Annual Maximum JJA Heat Index at Boulder, CO and Chicago, IL (1990–2005)¶
ERA5 and JRA-3Q Reanalyses from NCAR GDEX¶
Scientific motivation¶
This notebook computes the annual maximum June–July–August (JJA) heat index at two mid-latitude United States cities — Boulder, Colorado (semi-arid, elevation 1655 m) and Chicago, Illinois (humid continental, Lake Michigan influence) — using two independent global reanalyses spanning 1990–2005.
The analysis follows the methodology of Romps (2024), who demonstrated using ERA5 that the annual maximum summer heat index in Texas has increased at a rate several times larger than the contemporaneous increase in dry-bulb temperature. The physical basis for this amplification lies in the nonlinearity of the heat index with respect to temperature and humidity: at near-saturated conditions, the Clausius–Clapeyron relation implies that a given increment of warming produces a disproportionately large increase in physiological heat stress. Chicago, situated in a persistently humid air mass, is expected to exhibit stronger amplification than semi-arid Boulder, where the heat index remains close to the dry-bulb temperature throughout the summer.
Datasets¶
| Product | GDEX identifier | Temporal resolution | Quantity archived | Access format |
|---|---|---|---|---|
| ERA5 surface analysis | d633000 | Hourly instantaneous | VAR_2T, VAR_2D | Native Zarr |
JRA-3Q surface analysis (anl_surf125) | d640000 | 6-hourly instantaneous | TMP_GDS0_HTGL, RH_GDS0_HTGL | kerchunk reference |
Because ERA5 provides 24 candidate values per day versus 4 for JRA-3Q, computing the JJA season maximum from the full hourly ERA5 stream would systematically inflate ERA5 relative to JRA-3Q through a sample-size effect alone. To remove this artifact, ERA5 is subsampled to one randomly selected observation per 6-hour window prior to computing the annual maximum, matching the JRA-3Q cadence. A random draw, rather than a fixed synoptic hour, is used to avoid introducing a systematic diurnal-phase bias into the sampled ERA5 distribution. We re-sample instead of taking a mean over a 6-hour window because the average might miss an extreme heat index value in this window.
Heat index formulation¶
The heat index is computed using the heatindex Python package of Lu & Romps
(2025), which implements the extended formulation of Lu & Romps (2022) in python.
The function takes air temperature in Kelvin and relative humidity on the
interval and returns the heat index in Kelvin:
hi.heatindex(T_K, rh) → HI_KERA5 does not archive near-surface relative humidity directly. It is derived from
the 2-m temperature (VAR_2T) and 2-m dew-point temperature (VAR_2D) via the
August–Roche–Magnus approximation, consistent with the ECMWF IFS documentation.
JRA-3Q provides relative humidity in percent as RH_GDS0_HTGL in the surface
analysis product.
Required Packages¶
Please make sure to install the packages before moving forward
intake
intake-esm >= 2025.12.12
xarray
dask
zarr
kerchunk
numpy
pandas
matplotlib
heatindex >= 0.0.2
!pip install heatindexRequirement already satisfied: heatindex in /glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages (0.0.2)
Requirement already satisfied: numpy in /glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages (from heatindex) (2.4.6)
import matplotlib.pyplot as plt
import numpy as np
import os
import xarray as xr
import intake
import intake_esm
import pandas as pd
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import dask
from dask_jobqueue import PBSCluster
from dask.distributed import Clientimport zarr
zarr.config.set({"async.concurrency": 4}) # cap simultaneous range requests; drop to 2 if it still trips
<donfig.config_obj.ConfigSet at 0x145832fee150>Locate the Dataset¶
On the NCAR GDEX portal, go to the Data Access tab for the ERA5/ JRA-3Q dataset to find the intake-ESM catalogs needed to access data. In this notebook we will use GDEX OSDF catalog.
# Set up your scratch folder path - Ignore these lines if you are not on NCAR's cluster
username = os.environ["USER"]
glade_scratch = "/glade/derecho/scratch/" + username
print(glade_scratch)/glade/derecho/scratch/harshah
# OSDF based data access
era5_catalog = 'https://data.gdex.ucar.edu/d633000/catalogs/d633000-osdf.json'
jra3q_catalog = 'https://data.gdex.ucar.edu/d640000/catalogs/d640000-osdf.json'
# era5_catalog = 'https://data.gdex.ucar.edu/d633000/catalogs/d633000-https.json'
# jra3q_catalog = 'https://data.gdex.ucar.edu/d640000/catalogs/d640000-https.json'Step 2 - Set up cluster¶
Please set these two flags to False if you are not on NCAR’s HPC cluster or not using a dask gateway.
Setting these flags to False immediately selects a local cluster which can run on your personal device
USE_PBS_SCHEDULER = True # Use NCAR's HPC cluster
USE_DASK_GATEWAY = False # Create a PBS cluster object
def get_pbs_cluster():
""" Create cluster through dask_jobqueue.
"""
from dask_jobqueue import PBSCluster
cluster = PBSCluster(
job_name = 'dask-osdf-24',
cores = 1,
memory = '8GiB',
processes = 1,
local_directory = glade_scratch + '/dask/spill',
log_directory = glade_scratch + '/dask/logs/',
resource_spec = 'select=1:ncpus=1:mem=8GB',
queue = 'casper',
walltime = '3:00:00',
#interface = 'ib0'
interface = 'ext'
)
return cluster
def get_gateway_cluster():
""" Create cluster through dask_gateway
"""
from dask_gateway import Gateway
gateway = Gateway()
cluster = gateway.new_cluster()
cluster.adapt(minimum=2, maximum=4)
return cluster
def get_local_cluster():
""" Create cluster using the Jupyter server's resources
"""
from distributed import LocalCluster, performance_report
cluster = LocalCluster()
cluster.scale(5)
return cluster# Obtain dask cluster in one of three ways
if USE_PBS_SCHEDULER:
cluster = get_pbs_cluster()
elif USE_DASK_GATEWAY:
cluster = get_gateway_cluster()
else:
cluster = get_local_cluster()
# Connect to cluster
from distributed import Client
client = Client(cluster)2026-06-26 10:18:21,741 - tornado.application - ERROR - Uncaught exception GET /status/ws (127.0.0.1)
HTTPServerRequest(protocol='http', host='jupyterhub.hpc.ucar.edu', method='GET', uri='/status/ws', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/websocket.py", line 965, in _accept_connection
open_result = handler.open(*handler.open_args, **handler.open_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/web.py", line 3388, in wrapper
return method(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/bokeh/server/views/ws.py", line 149, in open
raise ProtocolError("Token is expired. Configure the app with a larger value for --session-token-expiration if necessary")
bokeh.protocol.exceptions.ProtocolError: Token is expired. Configure the app with a larger value for --session-token-expiration if necessary
2026-06-26 10:18:24,439 - tornado.application - ERROR - Uncaught exception GET /status/ws (127.0.0.1)
HTTPServerRequest(protocol='http', host='jupyterhub.hpc.ucar.edu', method='GET', uri='/status/ws', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/websocket.py", line 965, in _accept_connection
open_result = handler.open(*handler.open_args, **handler.open_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/web.py", line 3388, in wrapper
return method(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/bokeh/server/views/ws.py", line 149, in open
raise ProtocolError("Token is expired. Configure the app with a larger value for --session-token-expiration if necessary")
bokeh.protocol.exceptions.ProtocolError: Token is expired. Configure the app with a larger value for --session-token-expiration if necessary
2026-06-26 10:35:00,412 - tornado.application - ERROR - Uncaught exception GET /status/ws (127.0.0.1)
HTTPServerRequest(protocol='http', host='jupyterhub.hpc.ucar.edu', method='GET', uri='/status/ws', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/websocket.py", line 965, in _accept_connection
open_result = handler.open(*handler.open_args, **handler.open_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/web.py", line 3388, in wrapper
return method(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/bokeh/server/views/ws.py", line 149, in open
raise ProtocolError("Token is expired. Configure the app with a larger value for --session-token-expiration if necessary")
bokeh.protocol.exceptions.ProtocolError: Token is expired. Configure the app with a larger value for --session-token-expiration if necessary
2026-06-26 10:51:02,421 - tornado.application - ERROR - Uncaught exception GET /status/ws (127.0.0.1)
HTTPServerRequest(protocol='http', host='jupyterhub.hpc.ucar.edu', method='GET', uri='/status/ws', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/websocket.py", line 965, in _accept_connection
open_result = handler.open(*handler.open_args, **handler.open_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/web.py", line 3388, in wrapper
return method(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/bokeh/server/views/ws.py", line 149, in open
raise ProtocolError("Token is expired. Configure the app with a larger value for --session-token-expiration if necessary")
bokeh.protocol.exceptions.ProtocolError: Token is expired. Configure the app with a larger value for --session-token-expiration if necessary
2026-06-26 10:51:22,751 - tornado.application - ERROR - Uncaught exception GET /status/ws (127.0.0.1)
HTTPServerRequest(protocol='http', host='jupyterhub.hpc.ucar.edu', method='GET', uri='/status/ws', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/websocket.py", line 965, in _accept_connection
open_result = handler.open(*handler.open_args, **handler.open_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tornado/web.py", line 3388, in wrapper
return method(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/bokeh/server/views/ws.py", line 149, in open
raise ProtocolError("Token is expired. Configure the app with a larger value for --session-token-expiration if necessary")
bokeh.protocol.exceptions.ProtocolError: Token is expired. Configure the app with a larger value for --session-token-expiration if necessary
# Scale the cluster and display cluster dashboard URL
n_workers =3
cluster.scale(n_workers)
client.wait_for_workers(n_workers = n_workers)
clusterOpen the catalog, find and load the variable of interest¶
%%time
era5_cat = intake.open_esm_datastore(era5_catalog)
jra3q_cat = intake.open_esm_datastore(jra3q_catalog)
era5_catCPU times: user 97.8 ms, sys: 13.2 ms, total: 111 ms
Wall time: 1.48 s
# ── Time range ────────────────────────────────────────────────────────────────
YEAR_START_ERA5 = 1990
YEAR_START_JRA3Q = 1990
YEAR_END = 2005
JJA_MONTHS = [6, 7, 8]
# ── Site coordinates (degrees north, degrees east 0–360) ──────────────────────
SITES = {
"Boulder_CO" : {"lat": 40.01, "lon": 254.73},
"Chicago_IL" : {"lat": 41.88, "lon": 272.37},
}
# ── Reproducibility ───────────────────────────────────────────────────────────
RANDOM_SEED = 42Search for humidity and temperature variables in the catalog using the long_name and/or short_name columns. We only show the JRA-3Q example in the code below
jra3q_cat.df[['variable', 'short_name', 'long_name']].drop_duplicates().loc[
jra3q_cat.df['long_name'].str.contains('2m temp|humid', case=False, na=False)]# ERA5: 2-m temperature and 2-m dew-point (GDEX convention)
ERA5_T_VAR = "VAR_2T"
ERA5_TD_VAR = "VAR_2D"
era5_search = era5_cat.search(variable=[ERA5_T_VAR, ERA5_TD_VAR])
print(f"ERA5 matched: {len(era5_search.df):,} entries")
# JRA-3Q: 2-m temperature and 2-m relative humidity
# Variable names confirmed from the discovery step in the previous cell:
# tmp2m-hgt-an-ll125 → 2-metre temperature, height level, analysis
# rh2m-hgt-an-ll125 → 2-metre relative humidity, height level, analysis
JRA3Q_T_VAR = "tmp2m-hgt-an-ll125"
JRA3Q_RH_VAR = "rh2m-hgt-an-ll125"
jra3q_search = jra3q_cat.search(variable=[JRA3Q_T_VAR, JRA3Q_RH_VAR])
print(f"JRA-3Q matched: {len(jra3q_search.df):,} entries")ERA5 matched: 2 entries
JRA-3Q matched: 2 entries
#Use paths to the load the dataset
era5_t_path = era5_search.df.loc[era5_search.df['variable'] == ERA5_T_VAR, 'path'].item()
era5_td_path = era5_search.df.loc[era5_search.df['variable'] == ERA5_TD_VAR, 'path'].item()
jra3q_t_path = jra3q_search.df.loc[jra3q_search.df['variable'] == JRA3Q_T_VAR, 'path'].item()
jra3q_rh_path = jra3q_search.df.loc[jra3q_search.df['variable'] == JRA3Q_RH_VAR, 'path'].item()
print(era5_t_path)
print(era5_td_path)
print(jra3q_t_path)
print(jra3q_rh_path)osdf:///ncar/gdex/d633000/e5.oper.an.sfc.zarr/e5.oper.an.sfc.2t.zarr
osdf:///ncar/gdex/d633000/e5.oper.an.sfc.zarr/e5.oper.an.sfc.2d.zarr
https://data.gdex.ucar.edu/d640000/kerchunk/anl_surf125-remote-osdf.parq
https://data.gdex.ucar.edu/d640000/kerchunk/anl_surf125-remote-osdf.parq
%%time
era5_2t = xr.open_zarr("osdf:///ncar/gdex/d633000/e5.oper.an.sfc.zarr/e5.oper.an.sfc.2t.zarr")
era5_2d = xr.open_zarr("osdf:///ncar/gdex/d633000/e5.oper.an.sfc.zarr/e5.oper.an.sfc.2d.zarr")
era5_dsets = xr.merge([era5_2t[[ERA5_T_VAR]], era5_2d[[ERA5_TD_VAR]]]) # VAR_2T, VAR_2D only
era5_dsets/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
CPU times: user 2.74 s, sys: 370 ms, total: 3.11 s
Wall time: 9.47 s
%%time
# Read JRA-3Q over OSDF / PelicanFS, but DIRECT FROM ORIGIN (direct_reads=True),
# bypassing the OSDF cache layer. A cache node in the rotation serves corrupted
# bytes for some d640000 chunks — deterministic zlib "incorrect header check"
# from Casper — while the origin copy is clean (verified: the same chunks decode
# over direct reads and over plain HTTPS). direct_reads keeps the osdf:// /
# PelicanFS streaming path while routing around the faulty cache.
jra3q_dsets = xr.open_dataset("https://data.gdex.ucar.edu/d640000/kerchunk/anl_surf125-remote-osdf.parq",
engine="kerchunk",storage_options={"remote_protocol": "osdf", "remote_options": {"direct_reads": True}},)[[JRA3Q_T_VAR, JRA3Q_RH_VAR]]
jra3q_dsetsCPU times: user 451 ms, sys: 51.5 ms, total: 502 ms
Wall time: 2.12 s
Extract data¶
Resample ERA5 data to 6hr frequency
Subset the data in space (Colorado and Chicago) and time
import dask
def load_jra_point(ds, lat, lon, retries=8):
"""Read a JRA-3Q point time series as TRUE in-memory NumPy.
The kerchunk reference exposes the archive as a per-timestep-chunked
(dask) store. On this stack `.load()`/`.compute()` return *lazy* dask
arrays that re-read the store later — and with a distributed Client active
those reads run on the workers, where the notebook-process
async.concurrency throttle does NOT apply, so the OSDF cache truncates
responses under the fan-out. To read it reliably we:
* apply the point + JJA selection, then
* force the read IN-PROCESS via the synchronous scheduler (so the zarr
async.concurrency cap actually limits simultaneous range requests), and
* pull `.values` (true NumPy) rather than `.load()` (lazy dask),
retrying the transient OSDF truncation. Returns a small, fully in-memory
Dataset that needs no further store access.
"""
sub = (ds.sel(time=slice(str(YEAR_START_JRA3Q), str(YEAR_END)))
.sel(lat=lat, lon=lon, method="nearest"))
sub = sub.sel(time=sub.time.dt.month.isin(JJA_MONTHS)) # JJA only -> fewer reads
for attempt in range(1, retries + 1):
try:
with dask.config.set(scheduler="synchronous"):
return xr.Dataset(
{v: ("time", np.asarray(sub[v].values))
for v in (JRA3Q_T_VAR, JRA3Q_RH_VAR)},
coords={"time": sub["time"].values,
"lat": float(sub["lat"]), "lon": float(sub["lon"])},
)
except Exception as exc:
if attempt == retries:
raise
print(f" JRA-3Q read attempt {attempt}/{retries} failed "
f"({type(exc).__name__}); retrying ...")
# Subset to analysis period and JJA
era5_points = {}
jra3q_points = {}
for site, coords in SITES.items():
lat, lon = coords["lat"], coords["lon"]
# ERA5: Zarr-backed and reliable; keep it lazy (JJA filter + point), compute later
era5_pt = era5_dsets.sel(time=slice(str(YEAR_START_ERA5), str(YEAR_END)))
era5_pt = era5_pt.sel(time=era5_pt.time.dt.month.isin(JJA_MONTHS))
era5_pt = era5_pt.sel(latitude=lat, longitude=lon, method="nearest")
# JRA-3Q: read the JJA point series into NumPy once (in-process, throttled, retried)
print(f"Loading JRA-3Q / {site} into memory ...")
jra3q_pt = load_jra_point(jra3q_dsets, lat, lon)
print(f"ERA5 / {site}: requested ({lat:.2f}°N, {lon:.2f}°E) → "
f"nearest ({float(era5_pt.latitude):.3f}°N, {float(era5_pt.longitude):.3f}°E)")
print(f"JRA-3Q / {site}: requested ({lat:.2f}°N, {lon:.2f}°E) → "
f"nearest ({float(jra3q_pt.lat):.3f}°N, {float(jra3q_pt.lon):.3f}°E)")
era5_points[site] = era5_pt
jra3q_points[site] = jra3q_ptLoading JRA-3Q / Boulder_CO into memory ...
ERA5 / Boulder_CO: requested (40.01°N, 254.73°E) → nearest (40.000°N, 254.750°E)
JRA-3Q / Boulder_CO: requested (40.01°N, 254.73°E) → nearest (40.000°N, 255.000°E)
Loading JRA-3Q / Chicago_IL into memory ...
ERA5 / Chicago_IL: requested (41.88°N, 272.37°E) → nearest (42.000°N, 272.250°E)
JRA-3Q / Chicago_IL: requested (41.88°N, 272.37°E) → nearest (42.500°N, 272.500°E)
# Randomly subsample ERA5 to one observation per 6-hour window
# to match the JRA-3Q temporal cadence prior to computing the annual maximum
def subsample_6h_random(ds, seed=RANDOM_SEED):
"""
Retain one randomly selected observation per 6-hour window.
The selection mask is built from the time coordinate only,
leaving data variables Dask-lazy.
"""
times = pd.DatetimeIndex(ds["time"].values)
window_start = times.floor("6h")
unique_wins = np.unique(window_start)
rng = np.random.default_rng(seed)
offsets_h = rng.integers(0, 6, size=len(unique_wins)).astype(int)
win_to_offset = dict(zip(unique_wins, offsets_h))
pos_h = ((times - window_start).total_seconds() / 3600).astype(int)
keep = np.fromiter(
(pos_h[i] == win_to_offset[window_start[i]] for i in range(len(times))),
dtype=bool,
count=len(times),
)
print(f" {ds.sizes['time']:,} → {keep.sum():,} time steps retained "
f"({keep.sum() / len(times) * 100:.1f}%, expected ≈16.7%)")
return ds.isel(time=keep)
for site in SITES:
era5_points[site] = subsample_6h_random(era5_points[site])
print(f"ERA5 / {site}: subsampling complete") 35,328 → 5,888 time steps retained (16.7%, expected ≈16.7%)
ERA5 / Boulder_CO: subsampling complete
35,328 → 5,888 time steps retained (16.7%, expected ≈16.7%)
ERA5 / Chicago_IL: subsampling complete
# Derive relative humidity from ERA5 2-m temperature and dew-point temperature.
# Following Romps (2024, supplementary section 1.5), relative humidity is computed
# as the ratio of the saturation vapor pressure evaluated at the dew-point temperature
# to that evaluated at the air temperature. The saturation vapor pressure is
# approximated using the August-Roche-Magnus formula (Alduchov and Eskridge, 1996).
#
# Alduchov, O.A. and Eskridge, R.E., 1996. Improved Magnus form approximation of
# saturation vapor pressure. Journal of Applied Meteorology and Climatology, 35(4),
# pp.601-609. DOI: 10.1175/1520-0450(1996)035<0601:IMFAOS>2.0.CO;2
#
# JRA-3Q provides relative humidity directly in %; convert to [0, 1].
def rh_from_T_Td(T_K, Td_K):
a, b = 17.625, 243.04
T_C = T_K - 273.15
Td_C = Td_K - 273.15
rh = np.exp(a * Td_C / (b + Td_C)) / np.exp(a * T_C / (b + T_C))
return rh.clip(0.0, 1.0)
for site in SITES:
era5_points[site] = era5_points[site].assign(
rh=rh_from_T_Td(era5_points[site][ERA5_T_VAR],era5_points[site][ERA5_TD_VAR]))
jra3q_points[site] = jra3q_points[site].assign(rh=(jra3q_points[site][JRA3Q_RH_VAR] / 100.0).clip(0.0, 1.0))
print("Relative humidity prepared for all sites.")Relative humidity prepared for all sites.
Data Analysis¶
%%time
from heatindex import heatindex
def compute_heatindex_xr(T_K, rh):
hi_K = xr.apply_ufunc(
heatindex, T_K, rh,
dask="parallelized",
output_dtypes=[float],
)
hi_K.attrs = {"units": "K", "long_name": "Heat Index (Lu and Romps, 2022)"}
return hi_K
results = {}
# ── ERA5 first — stable Zarr-backed Dask computation ─────────────────────────
for site in SITES:
results[site] = {}
ds = era5_points[site]
T_K = ds[ERA5_T_VAR]
rh = ds["rh"]
hi_K = compute_heatindex_xr(T_K, rh)
ann_max = hi_K.groupby("time.year").max(dim="time")
print(f"Computing ERA5 / {site} ...")
results[site]["ERA5"] = (ann_max - 273.15).compute()
print(f" Done. Years: {int(results[site]['ERA5'].year[0])}–"
f"{int(results[site]['ERA5'].year[-1])}")
print("ERA5 complete. Starting JRA-3Q ...")
# ── JRA-3Q — load point data into memory and process locally ─────────────────
for site in SITES:
ds = jra3q_points[site] # already in memory as NumPy (load_jra_point)
T_K = ds[JRA3Q_T_VAR]
rh = ds["rh"]
hi_K = xr.apply_ufunc(heatindex, T_K, rh, output_dtypes=[float])
ann_max = hi_K.groupby("time.year").max(dim="time")
print(f"Computing JRA-3Q / {site} ...")
results[site]["JRA-3Q"] = (ann_max - 273.15)
print(f" Done. Years: {int(results[site]['JRA-3Q'].year[0])}–"
f"{int(results[site]['JRA-3Q'].year[-1])}")Computing ERA5 / Boulder_CO ...
/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/distributed/client.py:3363: UserWarning: Sending large graph of size 14.76 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
Done. Years: 1990–2005
Computing ERA5 / Chicago_IL ...
/glade/u/home/harshah/.conda/envs/osdf/lib/python3.11/site-packages/distributed/client.py:3363: UserWarning: Sending large graph of size 14.76 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
Done. Years: 1990–2005
ERA5 complete. Starting JRA-3Q ...
Computing JRA-3Q / Boulder_CO ...
Done. Years: 1990–2005
Computing JRA-3Q / Chicago_IL ...
Done. Years: 1990–2005
CPU times: user 36.5 s, sys: 1.82 s, total: 38.4 s
Wall time: 2min 32s
results{'Boulder_CO': {'ERA5': <xarray.DataArray 'VAR_2T' (year: 16)> Size: 128B
array([30.31437118, 29.37980066, 30.16152357, 28.83467811, 29.26095098,
29.52726534, 29.01216692, 28.71528863, 29.81360704, 28.70810495,
28.74855309, 28.44405876, 30.25122393, 30.32078968, 28.86774954,
31.27154208])
Coordinates:
* year (year) int64 128B 1990 1991 1992 1993 ... 2002 2003 2004 2005
latitude float64 8B 40.0
longitude float64 8B 254.8
Attributes:
units: K
long_name: Heat Index (Lu and Romps, 2022),
'JRA-3Q': <xarray.DataArray 'tmp2m-hgt-an-ll125' (year: 16)> Size: 128B
array([31.4855916 , 28.81282681, 30.29212844, 28.59815461, 32.24661062,
31.68685696, 30.37146765, 29.93243945, 31.29662387, 31.14809228,
30.77979553, 29.67094706, 32.12703736, 31.94868504, 30.1000814 ,
31.80103818])
Coordinates:
* year (year) int64 128B 1990 1991 1992 1993 1994 ... 2002 2003 2004 2005
lat float64 8B 40.0
lon float64 8B 255.0},
'Chicago_IL': {'ERA5': <xarray.DataArray 'VAR_2T' (year: 16)> Size: 128B
array([40.81386318, 37.23952255, 36.54530183, 37.43253038, 36.23931439,
47.78195681, 37.07372576, 43.51830227, 37.92607486, 42.95852188,
34.48469987, 38.67871986, 38.97232824, 37.93252271, 33.40900486,
41.54673062])
Coordinates:
* year (year) int64 128B 1990 1991 1992 1993 ... 2002 2003 2004 2005
latitude float64 8B 42.0
longitude float64 8B 272.2
Attributes:
units: K
long_name: Heat Index (Lu and Romps, 2022),
'JRA-3Q': <xarray.DataArray 'tmp2m-hgt-an-ll125' (year: 16)> Size: 128B
array([31.77173653, 32.13740182, 28.5423206 , 30.50860181, 27.81349282,
33.17215482, 30.23272175, 30.19124475, 30.94414974, 35.88272937,
29.87920044, 32.24332376, 32.28697817, 34.02234904, 27.73460363,
34.579493 ])
Coordinates:
* year (year) int64 128B 1990 1991 1992 1993 1994 ... 2002 2003 2004 2005
lat float64 8B 42.5
lon float64 8B 272.5}}%%time
fig, ax = plt.subplots(figsize=(10, 5))
colors = {"Boulder_CO": "tab:blue", "Chicago_IL": "tab:red"}
ls = {"ERA5": "-", "JRA-3Q": "--"}
for site in SITES:
for label, da in results[site].items():
ax.plot(
da.year,
da.values,
color = colors[site],
linestyle = ls[label],
linewidth = 1.5,
label = f"{site.replace('_', ', ')} — {label}",
)
ax.set_xlabel("Year")
ax.set_ylabel("Annual maximum JJA heat index (°C)")
ax.set_title("Annual Maximum JJA Heat Index\nBoulder, CO and Chicago, IL (1990–2005)")
ax.legend(framealpha=0.9)
ax.grid(linestyle=":", alpha=0.5)
plt.tight_layout()
plt.show()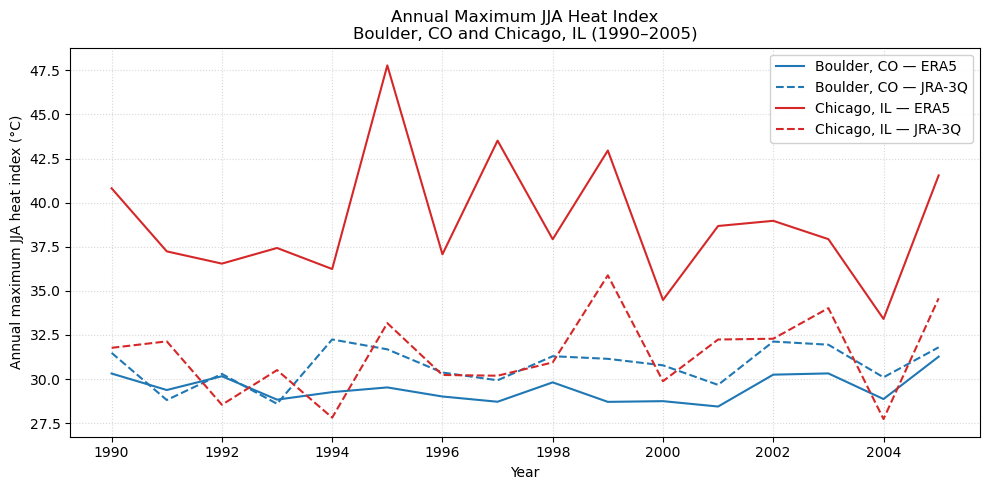
CPU times: user 171 ms, sys: 16.3 ms, total: 187 ms
Wall time: 298 ms
The plot confirms our intuition: Chicago, a more humid place, has a higher JJA maximum heat index than Boulder
We see the infamous 1995 Chicago Heat Wave in the plot, but it is not captured by JRA-3Q!
For both Chicago and Boulder, the predictions from both the ERA5 and JRA-3Q reanalyses seem to broadly agree!
# Close the cluster
cluster.close()References¶
Romps, D.M., 2024. Heat index extremes increasing several times faster than the air temperature, ERL, 2024 Environmental Research Letters
Lu, Y.-C. and Romps, D.M., 2022. Extending the heat index. Journal of Applied Meteorology and Climatology, 61(10), 1367–1383. DOI: Lu & Romps (2022)
Lu, Y.-C. and Romps, D.M., 2025.
heatindex: Tools for Calculating Heat Stress, version 0.0.2. https://heatindex .org Hersbach, H., et al., 2020. The ERA5 global reanalysis. Quarterly Journal of the Royal Meteorological Society, 146(730), 1999–2049. DOI: Hersbach et al. (2020)
Kosaka, Y., et al., 2024. The JRA-3Q Reanalysis. Journal of the Meteorological Society of Japan, 102, 49–109. DOI: KOSAKA et al. (2024)
- Lu, Y.-C., & Romps, D. M. (2022). Extending the Heat Index. Journal of Applied Meteorology and Climatology, 61(10), 1367–1383. 10.1175/jamc-d-22-0021.1
- Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz‐Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., … Thépaut, J. (2020). The ERA5 global reanalysis. Quarterly Journal of the Royal Meteorological Society, 146(730), 1999–2049. 10.1002/qj.3803
- KOSAKA, Y., KOBAYASHI, S., HARADA, Y., KOBAYASHI, C., NAOE, H., YOSHIMOTO, K., HARADA, M., GOTO, N., CHIBA, J., MIYAOKA, K., SEKIGUCHI, R., DEUSHI, M., KAMAHORI, H., NAKAEGAWA, T., TANAKA, T. Y., TOKUHIRO, T., SATO, Y., MATSUSHITA, Y., & ONOGI, K. (2024). The JRA-3Q Reanalysis. Journal of the Meteorological Society of Japan. Ser. II, 102(1), 49–109. 10.2151/jmsj.2024-004