
Using LocalCluster with Dask#
In Python you can utilize dask to create a cluster for parallel processing that shares resources with the system the code is running on. LocalCluster is the best way to get started using Dask. It allows time to understand the different components involved in implementing parallel computing. Python’s standard interpreter, CPython, is single threaded and only runs on a single CPU core. Your computer likely has multiple CPU cores available and tools like Dask LocalCluster can be used to take advantage of more CPU cores. By starting here you will understand when LocalCluster is no longer enough and more resources are required to scale your application or analysis. An example of how to accomplish this in your Python code can be seen below:
from dask.distributed import Client, LocalCluster
cluster = LocalCluster(
'cluster-name',
n_workers = 4
)
client = Client(cluster)
client
This will start 4 Dask workers and a scheduler on local resources. If you run this Python code on the NCAR JupyterHub instance you will see a Widget that you can expand and explore your cluster options. An example of this can be seen in the image below:
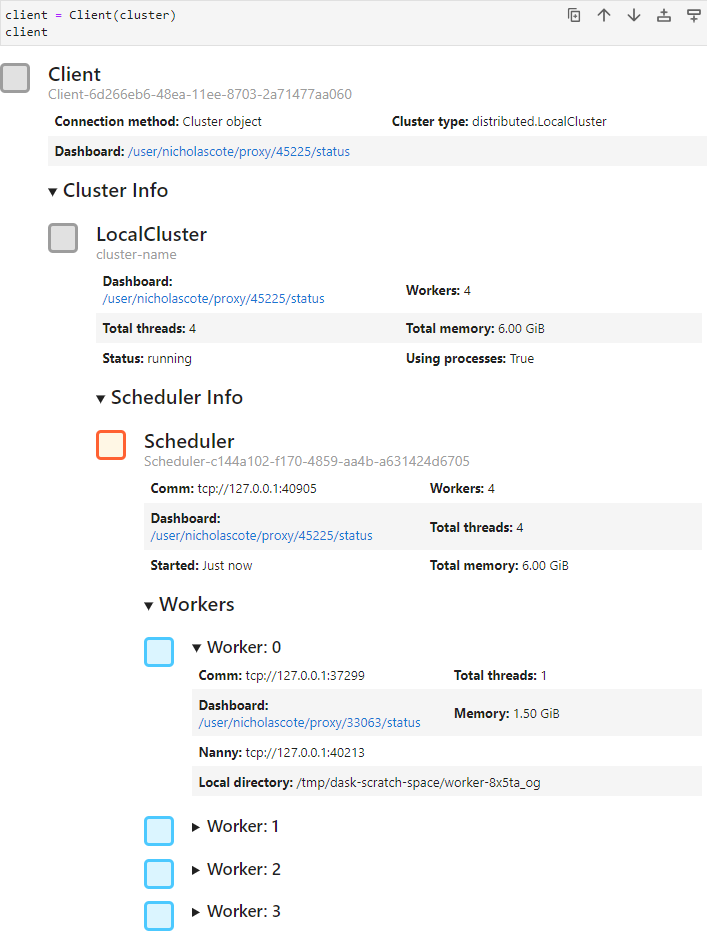
On the NCAR JupyterHub the dashboard links will take you to a Dask dashboard page. The URL can also be copied and pasted in to the Dask extension on the left as seen below.
Each box can be dragged in to your workspace and arranged as different tiles alongside your notebook. This enables you to monitor Dask resources while watching your notebooks run.