Access CESM2 data from GDEX and compute climatology average¶
# Imports
import geocat.comp as gc
import intake
import numpy as np
import pandas as pd
import xarray as xr
import re
import aiohttp
import dask
from dask_jobqueue import PBSCluster
from dask.distributed import Client
import os/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
# import fsspec.implementations.http as fshttp
# from pelicanfs.core import PelicanFileSystem, PelicanMap, OSDFFileSystem year0 = '1991'
year1 = '2020'
year0_str = str(year0)
year1_str = str(year1)
#Boulder coordinates
boulder_lat = 40.0150
boulder_lon = (360-105.2705)%360
print(boulder_lat,boulder_lon)40.015 254.7295
# Set up your sratch folder path
username = os.environ["USER"]
glade_scratch = "/glade/derecho/scratch/" + username
print(glade_scratch)
#
catalog_url = 'https://osdata.gdex.ucar.edu/d010092/catalogs/d010092-osdf.json'/glade/derecho/scratch/harshah
Spin up a cluster¶
# Create a PBS cluster object
cluster = PBSCluster(
job_name = 'dask-wk26-hpc',
cores = 1,
memory = '8GiB',
processes = 1,
local_directory = glade_scratch+'/dask/spill',
log_directory = glade_scratch + '/dask/logs/',
resource_spec = 'select=1:ncpus=1:mem=8GB',
queue = 'casper',
walltime = '5:00:00',
#interface = 'ib0'
interface = 'ext'
)/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/distributed/node.py:188: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 38601 instead
warnings.warn(
client = Client(cluster)
clientLoading...
n_workers =5
cluster.scale(n_workers)
client.wait_for_workers(n_workers = n_workers)
clusterLoading...
Load CESM2 temperature data and apply geocat-comp’s climatology average¶
osdf_catalog = intake.open_esm_datastore(catalog_url)
osdf_catalogLoading...
osdf_catalog.df['path'].head().values<ArrowExtensionArray>
[ 'osdf:///ncar-gdex/d010092/atm/daily/cesm2LE-historical-cmip6-FLNS.zarr',
'osdf:///ncar-gdex/d010092/atm/daily/cesm2LE-historical-cmip6-FLNSC.zarr',
'osdf:///ncar-gdex/d010092/atm/daily/cesm2LE-historical-cmip6-FLUT.zarr',
'osdf:///ncar-gdex/d010092/atm/daily/cesm2LE-historical-cmip6-FSNS.zarr',
'osdf:///ncar-gdex/d010092/atm/daily/cesm2LE-historical-cmip6-FSNSC.zarr']
Length: 5, dtype: large_string[pyarrow]osdf_catalog_temp = osdf_catalog.search(variable ='TREFHT', frequency ='daily',forcing_variant='cmip6')
osdf_catalog_tempLoading...
%%time
#dsets = osdf_catalog_temp.to_dataset_dict(storage_options={'anon':True})
dsets = osdf_catalog_temp.to_dataset_dict(xarray_open_kwargs={'engine':'zarr','backend_kwargs':{'consolidated': True,'zarr_format': 2}})
--> The keys in the returned dictionary of datasets are constructed as follows:
'component.experiment.frequency.forcing_variant'
Loading...
CPU times: user 554 ms, sys: 46.6 ms, total: 601 ms
Wall time: 3.55 s
%%time
dsets.keys()CPU times: user 3 μs, sys: 0 ns, total: 3 μs
Wall time: 6.44 μs
dict_keys(['atm.historical.daily.cmip6', 'atm.ssp370.daily.cmip6'])historical_cmip6 = dsets['atm.historical.daily.cmip6']
historical_cmip6 = historical_cmip6.TREFHT
historical_cmip6Loading...
To illustrate how the function works select small subset¶
Choose data between year0 and year1
Choose data from only one member
Choose data for Boulder
%%time
historical_cmip6_30years = historical_cmip6.isel(member_id=0).sel(lat =boulder_lat,lon=boulder_lon,method='nearest').\
sel(time = slice(f'{year0_str}-01-01', f'{year1_str}-12-31'))
historical_cmip6_30yearsCPU times: user 66.7 ms, sys: 5.38 ms, total: 72.1 ms
Wall time: 85 ms
Loading...
%%time
# Plot raw data
historical_cmip6_30years.plot()CPU times: user 181 ms, sys: 12.5 ms, total: 194 ms
Wall time: 6.22 s
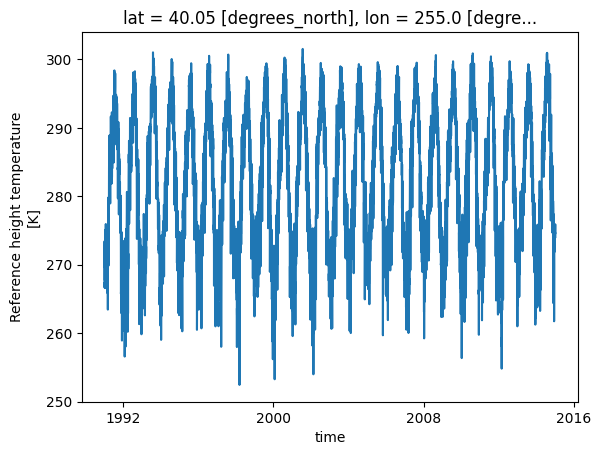
# historical_cmip6_30years.values%%time
hist_cmip6_monthly = gc.climatology_average(historical_cmip6_30years,freq='month')
hist_cmip6_monthlyCPU times: user 107 ms, sys: 6.7 ms, total: 114 ms
Wall time: 197 ms
Loading...
%%time
hist_cmip6_monthly.plot()CPU times: user 125 ms, sys: 11.2 ms, total: 137 ms
Wall time: 3.6 s
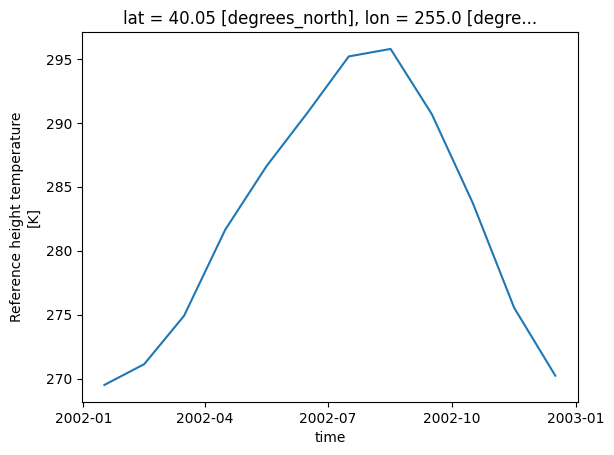
cluster.close()