak Cherian (Feb 25 2022 at 03:30):Thanks Danica. The function works with xarray Datasets, so as long as you make one using xr.open_mfdataset it should work! (assuming it has the appropriate 1D PFT variables)
Deepak Cherian (Mar 31 2022 at 16:51):Two new blogposts!
Katie Dagon (May 12 2022 at 22:14):@Julia Kent has a great new blog post on debugging, which I initially discovered via the Project Pythia twitter account :grinning:
Julia Kent (May 12 2022 at 22:19):Thanks Katie!
Deepak Cherian (Jul 28 2022 at 21:21):After attending today's great CuPy tutorial at the GPU workshop, I adapted some of that notebook to showcase integrating cupy arrays in xarray
Anderson Banihirwe (Aug 30 2022 at 22:00):@geocat, you might find this interesting given your recent work exploring GeoCAT routines on GPUs: https://xarray.dev/blog/xarray-kvikio
Anderson Banihirwe (Aug 31 2022 at 23:58):for folks interested in keeping track of physical units while using Xarray: https://xarray.dev/blog/introducing-pint-xarray
Katie Dagon (Dec 02 2022 at 21:35):New blog post from @Heather Craker on seasonal averaging using @geocat's climatology_average function. This post came out of some discussions we had during the ESDS Event a couple weeks ago.
https://ncar.github.io/esds/posts/2022/xarray-groupby-vs-geocat-climatology/
Deepak Cherian (Dec 12 2022 at 17:15):New blog post with @Christine Shields on regridding CAM-SE using xESMF + an existing ESMF weights file: https://ncar.github.io/esds/posts/2022/cam-se-regridding/
Katie Dagon (Dec 19 2022 at 18:36):New blog post recapping the ESDS Event back in November. All materials from that event (recordings, slides, notes) are linked in the post:
https://ncar.github.io/esds/posts/2022/esds-event-recap/
Deepak Cherian (Mar 09 2023 at 22:52):New blog post on generating virtual aggregate datasets for CESM MOM6 output with the kerchunk package:
https://ncar.github.io/esds/posts/2023/kerchunk-mom6/
we use kerchunk to generate a JSON file containing “references” to binary blocks stored elsewhere. The JSON file is structured to look like a Zarr dataset. Such a file can be interpreted as an aggregate Zarr dataset using fsspec and zarr.
Amongst other things, this approach allows you to open a dataset by only reading a single JSON file (and not touching 1000s of netCDF files, and not having to coerce Xarray into combining them sensibly)
Julia Kent (May 11 2023 at 19:12):New blog post for anyone hoping to help out with office hours!
https://ncar.github.io/esds/posts/2023/office-hours-help/
Deepak Cherian (May 15 2023 at 19:45):Recap of the unstructured grid collab work time event: https://ncar.github.io/esds/posts/2023/unstructured-grid-collab-1/ . It was fun!
Deepak Cherian (Jun 27 2023 at 17:10):Zarr developer blog post on recent talks about Zarr enhancements: https://zarr.dev/blog/zarr-talks/
Deepak Cherian (Jul 03 2023 at 15:28):New Xarray blogpost on "cubed", an alternative to dask: https://xarray.dev/blog/cubed-xarray
Deepak Cherian (Jul 14 2023 at 04:41):New blogpost on Pangeo-forge: https://medium.com/pangeo/pangeo-forge-is-all-in-on-apache-beam-d7370299405f
Pangeo Forge, a modular Python toolkit for reproducibile and scalable production of analysis ready cloud optimized (ARCO) ocean, weather, and climate datasets, is now all in on Apache Beam. This blog recaps the background of Pangeo Forge and its prior architecture, explains the motivations and costs of this major shift in direction, and concludes with a discussion of the opportunities presented by this change.
...
We’re so excited to start putting the 0.10.0 release to use building ARCO data for the community, and in particular building ambitious datasets that previously felt unattainable due to their scale or technical complexity, but which are now within reach due to the scalability and features of Apache Beam.
Deepak Cherian (Jul 18 2023 at 19:28):New blogpost on speeding up Xarray groupby with flox:
Significantly faster groupby calculations are now possible through a new-ish package in the Xarray/Dask/Pangeo ecosystem called flox.
Practically, this means faster climatologies, faster resampling, faster histogramming, and faster compositing of array datasets.
It also means that very very many discussions in the Pangeo community are now closed :tada: :scream: 🤯 🥳.
Katie Dagon (Aug 29 2023 at 17:43):New blog post from @Elena Romashkova recapping ESDS at SciPy 2023!
Katie Dagon (Sep 12 2023 at 23:17):New ESDS blog post on Analyzing and visualizing CAM-SE output in Python :tada:
This one was in the works for a while, inspired by the event ESDS hosted this past spring on working with unstructured grids.
BIG thanks to all who participated in those discussions, contributed code for CAM-SE analysis/viz, and reviewed the blog post. Let us know what you think / if you try out the code!
John Clyne (Sep 13 2023 at 19:12):Katie Dagon said:
New ESDS blog post on Analyzing and visualizing CAM-SE output in Python :tada:
This one was in the works for a while, inspired by the event ESDS hosted this past spring on working with unstructured grids.
BIG thanks to all who participated in those discussions, contributed code for CAM-SE analysis/viz, and reviewed the blog post. Let us know what you think / if you try out the code!
Nice work! FYI GeoCAT's Philip Chmielowiec will be giving a talk at CISL's next WIP session on the status of visualizing unstructured grids (e.g. CAM-SE) without resampling using UXarray , Tuesday, October 10, 1pm in the Mesa Lab Main Seminar Room, or virtually zoom.
Daniel Adriaansen (Sep 13 2023 at 22:49):Hi @John Clyne is there a calendar invite or formal event page for that 10 October event?
John Clyne (Sep 13 2023 at 22:58):Yes there is. Here's the calendar invite
Daniel Adriaansen (Sep 13 2023 at 23:33):Thanks John. That is the event on your calendar only, and it simply says "busy" with no other details. I tried checking the CISL calendar here: https://www2.cisl.ucar.edu/events/calendar, but I don't see anything for 10 Oct. Maybe I'll keep an eye on staff notes daily for a bit.
John Clyne (Sep 14 2023 at 02:06):Hmm. I'm not sure how to re-share the calendar invite. I'll look into it. BTW, Katie pointed out that Philip will be giving a version of this talk at the Oct 2. ESDS forum.
John Clyne (Sep 25 2023 at 22:06):Here are the meeting coordinates for this:
CISL WIP Talks
Tuesday, October 10 · 1:00 – 2:00pm
Time zone: America/Denver
Google Meet joining info
Video call link: https://meet.google.com/xxr-vqnk-pua
Or dial: (US) +1 484-416-4699 PIN: 280 807 531#
More phone numbers: https://tel.meet/xxr-vqnk-pua?pin=4128857278087
Deepak Cherian (Jan 21 2024 at 04:28):Cool post by @Negin Sobhani : https://xarray.dev/blog/cupy-tutorial
Katelyn FitzGerald (Mar 06 2024 at 19:49):We have a new ESDS blog post with a brief recap of the 2024 Annual Event and links to slides, recordings (on the new ESDS YouTube channel:tada:), and other resources!
Last updated: May 16 2025 at 17:14 UTC